🚀 燃燈-T5-784M-中文問答模型
這是一款基於T5架構的中文問答模型,可根據給定段落和問題生成流暢準確的答案,在多個問答指標上表現出色。
🚀 快速開始
本模型是huggingface上首箇中文的生成式問答模型。它基於T5-Large結構,使用悟道180G語料在封神框架進行預訓練,在翻譯的中文SQuAD和CMRC2018兩個閱讀理解數據集上進行微調。輸入一篇文章和一個問題,它可以生成準確流暢的回答。
安裝
pip install transformers==4.21.1
使用示例
import numpy as np
from transformers import T5Tokenizer,MT5ForConditionalGeneration
pretrain_path = 'IDEA-CCNL/Randeng-T5-784M-QA-Chinese'
tokenizer=T5Tokenizer.from_pretrained(pretrain_path)
model=MT5ForConditionalGeneration.from_pretrained(pretrain_path)
sample={"context":"在柏林,胡格諾派教徒創建了兩個新的社區:多羅西恩斯塔特和弗里德里希斯塔特。到1700年,這個城市五分之一的人口講法語。柏林胡格諾派在他們的教堂服務中保留了將近一個世紀的法語。他們最終決定改用德語,以抗議1806-1807年拿破崙佔領普魯士。他們的許多後代都有顯赫的地位。成立了幾個教會,如弗雷德里夏(丹麥)、柏林、斯德哥爾摩、漢堡、法蘭克福、赫爾辛基和埃姆登的教會。","question":"除了多羅西恩斯塔特,柏林還有哪個新的社區?","idx":1}
plain_text='question:'+sample['question']+'knowledge:'+sample['context'][:self.max_knowledge_length]
res_prefix=tokenizer.encode('answer',add_special_tokens=False)
res_prefix.append(tokenizer.convert_tokens_to_ids('<extra_id_0>'))
res_prefix.append(tokenizer.eos_token_id)
l_rp=len(res_prefix)
tokenized=tokenizer.encode(plain_text,add_special_tokens=False,truncation=True,max_length=1024-2-l_rp)
tokenized+=res_prefix
batch=[tokenized]*2
input_ids=torch.tensor(np.array(batch),dtype=torch.long)
