🚀 燃灯-T5-784M-QA-中文
このモデルは中国語の質問応答に特化したT5モデルで、文章と質問を入力することで、流暢で正確な回答を生成することができます。
🚀 クイックスタート
このモデルは、huggingface上で初めて公開された中国語の生成式質問応答モデルです。T5-Large構造に基づき、悟道180Gコーパスを使用して封神フレームワークで事前学習され、翻訳された中国語のSQuADとCMRC2018の2つの読解データセットで微調整されています。
✨ 主な機能
- 高品質な回答生成: 76%の回答が正解を含んでおり、RougeLとBLEU-4の値が高いことから、生成結果と正解の重複度が高いことがわかります。
- 柔軟な回答形式: 完全な文章を生成することができるため、回答の形式が柔軟です。
📦 インストール
pip install transformers==4.21.1
💻 使用例
基本的な使用法
import numpy as np
from transformers import T5Tokenizer,MT5ForConditionalGeneration
pretrain_path = 'IDEA-CCNL/Randeng-T5-784M-QA-Chinese'
tokenizer=T5Tokenizer.from_pretrained(pretrain_path)
model=MT5ForConditionalGeneration.from_pretrained(pretrain_path)
sample={"context":"在柏林,胡格诺派教徒创建了两个新的社区:多罗西恩斯塔特和弗里德里希斯塔特。到1700年,这个城市五分之一的人口讲法语。柏林胡格诺派在他们的教堂服务中保留了将近一个世纪的法语。他们最终决定改用德语,以抗议1806-1807年拿破仑占领普鲁士。他们的许多后代都有显赫的地位。成立了几个教会,如弗雷德里夏(丹麦)、柏林、斯德哥尔摩、汉堡、法兰克福、赫尔辛基和埃姆登的教会。","question":"除了多罗西恩斯塔特,柏林还有哪个新的社区?","idx":1}
plain_text='question:'+sample['question']+'knowledge:'+sample['context'][:self.max_knowledge_length]
res_prefix=tokenizer.encode('answer',add_special_tokens=False)
res_prefix.append(tokenizer.convert_tokens_to_ids('<extra_id_0>'))
res_prefix.append(tokenizer.eos_token_id)
l_rp=len(res_prefix)
tokenized=tokenizer.encode(plain_text,add_special_tokens=False,truncation=True,max_length=1024-2-l_rp)
