%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 KcBERT:韩国语评论BERT
KcBERT是一个预训练的BERT模型,为了应用于具有特定特征的数据集,它从Naver新闻中收集评论和回复,从头开始训练分词器和BERT模型。该模型可以通过Huggingface的Transformers库轻松加载和使用。
🚀 快速开始
KcBERT可以通过Huggingface的Transformers库轻松加载和使用,无需额外下载文件。以下是使用示例:
from transformers import AutoTokenizer, AutoModelWithLMHead
# 基础模型(108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# 大型模型(334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
✨ 主要特性
- 针对特定数据优化:大多数公开的韩语BERT模型是基于韩语维基百科、新闻文章、书籍等经过良好整理的数据进行训练的。而KcBERT为了应用于具有特定特征的数据集,从Naver新闻中收集评论和回复,从头开始训练分词器和BERT模型。
- 易于使用:可以通过Huggingface的Transformers库轻松加载和使用,无需额外下载文件。
📦 安装指南
依赖项
pytorch <= 1.8.0transformers ~= 3.0.1(也兼容transformers ~= 4.0.0)emoji ~= 0.6.0soynlp ~= 0.0.493
💻 使用示例
基础用法
from transformers import AutoTokenizer, AutoModelWithLMHead
# 基础模型(108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# 大型模型(334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
高级用法
你可以在以下链接中找到微调代码:https://github.com/Beomi/KcBERT-finetune 。
📚 详细文档
KcBERT性能
| 属性 | 详情 |
|---|---|
| 模型类型 | KcBERT-Base、KcBERT-Large |
| 训练数据 | 2019.01.01 ~ 2020.06.15期间撰写的评论较多的新闻文章的评论和回复 |
| 评估指标 | NSMC(acc)、Naver NER(F1)、PAWS(acc)、KorNLI(acc)、KorSTS(spearman)、Question Pair(acc)、KorQuaD (Dev)(EM/F1) |
具体性能数据如下:
| 模型 | 大小(容量) | NSMC (acc) |
Naver NER (F1) |
PAWS (acc) |
KorNLI (acc) |
KorSTS (spearman) |
Question Pair (acc) |
KorQuaD (Dev) (EM/F1) |
