%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 ドキュメント理解モデル (DocLayNet base の段落レベルでファインチューニングされた LayoutXLM base)
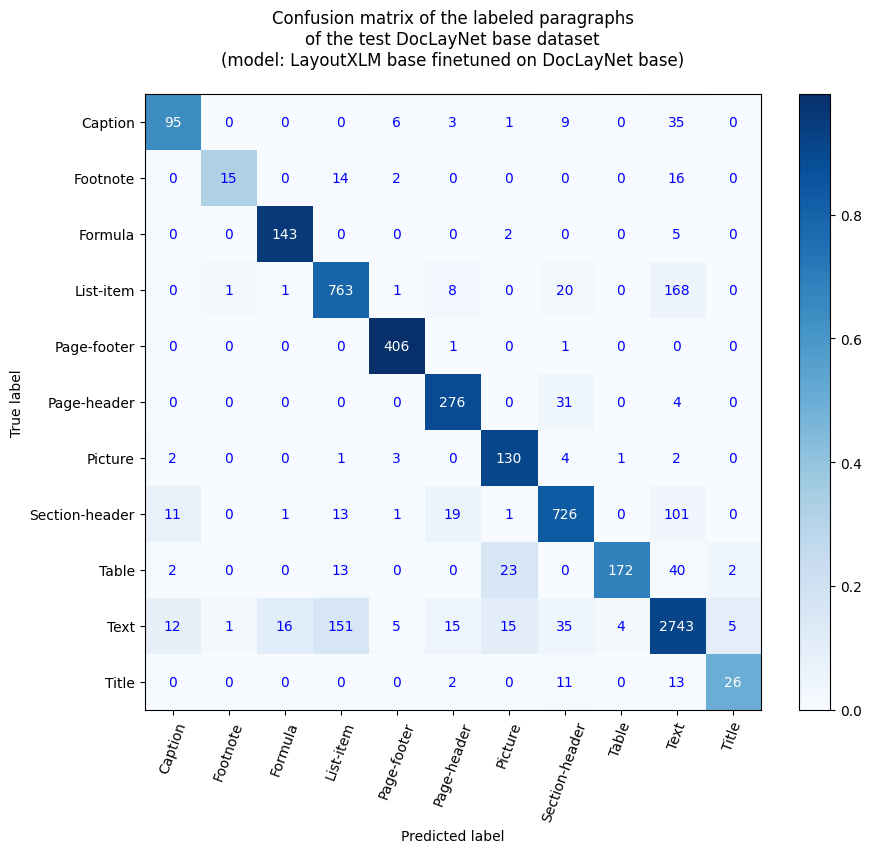
このモデルは、microsoft/layoutxlm-base を DocLayNet base データセットでファインチューニングしたバージョンです。 評価セットでは、以下の結果を達成しています。
- 損失: 0.1796
- 精度: 0.8062
- 再現率: 0.7441
- F1: 0.7739
- トークン精度: 0.9693
- 段落精度: 0.8655
✨ 主な機能
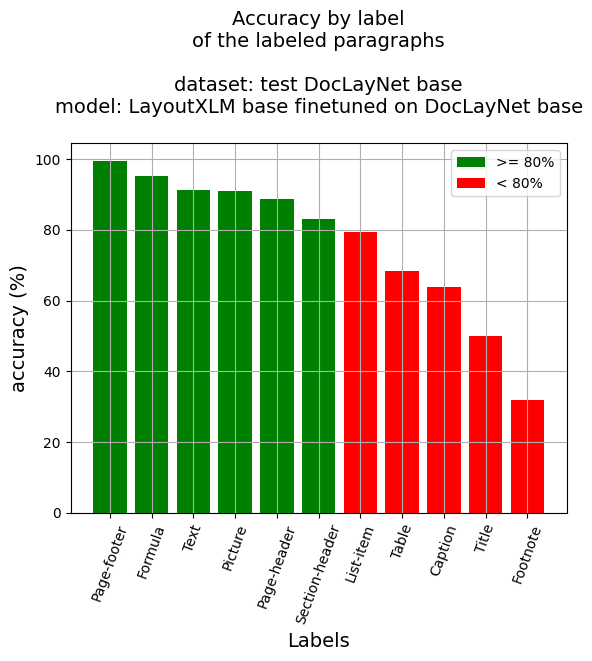
段落レベルの精度
- 段落精度: 86.55%
- ラベル別の精度
- キャプション: 63.76%
- 脚注: 31.91%
- 数式: 95.33%
- リスト項目: 79.31%
- ページフッター: 99.51%
- ページヘッダー: 88.75%
- 画像: 90.91%
- セクションヘッダー: 83.16%
- 表: 68.25%
- テキスト: 91.37%
- タイトル: 50.0%
📚 詳細ドキュメント
参考記事
- Layout XLM base
- (2023年3月31日) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level with LayoutXLM base
- (2023年3月25日) Document AI | APP to compare the Document Understanding LiLT and LayoutXLM (base) models at line level
- (2023年3月5日) Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base
- LiLT base - (2023年2月16日) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level - (2023年2月14日) Document AI | Inference APP for Document Understanding at line level - (2023年2月10日) Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset - (2023年1月31日) Document AI | DocLayNet image viewer APP - (2023年1月27日) Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
ノートブック (段落レベル)
- Layout XLM base
- Document AI | Inference at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
- LiLT base
- Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
ノートブック (行レベル)
- Layout XLM base
- Document AI | Inference APP at line level with 2 Document Understanding models (LiLT and LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- LiLT base
- Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- DocLayNet image viewer APP
- Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
APP
このモデルは、Hugging Face Spaces のこのアプリでテストできます: Inference APP for Document Understanding at paragraph level (v2)。
また、対応するノートブックも実行できます: Document AI | Inference APP at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
