🚀 GPT-2 Turkish Model
A large data model specialized for the Turkish language, belonging to the LLM (Large Language Model) category.
Widgets
| Example Title |
Text |
| The capital city of France |
'The capital city of France' |
| The capital city of England |
'The capital city of England' |
| The capital city of Italy |
'The capital city of Italy' |
| The capital city of Mongolia |
'The capital city of Mongolia' |
| The country where the Amazon rainforests are located |
'The country where the Amazon rainforests are located' |
| The city that connects Europe to Asia |
'The city that connects Europe to Asia' |
| The continent where zebras live |
'The continent where zebras live' |
| The traditional rival of Fenerbahçe |
'The traditional rival of Fenerbahçe' |
| One - legged frog |
'One - legged frog' |
| Rain in Rize |
'Rain in Rize' |
| The meaning of life |
'The meaning of life' |
| Saint - Joseph |
'Saint - Joseph' |
| The names of colors are as follows |
'The names of colors are as follows' |
| Climate change |
'Climate change' |
| Among salty foods |
'Among salty foods' |
Model Description
The GPT - 2 Turkish Model is a large data model specialized for the Turkish language and belongs to the LLM (Large Language Model) category. This model is based on the GPT - 2 architecture and represents a Turkish language model with a specially prepared tokenizer structure. The model has the ability to generate human - like texts using a given starting text and has been trained on a large Turkish text dataset.
A Wikipedia dataset of 900 million characters was used for training the model. The sentences in the training set consist of a maximum of 128 tokens (token = root word and affixes), so the length of the sentences it can generate is limited. A tokenizer suitable for the Turkish syllable structure was used, and the model was trained for approximately 154 epochs over 7.5 million steps.
