🚀 文檔理解模型(在DocLayNet基礎數據集上按段落級別微調LiLT基礎模型)
本模型是基於 nielsr/lilt-xlm-roberta-base 模型,使用 DocLayNet基礎數據集 進行微調得到的。該模型在評估集上取得了以下成果:
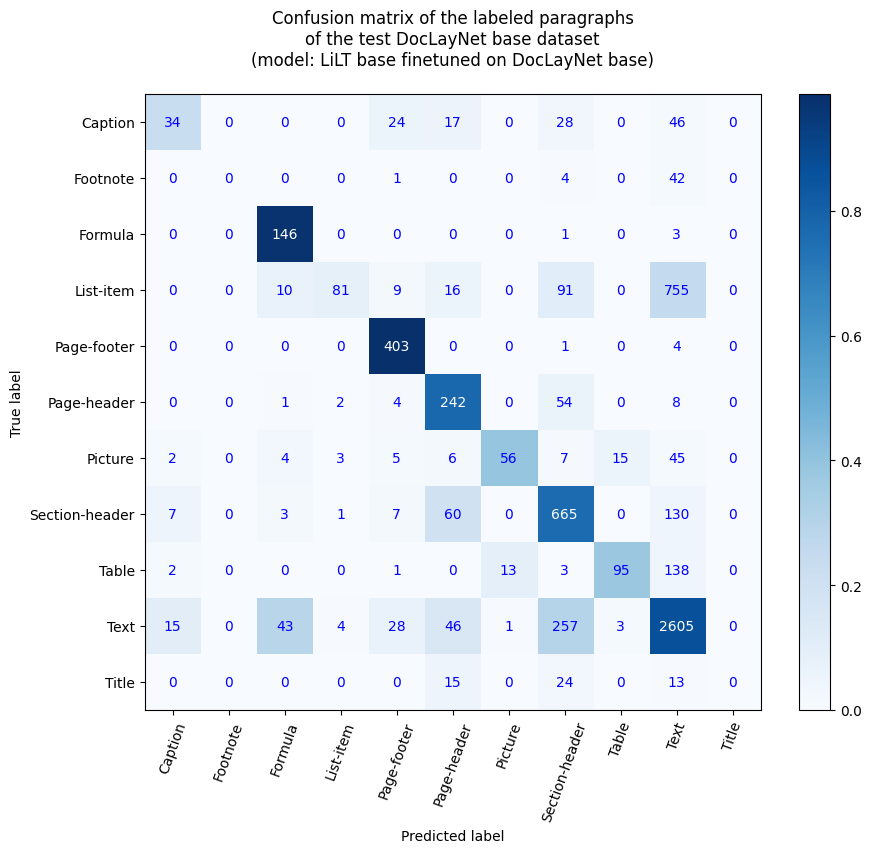
- 損失值:0.4104
- 精確率:0.8634
- 召回率:0.8634
- F1值:0.8634
- 標記準確率:0.8634
- 段落準確率:0.6815
✨ 主要特性
- 多語言支持:支持多種語言,包括英語、德語、法語和日語等。
- 多任務能力:可用於目標檢測、圖像分割和標記分類等任務。
- 基於大規模數據集訓練:使用DocLayNet基礎數據集進行訓練,該數據集包含來自多種文檔類別的大量頁面。
- 高精度表現:在評估集上取得了較高的F1值和準確率。
📚 詳細文檔
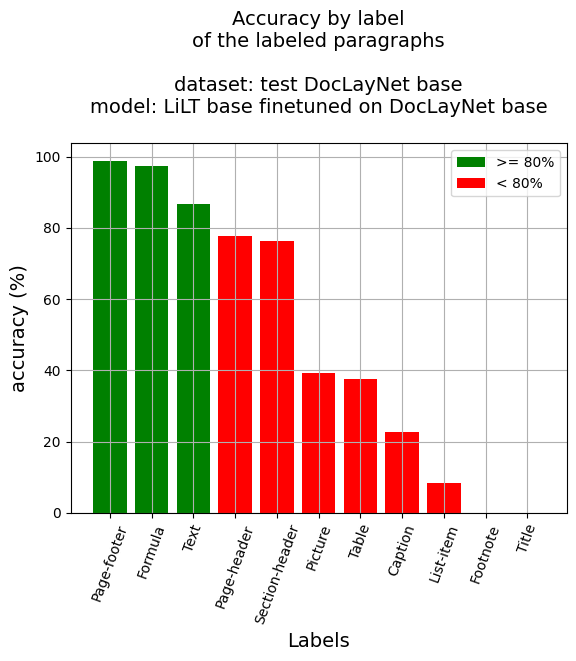
段落級準確率
- 段落準確率:68.15%
- 按標籤劃分的準確率
- 標題說明:22.82%
- 腳註:0.0%
- 公式:97.33%
- 列表項:8.42%
- 頁面頁腳:98.77%
- 頁面頁眉:77.81%
- 圖片:39.16%
- 章節標題:76.17%
- 表格:37.7%
- 文本:86.78%
- 標題:0.0%
參考文獻
博客文章
筆記本(段落級別)
筆記本(行級別)
應用程序
您可以使用Hugging Face Spaces中的此應用程序測試該模型:按段落級別進行文檔理解的推理應用程序(v1)。
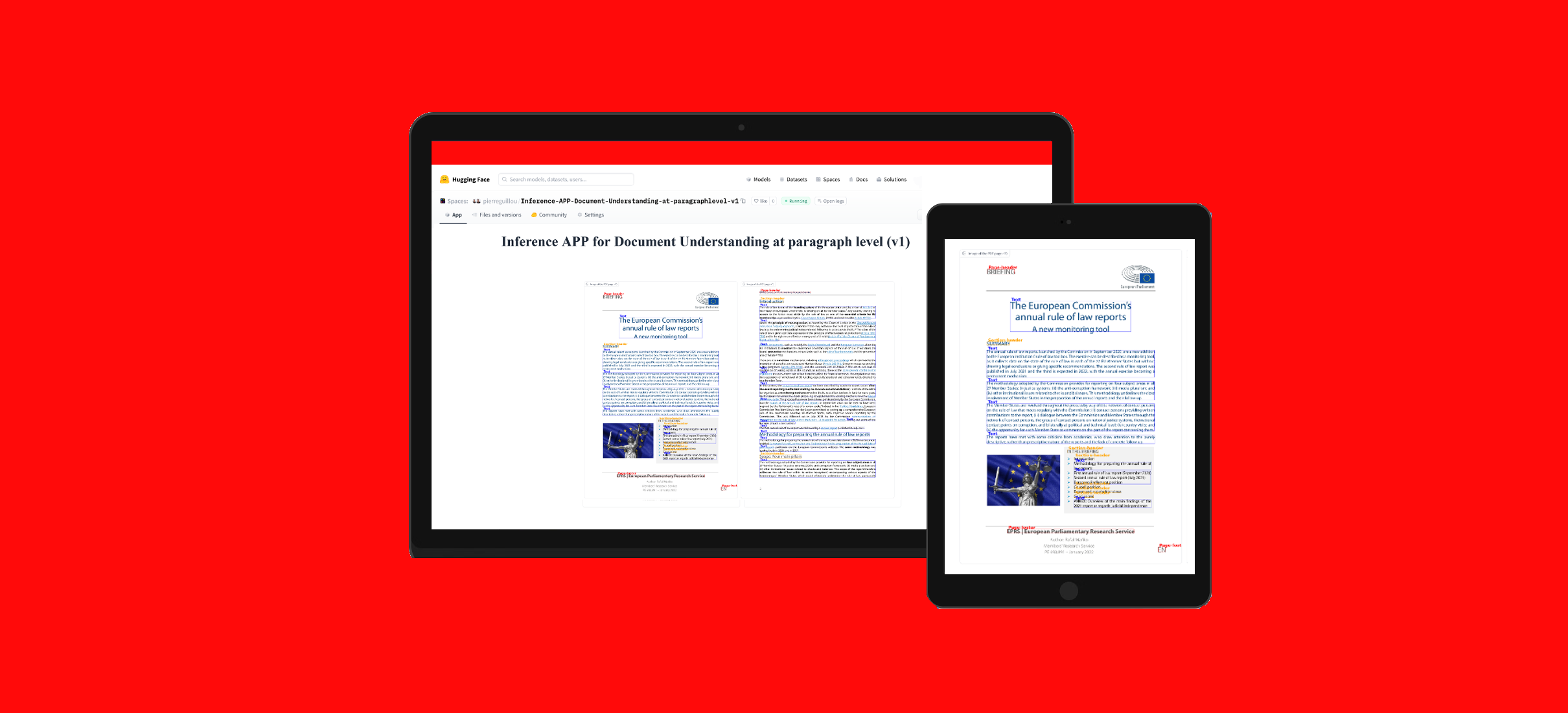
您也可以運行相應的筆記本:Document AI | 使用按段落級別微調的文檔理解模型(在DocLayNet數據集上微調的LiLT模型)進行推理的應用程序
DocLayNet數據集
DocLayNet數據集(IBM)為來自6個文檔類別的80863個唯一頁面,使用邊界框按頁面提供了11個不同類別標籤的佈局分割真實標註。
截至目前,該數據集可以通過直接鏈接或作為Hugging Face數據集進行下載:
