%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Layout Xlm Base Finetuned With DocLayNet Base At Paragraphlevel Ml512
模型概述
這是一個多語言文檔理解模型,能夠識別和分析PDF文檔中的段落級別元素,如標題、文本、表格、圖片等。
模型特點
段落級文檔理解
能夠識別和分析文檔中的段落級別元素,包括標題、文本、表格、圖片等11種不同類型
多語言支持
支持英語、德語、法語和日語等多種語言的文檔分析
高準確率
在DocLayNet測試集上取得了86.55%的段落準確率和96.93%的標記準確率
模型能力
文檔佈局分析
段落分類
多語言文檔處理
PDF內容理解
使用案例
金融文檔處理
財務報告分析
自動識別財務報告中的不同部分,如表格、文本和標題
準確率高達90%以上
法律文檔處理
法律條文解析
識別法律文檔中的章節、條款和註釋
章節標題識別準確率83.16%
科學文獻處理
科學論文解析
識別論文中的公式和圖表
公式識別準確率95.33%
🚀 文檔理解模型(在DocLayNet基礎數據集上按段落級別微調LayoutXLM基礎模型)
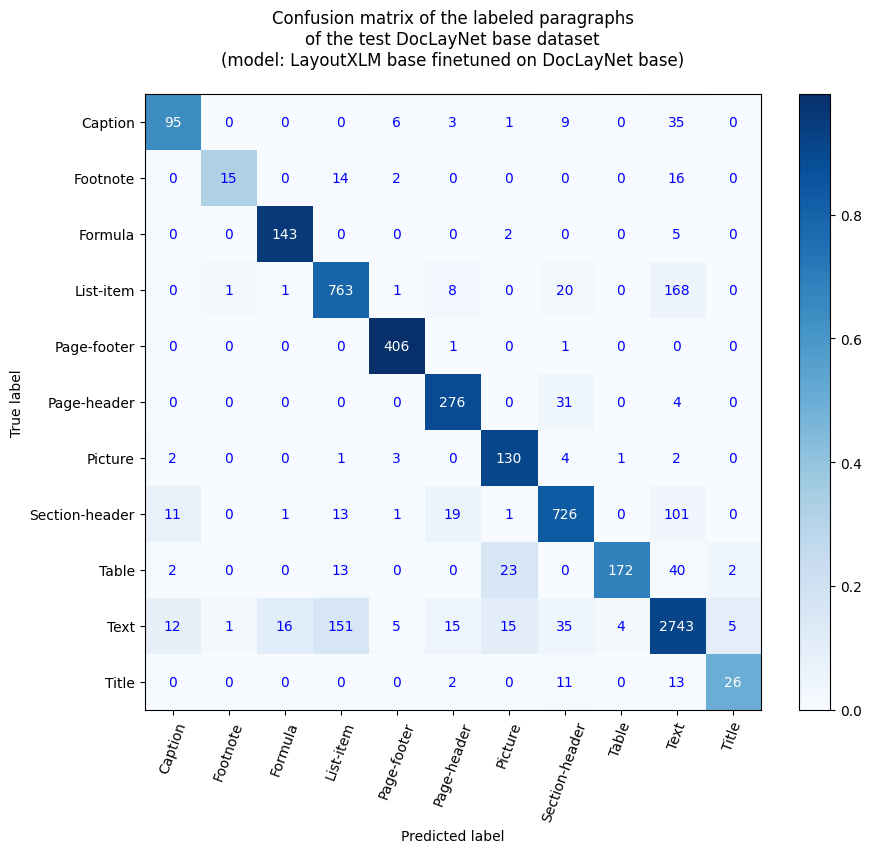
該模型是基於 microsoft/layoutxlm-base 模型,使用 DocLayNet base 數據集進行微調得到的。在評估集上,該模型取得了以下結果:
- 損失值:0.1796
- 精確率:0.8062
- 召回率:0.7441
- F1值:0.7739
- 標記準確率:0.9693
- 段落準確率:0.8655
🚀 快速開始
本模型可用於文檔理解任務,特別是段落級別的文檔佈局分析。你可以通過以下方式快速體驗模型:
- 使用Hugging Face Spaces中的應用程序進行測試。
- 運行對應的Jupyter Notebook進行推理。
✨ 主要特性
- 多語言支持:支持多種語言的文檔理解。
- 段落級分析:能夠對文檔進行段落級別的佈局分析。
- 高精度:在評估集上取得了較高的準確率和F1值。
📚 詳細文檔
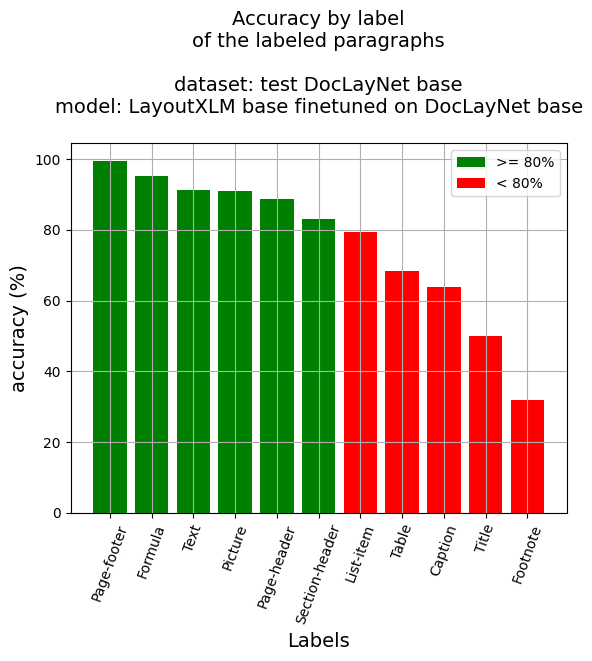
段落級準確率
- 段落準確率:86.55%
- 按標籤分類的準確率
- 標題說明:63.76%
- 腳註:31.91%
- 公式:95.33%
- 列表項:79.31%
- 頁面頁腳:99.51%
- 頁面頁眉:88.75%
- 圖片:90.91%
- 章節標題:83.16%
- 表格:68.25%
- 文本:91.37%
- 標題:50.0%
參考資料
博客文章
- Layout XLM基礎模型
- (2023年3月31日) Document AI | 使用LayoutXLM基礎模型進行段落級文檔理解的推理應用和微調筆記本
- (2023年3月25日) Document AI | 用於比較行級文檔理解LiLT和LayoutXLM(基礎)模型的應用程序
- (2023年3月5日) Document AI | 使用LayoutXLM基礎模型進行行級文檔理解的推理應用和微調筆記本
- LiLT基礎模型 - (2023年2月16日) Document AI | 用於段落級文檔理解的推理應用和微調筆記本 - (2023年2月14日) Document AI | 用於行級文檔理解的推理應用 - (2023年2月10日) Document AI | 使用LiLT、Tesseract和DocLayNet數據集的行級文檔理解模型 - (2023年1月31日) Document AI | DocLayNet圖像查看器應用程序 - (2023年1月27日) Document AI | 處理DocLayNet數據集以供Hugging Face中心的佈局模型使用(微調、推理)
筆記本(段落級別)
- Layout XLM基礎模型
- LiLT基礎模型
筆記本(行級別)