DocLayNet データセット
DocLayNet データセット (IBM) は、6つのドキュメントカテゴリの80863ページのユニークなページに対して、11の異なるクラスラベルのバウンディングボックスを使用したページ単位のレイアウトセグメンテーションの正解データを提供します。
現在、このデータセットは、直接リンクまたはHugging Faceのデータセットライブラリからダウンロードできます。
- 直接リンク: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face データセットライブラリ: dataset DocLayNet
論文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (2022年6月2日)
モデルの説明
このモデルは、512トークンのチャンクで、128トークンのオーバーラップを持つ段落レベルでファインチューニングされています。したがって、モデルはデータセットのすべてのページのレイアウトとテキストデータを使用してトレーニングされています。
推論時には、最適な確率の計算により、各段落のバウンディングボックスにラベルが付けられます。
推論
ノートブックを参照してください: Document AI | Inference at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
トレーニングと評価データ
ノートブックを参照してください: Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
🔧 技術詳細
トレーニングのハイパーパラメータ
トレーニング中に使用されたハイパーパラメータは以下の通りです。
- 学習率: 2e-05
- トレーニングバッチサイズ: 8
- 評価バッチサイズ: 16
- シード: 42
- オプティマイザ: Adam (betas=(0.9,0.999), epsilon=1e-08)
- 学習率スケジューラのタイプ: 線形
- 学習率スケジューラのウォームアップ率: 0.1
- エポック数: 4
- 混合精度トレーニング: Native AMP
トレーニング結果
| トレーニング損失 | エポック | ステップ | 精度 | F1 | 検証損失 | 精度 | 再現率 |
|---|---|---|---|---|---|---|---|
| 記録なし | 0.11 | 200 | 0.8842 | 0.1066 | 0.4428 | 0.1154 | 0.0991 |
| 記録なし | 0.21 | 400 | 0.9243 | 0.4440 | 0.3040 | 0.4548 | 0.4336 |
| 0.7241 | 0.32 | 600 | 0.9359 | 0.5544 | 0.2265 | 0.5330 | 0.5775 |
| 0.7241 | 0.43 | 800 | 0.9479 | 0.6015 | 0.2140 | 0.6013 | 0.6017 |
| 0.2343 | 0.53 | 1000 | 0.9402 | 0.6132 | 0.2852 | 0.6642 | 0.5695 |
| 0.2343 | 0.64 | 1200 | 0.9540 | 0.6604 | 0.1694 | 0.6565 | 0.6644 |
| 0.2343 | 0.75 | 1400 | 0.9354 | 0.6198 | 0.2308 | 0.5119 | 0.7854 |
| 0.1913 | 0.85 | 1600 | 0.9594 | 0.6590 | 0.1601 | 0.7190 | 0.6082 |
| 0.1913 | 0.96 | 1800 | 0.9541 | 0.6597 | 0.1671 | 0.5790 | 0.7664 |
| 0.1346 | 1.07 | 2000 | 0.9612 | 0.6986 | 0.1580 | 0.6838 | 0.7140 |
| 0.1346 | 1.17 | 2200 | 0.9597 | 0.6897 | 0.1423 | 0.6618 | 0.7200 |
| 0.1346 | 1.28 | 2400 | 0.9663 | 0.6980 | 0.1580 | 0.7490 | 0.6535 |
| 0.098 | 1.39 | 2600 | 0.9616 | 0.6800 | 0.1394 | 0.7044 | 0.6573 |