|---|---|---|---|---|---|---|---|---|
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
*HanBERT的大小是Bert模型和分词器数据库的总和。
*结果是在保持配置设置不变的情况下运行得到的,如果进行额外的超参数调整,可能会获得更好的性能。
预训练和微调Colab链接汇总
预训练数据
预训练代码
在Colab中使用TPU进行KcBERT预训练:
![]()
微调示例
- KcBERT-Base 在NSMC上使用PyTorch-Lightning进行微调(Colab):

- KcBERT-Large 在NSMC上使用PyTorch-Lightning进行微调(Colab):
以上两个代码除了预训练模型(base,large)和批量大小不同外,其余代码完全相同。
训练数据与预处理
原始数据
训练数据是2019.01.01至2020.06.15期间撰写的评论较多的新闻文章的评论和回复。数据大小约为15.4GB(仅提取文本),包含超过1.1亿个句子。
预处理
为了进行PLM训练,进行了以下预处理步骤:
- 包含韩语、英语、特殊字符和表情符号:使用正则表达式将韩语、英语、特殊字符和表情符号纳入训练范围。同时,将韩语范围指定为
ㄱ-ㅎ가-힣,排除了ㄱ-힣内的汉字。 - 缩写评论中的重复字符串:将重复的字符(如
ㅋㅋㅋㅋㅋ)合并为ㅋㅋ。 - 大小写敏感模型:KcBERT是一个大小写敏感的模型,对于英文保留大小写。
- 删除10个字符以下的文本:由于10个字符以下的文本通常由单个单词组成,因此排除了这部分文本。
- 去重:合并重复的评论以去除重复内容。
最终生成的训练数据大小为12.5GB,包含8900万个句子。你可以使用以下命令通过pip安装所需库,并使用 clean 函数进行清理,以提高下游任务的性能(减少 [UNK]):
pip install soynlp emoji
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
emojis = ''.join(emojis)
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
清理后的数据(在Kaggle上发布)
你可以从以下Kaggle数据集下载使用上述 clean 函数清理后的12GB文本文件:Kaggle数据集
分词器训练
分词器使用Huggingface的 Tokenizers 库进行训练。具体使用了 BertWordPieceTokenizer,词汇表大小设置为 30000。训练时使用了采样率为 1/10 的数据,并按日期进行分层采样,以确保更均匀的采样。
BERT模型预训练
KcBERT Base配置
{
"max_position_embeddings": 300,
"hidden_dropout_prob": 0.1,
"hidden_act": "gelu",
"initializer_range": 0.02,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30000,
"hidden_size": 768,