- Layout XLM基礎模型
- LiLT基礎模型
應用程序
你可以使用Hugging Face Spaces中的這個應用程序測試該模型:段落級文檔理解推理應用程序(v2)。
你也可以運行對應的筆記本:Document AI | 使用文檔理解模型(在DocLayNet數據集上微調的LayoutXLM基礎模型)進行段落級推理應用
DocLayNet數據集
DocLayNet數據集(IBM)為來自6個文檔類別的80863個唯一頁面,使用邊界框為11個不同的類別標籤提供了逐頁佈局分割的真實標註。
到目前為止,該數據集可以通過直接鏈接下載,也可以從Hugging Face數據集庫獲取:
- 直接鏈接:doclaynet_core.zip(28 GiB),doclaynet_extra.zip(7.5 GiB)
- Hugging Face數據集庫:數據集DocLayNet
論文:DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis(2022年6月2日)
模型描述
該模型在段落級別,以512個標記塊且重疊128個標記的方式進行微調。因此,模型使用了數據集中所有頁面的佈局和文本數據進行訓練。
在推理時,通過計算最佳概率為每個段落邊界框分配標籤。
推理
請參考筆記本:Document AI | 使用文檔理解模型(在DocLayNet數據集上微調的LayoutXLM基礎模型)進行段落級推理
訓練和評估數據
請參考筆記本:Document AI | 在任何語言的DocLayNet基礎數據集上按段落級別(512個標記塊,有重疊)微調LayoutXLM基礎模型
訓練過程
訓練超參數
訓練過程中使用了以下超參數:
- 學習率:2e-05
- 訓練批次大小:8
- 評估批次大小:16
- 隨機種子:42
- 優化器:Adam,β值=(0.9, 0.999),ε值=1e-08
- 學習率調度器類型:線性
- 學習率調度器熱身比例:0.1
- 訓練輪數:4
- 混合精度訓練:原生自動混合精度(Native AMP)
訓練結果
| 訓練損失 | 輪數 | 步數 | 準確率 | F1值 | 驗證損失 | 精確率 | 召回率 |
|---|---|---|---|---|---|---|---|
| 無記錄 | 0.11 | 200 | 0.8842 | 0.1066 | 0.4428 | 0.1154 | 0.0991 |
| 無記錄 | 0.21 | 400 | 0.9243 | 0.4440 | 0.3040 | 0.4548 | 0.4336 |
| 0.7241 | 0.32 | 600 | 0.9359 | 0.5544 | 0.2265 | 0.5330 | 0.5775 |
| 0.7241 | 0.43 | 800 | 0.9479 | 0.6015 | 0.2140 | 0.6013 | 0.6017 |
| 0.2343 | 0.53 | 1000 | 0.9402 | 0.6132 | 0.2852 | 0.6642 | 0.5695 |
| 0.2343 | 0.64 | 1200 | 0.9540 | 0.6604 | 0.1694 | 0.6565 | 0.6644 |
| 0.2343 | 0.75 | 1400 | 0.9354 | 0.6198 | 0.2308 | 0.5119 | 0.7854 |
| 0.1913 | 0.85 | 1600 | 0.9594 | 0.6590 | 0.1601 | 0.7190 | 0.6082 |
| 0.1913 | 0.96 | 1800 | 0.9541 | 0.6597 | 0.1671 | 0.5790 | 0.7664 |
| 0.1346 | 1.07 | 2000 | 0.9612 | 0.6986 | 0.1580 | 0.6838 | 0.7140 |
| 0.1346 | 1.17 | 2200 | 0.9597 | 0.6897 | 0.1423 | 0.6618 | 0.7200 |