論文:DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis(2022年6月2日)
模型描述
該模型是在 512個標記塊(重疊128個標記)的段落級別上進行微調的。因此,該模型使用了數據集中所有頁面的所有佈局和文本數據進行訓練。
在推理時,通過計算最佳概率為每個段落邊界框分配標籤。
推理
請參閱筆記本:Document AI | 使用按段落級別微調的文檔理解模型(在DocLayNet數據集上微調的LiLT模型)進行推理
訓練和評估數據
請參閱筆記本:Document AI | 在任何語言下按段落級別(512個標記塊,有重疊)在DocLayNet基礎數據集上微調LiLT
訓練過程
訓練超參數
訓練期間使用了以下超參數:
- 學習率:2e-05
- 訓練批次大小:8
- 評估批次大小:16
- 隨機種子:42
- 優化器:Adam,β=(0.9, 0.999),ε=1e-08
- 學習率調度器類型:線性
- 訓練輪數:1
- 混合精度訓練:原生自動混合精度(Native AMP)
訓練結果
| 訓練損失 |
輪數 |
步數 |
驗證損失 |
精確率 |
召回率 |
F1值 |
準確率 |
| 無記錄 |
0.05 |
100 |
0.9875 |
0.6585 |
0.6585 |
0.6585 |
0.6585 |
| 無記錄 |
0.11 |
200 |
0.7886 |
0.7551 |
0.7551 |
0.7551 |
0.7551 |
| 無記錄 |
0.16 |
300 |
0.5894 |
0.8248 |
0.8248 |
0.8248 |
0.8248 |
| 無記錄 |
0.21 |
400 |
0.4794 |
0.8396 |
0.8396 |
0.8396 |
0.8396 |
| 0.7446 |
0.27 |
500 |
0.3993 |
0.8703 |
0.8703 |
0.8703 |
0.8703 |
| 0.7446 |
0.32 |
600 |
0.3631 |
0.8857 |
0.8857 |
0.8857 |
0.8857 |
| 0.7446 |
0.37 |