tokenized+=res_prefix
batch=[tokenized]*2
input_ids=torch.tensor(np.array(batch),dtype=torch.long)
max_target_length=128
pred_ids = model.generate(input_ids=input_ids,max_new_tokens=max_target_length,do_sample=True,top_p=0.9)
pred_tokens=tokenizer.batch_decode(pred_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
res=pred_tokens.replace('<extra_id_0>','').replace('有答案:','')
📚 ドキュメント
モデルカテゴリ
| 属性 |
详情 |
| モデルタイプ |
通用 - 自然言語変換 - 燃灯 - T5 |
| パラメータ |
784M |
| 追加情報 |
中国語生成式質問応答 |
モデル性能
CMRC 2018の開発セットでの性能(元のタスクは開始と終了の予測問題ですが、ここでは生成応答の問題として扱っています)
| モデル |
回答包含率 |
RougeL |
BLEU-4 |
F1 |
EM |
| 当モデル |
76.0 |
82.7 |
61.1 |
77.9 |
57.1 |
| MacBERT-Large(SOTA) |
- |
- |
- |
88.9 |
70.0 |
当モデルは生成品質と精度が非常に高く、生成された回答の76%が正解を含んでいます。RougeLとBLEU-4の値が高いことから、生成結果と正解の重複度が高いことがわかります。当モデルのEM値が低いのは、生成されるのが大部分が完全な文章であるのに対し、正解は通常文章の断片であるためです。
P.S. SOTAモデルは抽出型のMRCタスクとして開始と終了タグのみを予測します。
サンプル
以下はランダムに選ばれたサンプルです。
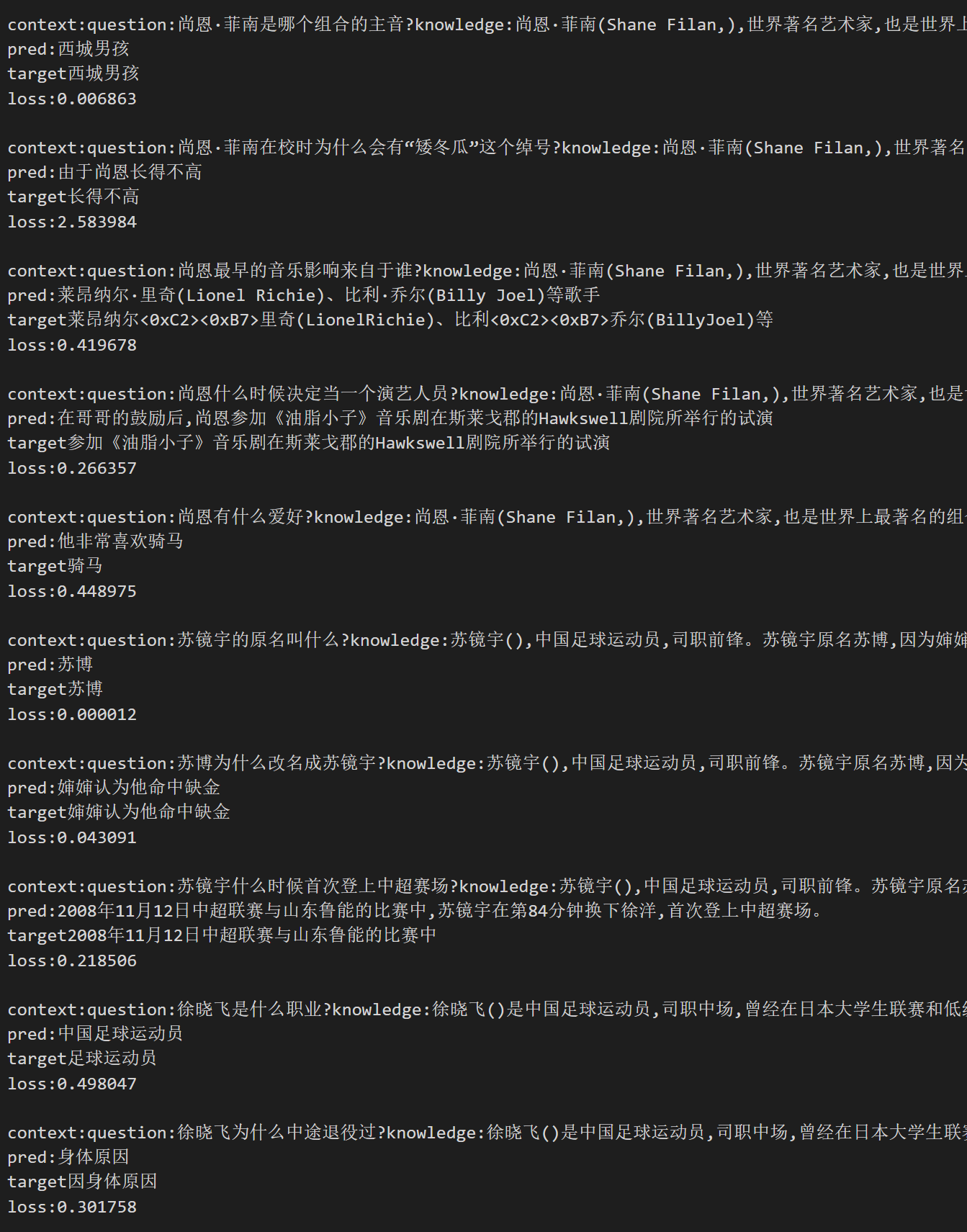
pred: 画像内の生成結果、target: 正解を示します。
画像が表示されない場合は、「ファイルとバージョン」で画像を見つけることができます。
📄 ライセンス
このモデルはApache-2.0ライセンスの下で公開されています。
📖 引用
もしあなたの研究や開発でこのモデルを使用した場合は、以下の論文を引用してください。
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
また、以下のウェブサイトも引用することができます。
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応