| 0.1346 | 1.28 | 2400 | 0.9663 | 0.6980 | 0.1580 | 0.7490 | 0.6535 |
| 0.098 | 1.39 | 2600 | 0.9616 | 0.6800 | 0.1394 | 0.7044 | 0.6573 |
| 0.098 | 1.49 | 2800 | 0.9686 | 0.7251 | 0.1756 | 0.6893 | 0.7649 |
| 0.0999 | 1.6 | 3000 | 0.9636 | 0.6985 | 0.1542 | 0.7127 | 0.6848 |
| 0.0999 | 1.71 | 3200 | 0.9670 | 0.7097 | 0.1187 | 0.7538 | 0.6705 |
| 0.0999 | 1.81 | 3400 | 0.9585 | 0.7427 | 0.1793 | 0.7602 | 0.7260 |
| 0.0972 | 1.92 | 3600 | 0.9621 | 0.7189 | 0.1836 | 0.7576 | 0.6839 |
| 0.0972 | 2.03 | 3800 | 0.9642 | 0.7189 | 0.1465 | 0.7388 | 0.6999 |
| 0.0662 | 2.13 | 4000 | 0.9691 | 0.7450 | 0.1409 | 0.7615 | 0.7292 |
| 0.0662 | 2.24 | 4200 | 0.9615 | 0.7432 | 0.1720 | 0.7435 | 0.7429 |
| 0.0662 | 2.35 | 4400 | 0.9667 | 0.7338 | 0.1440 | 0.7469 | 0.7212 |
| 0.0581 | 2.45 | 4600 | 0.9657 | 0.7135 | 0.1928 | 0.7458 | 0.6839 |
| 0.0581 | 2.56 | 4800 | 0.9692 | 0.7378 | 0.1645 | 0.7467 | 0.7292 |
| 0.0538 | 2.67 | 5000 | 0.9656 | 0.7619 | 0.1517 | 0.7700 | 0.7541 |
| 0.0538 | 2.77 | 5200 | 0.9684 | 0.7728 | 0.1676 | 0.8227 | 0.7286 |
| 0.0538 | 2.88 | 5400 | 0.9725 | 0.7608 | 0.1277 | 0.7865 | 0.7367 |
| 0.0432 | 2.99 | 5600 | 0.9693 | 0.7784 | 0.1532 | 0.7891 | 0.7681 |
| 0.0432 | 3.09 | 5800 | 0.9692 | 0.7783 | 0.1701 | 0.8067 | 0.7519 |
| 0.0272 | 3.2 | 6000 | 0.9732 | 0.7798 | 0.1159 | 0.8072 | 0.7542 |
| 0.0272 | 3.3 | 6200 | 0.9720 | 0.7797 | 0.1835 | 0.7926 | 0.7672 |
| 0.0272 | 3.41 | 6400 | 0.9730 | 0.7894 | 0.1481 | 0.8183 | 0.7624 |
| 0.0274 | 3.52 | 6600 | 0.9686 | 0.7655 | 0.1552 | 0.7958 | 0.7373 |
| 0.0274 | 3.62 | 6800 | 0.9698 | 0.7724 | 0.1523 | 0.8068 | 0.7407 |
| 0.0246 | 3.73 | 7000 | 0.9691 | 0.7720 | 0.1673 | 0.7960 | 0.7493 |