An Nvidia Geforce RTX 3050 GPU with 4GB of memory is used for training. A shared 16GB GPU is also utilized, and a total of 20GB of memory is used during the training process.
🚀 Quick Start
📦 Installation
There is no specific installation content provided in the original text.
💻 Usage Examples
⚠️ Important Note
Since the model is case - sensitive, the prompt must be written entirely in lowercase.
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "okyanusun derinliklerinde bulunan"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
🔧 Technical Details
Training Process Curve
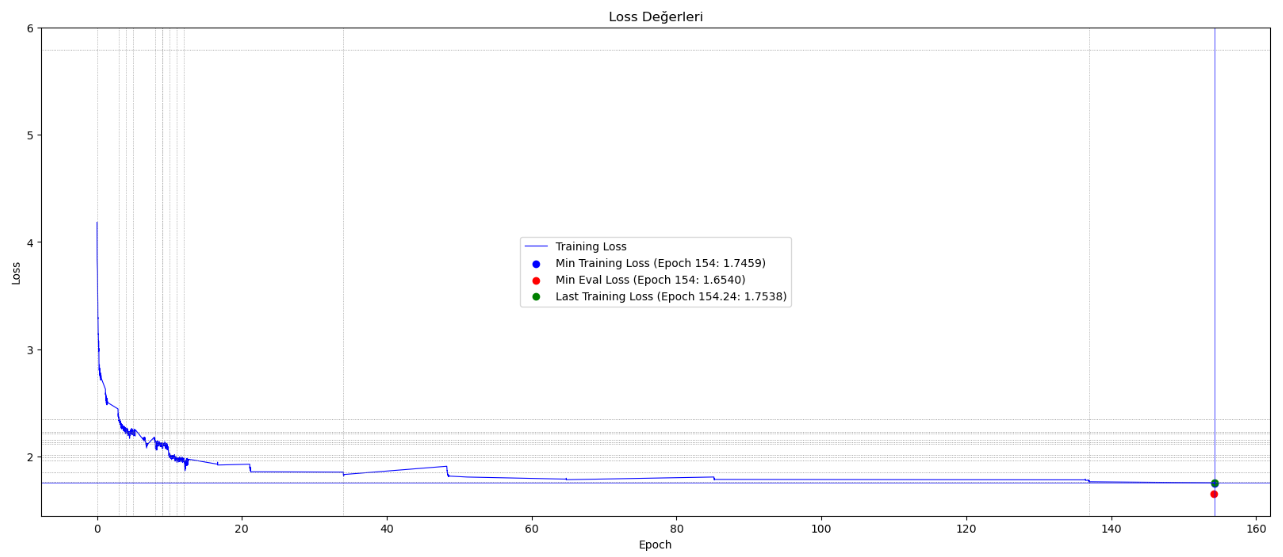
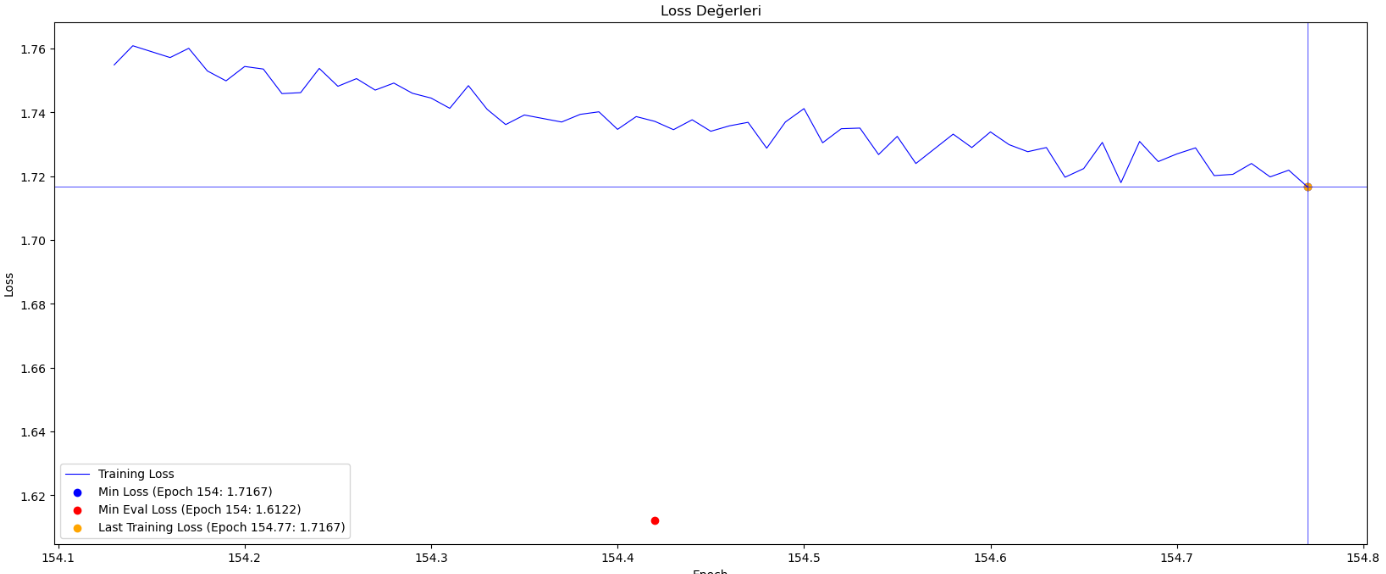
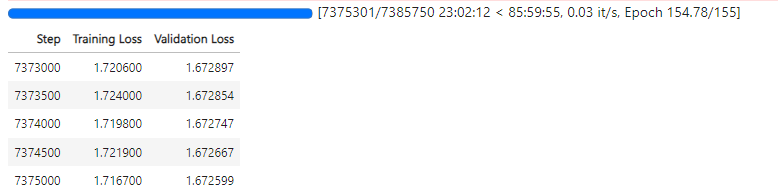
Limitations and Biases
This model was trained as an autoregressive language model. This means that its primary function is to take a sequence of text and predict the next token. Although language models are widely used for many tasks other than this, there are many unknowns related to this work.
The model was trained on a dataset known to contain texts that lead to swear words, explicit content, and inappropriate behavior. Depending on your use case, this model may generate socially unacceptable texts.
As with all language models, it is difficult to predict in advance how this model will respond to a given input, and aggressive content may appear without warning. It is recommended that humans review or filter the outputs to both censor unwanted content and improve the quality of the results before publishing them.
📄 License
There is no license information provided in the original text.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)