700 |
0.4096 |
0.8630 |
0.8630 |
0.8630 |
0.8630 |
| 0.7446 |
0.43 |
800 |
0.4492 |
0.8528 |
0.8528 |
0.8528 |
0.8528 |
| 0.7446 |
0.48 |
900 |
0.3839 |
0.8834 |
0.8834 |
0.8834 |
0.8834 |
| 0.4464 |
0.53 |
1000 |
0.4365 |
0.8498 |
0.8498 |
0.8498 |
0.8498 |
| 0.4464 |
0.59 |
1100 |
0.3616 |
0.8812 |
0.8812 |
0.8812 |
0.8812 |
| 0.4464 |
0.64 |
1200 |
0.3949 |
0.8796 |
0.8796 |
0.8796 |
0.8796 |
| 0.4464 |
0.69 |
1300 |
0.4184 |
0.8613 |
0.8613 |
0.8613 |
0.8613 |
| 0.4464 |
0.75 |
1400 |
0.4130 |
0.8743 |
0.8743 |
0.8743 |
0.8743 |
| 0.3672 |
0.8 |
1500 |
0.4535 |
0.8289 |
0.8289 |
0.8289 |
0.8289 |
| 0.3672 |
0.85 |
1600 |
0.3681 |
0.8713 |
0.8713 |
0.8713 |
0.8713 |
| 0.3672 |
0.91 |
1700 |
0.3446 |
0.8857 |
0.8857 |
0.8857 |
0.8857 |
| 0.3672 |
0.96 |
1800 |
0.4104 |
0.8634 |
0.8634 |
0.8634 |
0.8634 |
框架版本
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
其他模型
📄 許可證
本項目採用MIT許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言