| 0.0246 | 3.84 | 7200 | 0.9688 | 0.7695 | 0.1333 | 0.7986 | 0.7424 |
| 0.0246 | 3.94 | 7400 | 0.1796 | 0.8062 | 0.7441 | 0.7739 | 0.9693 |
框架版本
- Transformers 4.27.3
- Pytorch 1.10.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
其他模型
- 行級別
- 文檔理解模型(在DocLayNet基礎數據集上按行級別微調LiLT基礎模型)(準確率 | 標記:85.84% - 行:91.97%)
- 文檔理解模型(在DocLayNet基礎數據集上按行級別微調LayoutXLM基礎模型)(準確率 | 標記:93.73% - 行:...)
- 段落級別
- 文檔理解模型(在DocLayNet基礎數據集上按段落級別微調LiLT基礎模型)(準確率 | 標記:86.34% - 段落:68.15%)
- 文檔理解模型(在DocLayNet基礎數據集上按段落級別微調LayoutXLM基礎模型)(準確率 | 標記:96.93% - 段落:86.55%)
📄 許可證
本項目採用MIT許可證。
Table Transformer Structure Recognition
MIT
基於PubTables1M數據集訓練的表格變換器模型,用於從非結構化文檔中提取表格結構
文字識別 Transformers
Transformers
T
microsoft
1.2M
186
Trocr Small Handwritten
TrOCR是一個基於Transformer的光學字符識別模型,專門用於手寫文本圖像的識別。
文字識別 Transformers
T
microsoft
517.96k
45
Table Transformer Structure Recognition V1.1 All
MIT
基於Transformer的表格結構識別模型,用於檢測文檔中的表格結構
文字識別 Transformers
T
microsoft
395.03k
70
Trocr Large Printed
基於Transformer的光學字符識別模型,適用於單行印刷體文本識別
文字識別 Transformers
T
microsoft
295.59k
162
Texify
Texify 是一個 OCR 工具,專門用於將公式圖片和文本轉換為 LaTeX 格式。
文字識別 Transformers
T
vikp
206.53k
15
Trocr Base Printed
TrOCR是基於Transformer的光學字符識別模型,專為單行文本圖像識別設計,採用編碼器-解碼器架構
文字識別 Transformers
T
microsoft
184.84k
169
Manga Ocr Base
Apache-2.0
專為日語文本設計的光學字符識別工具,主要針對日本漫畫場景優化。
文字識別 Transformers 日語
M
kha-white
130.36k
145
Tiny Random Internvl2
專注於將圖像中的文本信息提取並轉化為可編輯的文本內容
文字識別 Safetensors
Safetensors
SafetensorsT
katuni4ka
73.27k
0
Trocr Large Handwritten
TrOCR是基於Transformer的光學字符識別模型,專為手寫文本識別設計,在IAM數據集上進行了微調。
文字識別 Transformers
T
microsoft
59.17k
115
Trocr Small Printed
TrOCR是一個基於Transformer的光學字符識別模型,適用於單行文本圖像的OCR任務。
文字識別 Transformers
T
microsoft
20.88k
40
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98