🚀 GPT - 2土耳其语模型
GPT - 2土耳其语模型是专门针对土耳其语定制的大型数据模型,属于大语言模型(LLM)类别。它基于GPT - 2架构构建,拥有专门定制的分词器结构,代表了一个土耳其语语言模型。该模型能够利用给定的起始文本生成类似人类的文本,并且在大量的土耳其语文本数据集上进行了训练。
🚀 快速开始
模型使用说明
重要提示:由于模型对大小写敏感,因此提示词必须全部使用小写字母。
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "okyanusun derinliklerinde bulunan"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
✨ 主要特性
GPT - 2土耳其语模型具有以下特性:
- 基于GPT - 2架构,专为土耳其语定制。
- 拥有特殊的分词器结构,符合土耳其语的词法特点。
- 能够根据起始文本生成自然流畅的文本。
- 在大规模土耳其语文本数据集上进行训练,具有广泛的语言理解能力。
📦 安装指南
文档未提及安装相关内容,若有安装需求,可参考transformers库的安装方式来安装所需依赖。
💻 使用示例
基础用法
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "okyanusun derinliklerinde bulunan"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
📚 详细文档
模型描述
GPT - 2土耳其语模型是一个专门为土耳其语定制的大型语言模型。它基于GPT - 2架构,分词器结构是专门为土耳其语设计的。该模型能够使用给定的起始文本生成类似人类的文本,并且在一个包含9亿字符的维基百科数据集上进行了训练。
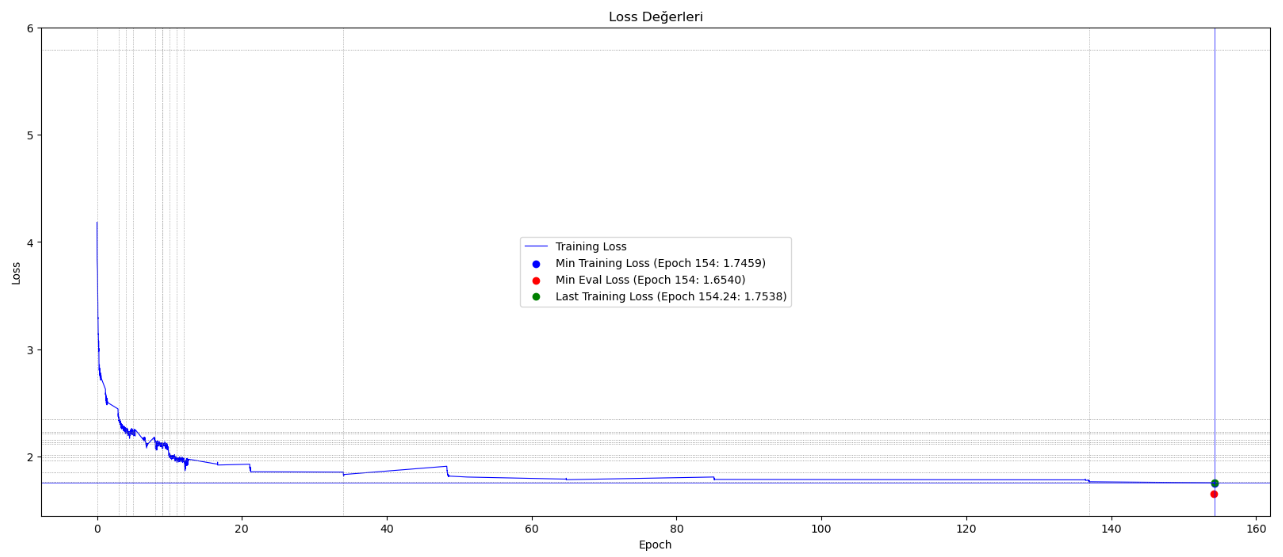