max_target_length=128
pred_ids = model.generate(input_ids=input_ids,max_new_tokens=max_target_length,do_sample=True,top_p=0.9)
pred_tokens=tokenizer.batch_decode(pred_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
res=pred_tokens.replace('<extra_id_0>','').replace('有答案:','')
✨ 主要特性
- 首箇中文生成式問答模型:在huggingface上率先推出針對中文的生成式問答模型。
- 高質量訓練:基於悟道180G語料預訓練,並在中文SQuAD和CMRC2018數據集上微調。
- 高生成質量和準確率:76%的回答包含了正確答案,RougeL和BLEU - 4反映出預測結果和標準答案有較高的重合度。
📦 安裝指南
pip install transformers==4.21.1
📚 詳細文檔
模型類別
| 屬性 |
詳情 |
| 需求 |
通用 |
| 任務 |
自然語言轉換 |
| 系列 |
燃燈 |
| 模型 |
T5 |
| 參數 |
784M |
| 額外 |
中文生成式問答 |
模型表現
在CMRC 2018的測試集上進行評估(原始任務是起始和結束預測問題,這裡作為生成回答的問題):
| 模型 |
包含答案率 |
RougeL |
BLEU - 4 |
F1 |
EM |
| 本模型 |
76.0 |
82.7 |
61.1 |
77.9 |
57.1 |
| MacBERT - Large(SOTA) |
- |
- |
- |
88.9 |
70.0 |
我們的模型有著極高的生成質量和準確率,76%的回答包含了正確答案(包含答案率)。RougeL和BLEU - 4反映了模型預測結果和標準答案重合的程度。我們的模型EM值較低,因為生成的大部分為完整的句子,而標準答案通常是句子片段。需要注意的是,SOTA模型只需預測起始和結束位置,這種抽取式閱讀理解任務比生成式的簡單很多。
樣例
以下是隨機抽取的樣本:
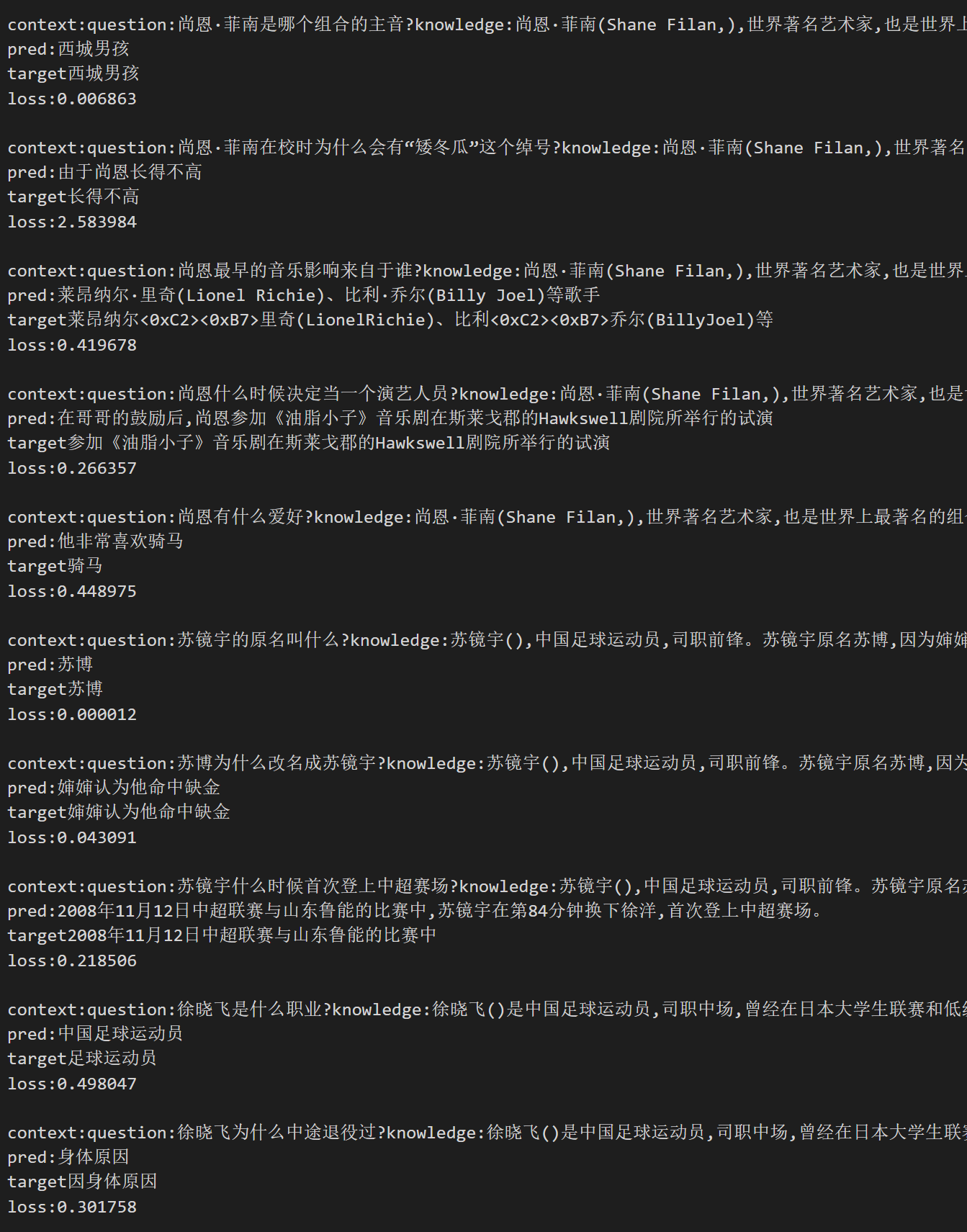
pred 為生成結果,target 為標準答案。
如果圖片無法顯示,您可以在文件和版本中找到該圖片。
📄 許可證
本模型使用的許可證為Apache - 2.0。
📖 引用
如果您在您的工作中使用了我們的模型,可以引用我們的論文:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也歡迎引用我們的網站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言