| 0.098 | 1.49 | 2800 | 0.9686 | 0.7251 | 0.1756 | 0.6893 | 0.7649 |
| 0.0999 | 1.6 | 3000 | 0.9636 | 0.6985 | 0.1542 | 0.7127 | 0.6848 |
| 0.0999 | 1.71 | 3200 | 0.9670 | 0.7097 | 0.1187 | 0.7538 | 0.6705 |
| 0.0999 | 1.81 | 3400 | 0.9585 | 0.7427 | 0.1793 | 0.7602 | 0.7260 |
| 0.0972 | 1.92 | 3600 | 0.9621 | 0.7189 | 0.1836 | 0.7576 | 0.6839 |
| 0.0972 | 2.03 | 3800 | 0.9642 | 0.7189 | 0.1465 | 0.7388 | 0.6999 |
| 0.0662 | 2.13 | 4000 | 0.9691 | 0.7450 | 0.1409 | 0.7615 | 0.7292 |
| 0.0662 | 2.24 | 4200 | 0.9615 | 0.7432 | 0.1720 | 0.7435 | 0.7429 |
| 0.0662 | 2.35 | 4400 | 0.9667 | 0.7338 | 0.1440 | 0.7469 | 0.7212 |
| 0.0581 | 2.45 | 4600 | 0.9657 | 0.7135 | 0.1928 | 0.7458 | 0.6839 |
| 0.0581 | 2.56 | 4800 | 0.9692 | 0.7378 | 0.1645 | 0.7467 | 0.7292 |
| 0.0538 | 2.67 | 5000 | 0.9656 | 0.7619 | 0.1517 | 0.7700 | 0.7541 |
| 0.0538 | 2.77 | 5200 | 0.9684 | 0.7728 | 0.1676 | 0.8227 | 0.7286 |
| 0.0538 | 2.88 | 5400 | 0.9725 | 0.7608 | 0.1277 | 0.7865 | 0.7367 |
| 0.0432 | 2.99 | 5600 | 0.9693 | 0.7784 | 0.1532 | 0.7891 | 0.7681 |
| 0.0432 | 3.09 | 5800 | 0.9692 | 0.7783 | 0.1701 | 0.8067 | 0.7519 |
| 0.0272 | 3.2 | 6000 | 0.9732 | 0.7798 | 0.1159 | 0.8072 | 0.7542 |
| 0.0272 | 3.3 | 6200 | 0.9720 | 0.7797 | 0.1835 | 0.7926 | 0.7672 |
| 0.0272 | 3.41 | 6400 | 0.9730 | 0.7894 | 0.1481 | 0.8183 | 0.7624 |
| 0.0274 | 3.52 | 6600 | 0.9686 | 0.7655 | 0.1552 | 0.7958 | 0.7373 |
| 0.0274 | 3.62 | 6800 | 0.9698 | 0.7724 | 0.1523 | 0.8068 | 0.7407 |
| 0.0246 | 3.73 | 7000 | 0.9691 | 0.7720 | 0.1673 | 0.7960 | 0.7493 |
| 0.0246 | 3.84 | 7200 | 0.9688 | 0.7695 | 0.1333 | 0.7986 | 0.7424 |
| 0.0246 | 3.94 | 7400 | 0.1796 | 0.8062 | 0.7441 | 0.7739 | 0.9693 |
フレームワークのバージョン
- Transformers 4.27.3
- Pytorch 1.10.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
その他のモデル
- 行レベル
- [Document Understanding model (finetuned LiLT base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-line
📄 ライセンス
このモデルは、MITライセンスの下で提供されています。
 Safetensors
Safetensors