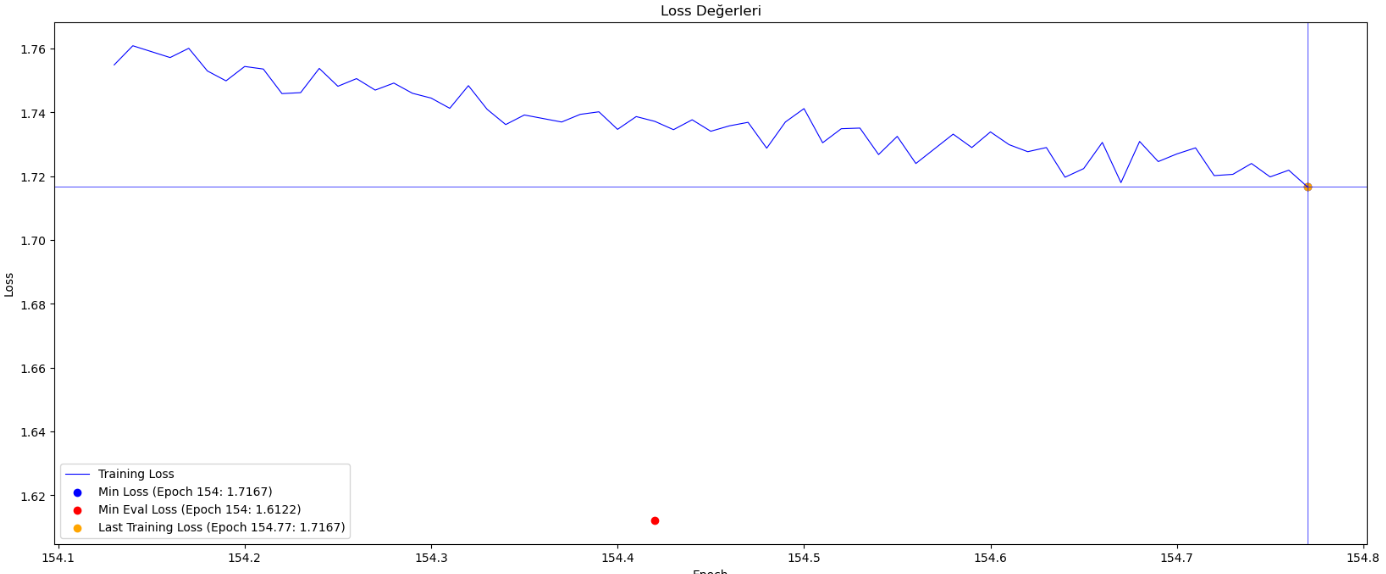
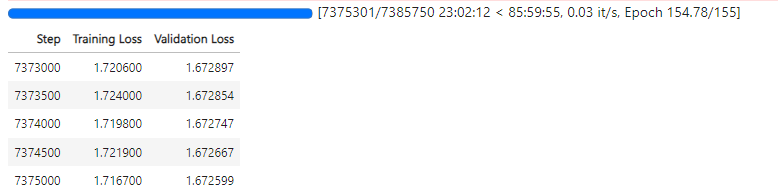
训练集中的句子最多由128个词元(词元 = 词根和词缀)组成,因此生成的句子长度是有限的。模型使用了符合土耳其语词法结构的分词器,并在大约154个周期内进行了750万步的训练。训练使用了具有4GB内存的Nvidia Geforce RTX 3050 GPU,还利用了16GB共享GPU,训练过程中总共使用了20GB内存。
训练过程曲线
🔧 技术细节
- 训练数据:使用了9亿字符的维基百科数据集进行训练。
- 分词器:采用了符合土耳其语词法结构的分词器。
- 训练步数和周期:模型在大约154个周期内进行了750万步的训练。
- 硬件资源:训练使用了具有4GB内存的Nvidia Geforce RTX 3050 GPU,还利用了16GB共享GPU,训练过程中总共使用了20GB内存。
📄 许可证
文档未提及许可证相关信息。
⚠️ 重要提示
此模型作为自回归语言模型进行训练,这意味着其基本功能是接收一个文本序列并预测下一个词元。尽管语言模型广泛用于许多其他任务,但与此工作相关的仍有许多未知因素。
该模型在一个已知包含亵渎、露骨内容和不良行为文本的数据集上进行了训练。根据使用场景,此模型可能会生成社会无法接受的文本。
与所有语言模型一样,很难预先预测此模型对特定输入的响应方式,并且可能会在没有警告的情况下出现攻击性内容。建议在发布结果之前,由人工对输出进行审查或过滤,以审查不需要的内容并提高结果质量。
💡 使用建议
- 由于模型对大小写敏感,提示词请全部使用小写字母。
- 在发布模型生成的结果之前,务必进行人工审查,以确保内容符合社会道德规范。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言