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"num_attention_heads": 12,
"intermediate_size": 3072,
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert"
}
KcBERT Large配置
{
"type_vocab_size": 2,
"initializer_range": 0.02,
"max_position_embeddings": 300,
"vocab_size": 30000,
"hidden_size": 1024,
"hidden_dropout_prob": 0.1,
"model_type": "bert",
"directionality": "bidi",
"pad_token_id": 0,
"layer_norm_eps": 1e-12,
"hidden_act": "gelu",
"num_hidden_layers": 24,
"num_attention_heads": 16,
"attention_probs_dropout_prob": 0.1,
"intermediate_size": 4096,
"architectures": [
"BertForMaskedLM"
]
}
BERT模型配置使用了Base和Large的默认设置(如MLM 15%等)。使用TPU v3-8 分别进行了3天和N天(Large模型仍在训练中)的训练。目前在Huggingface上公开的模型是经过100万步训练的检查点。
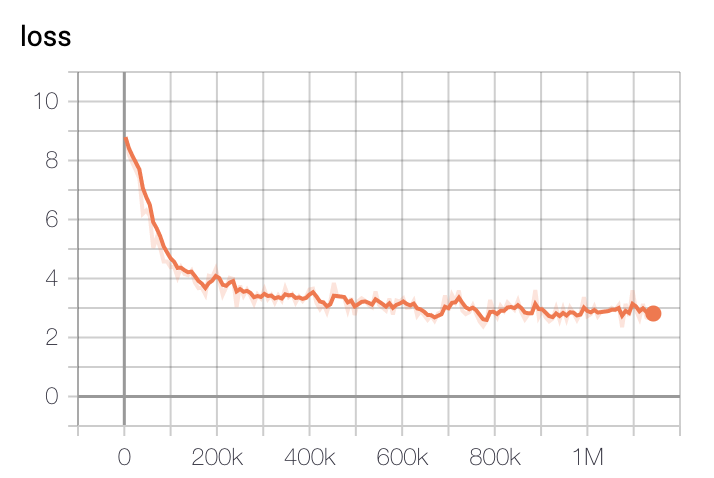
模型训练损失在初始200k步时下降最快,400k步后逐渐减缓。
- 基础模型损失
- 大型模型损失
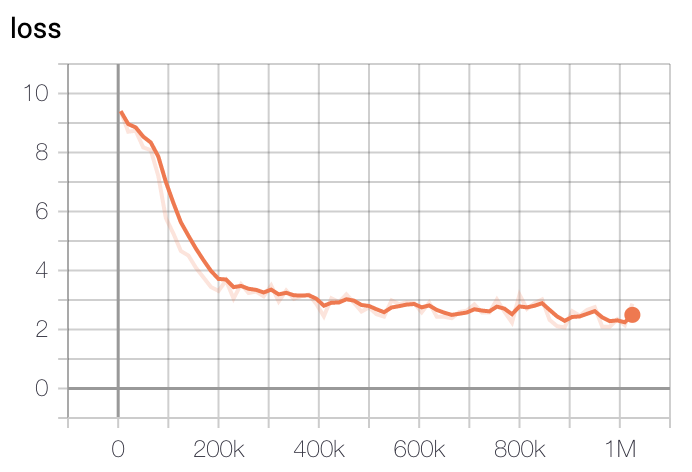
训练使用了GCP的TPU v3-8,基础模型训练时间约为2.5天,大型模型训练约5天后选择损失最低的检查点。
示例
HuggingFace MASK LM
你可以在 HuggingFace kcbert-base模型 中进行如下测试:
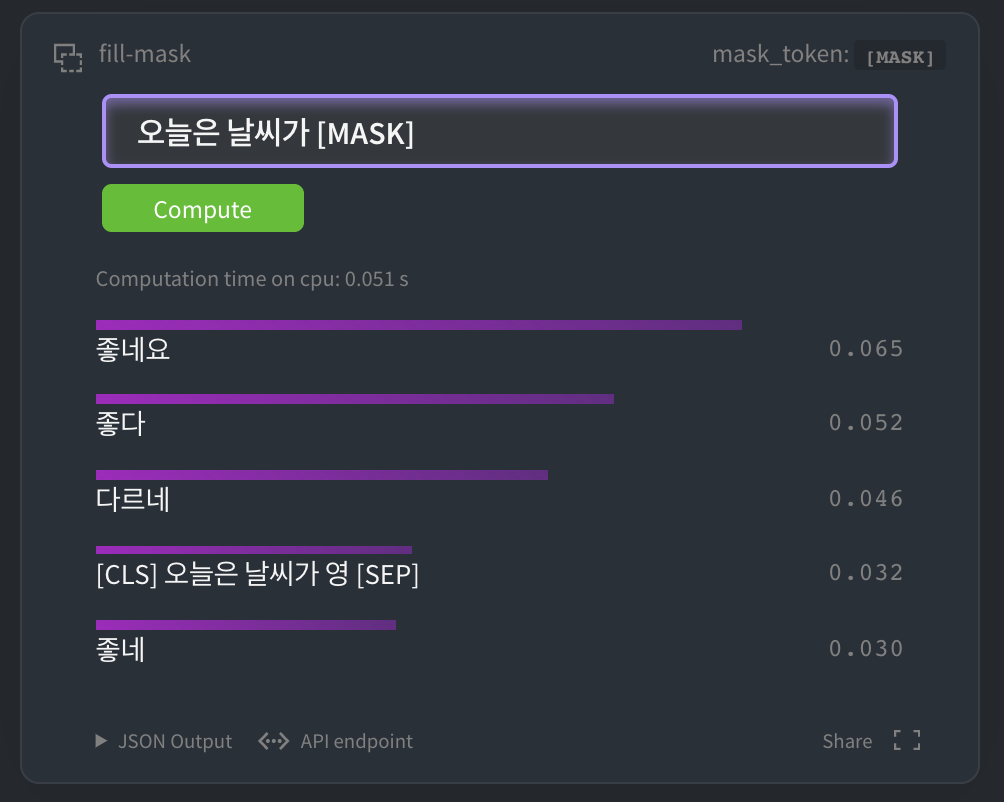
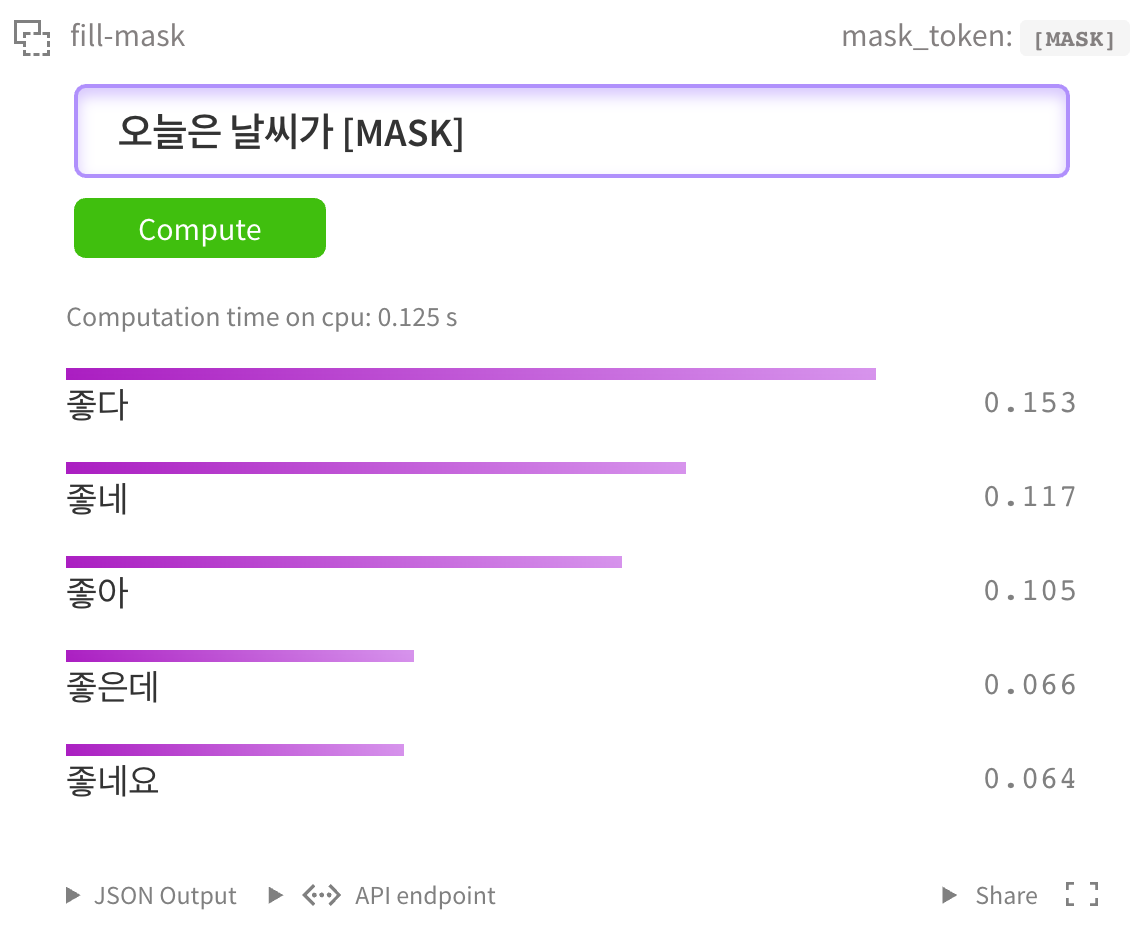
当然,你也可以在 kcbert-large模型 中进行测试:
NSMC二分类
我们使用 Naver电影评论语料库 数据集进行了微调,并简单测试了性能。
基础模型微调代码可以在
![]() 中直接运行。
中直接运行。
大型模型微调代码可以在
![]() 中直接运行。
中直接运行。
- GPU(P100 x1)每个epoch约需2 - 3小时,TPU每个epoch在1小时内完成。
- GPU(RTX Titan x4)每个epoch约需30分钟。
- 示例代码使用 pytorch-lightning 开发。
实验结果
- KcBERT-Base模型实验结果:验证准确率为
.8905
- KcBERT-Large模型实验结果:验证准确率为
.9089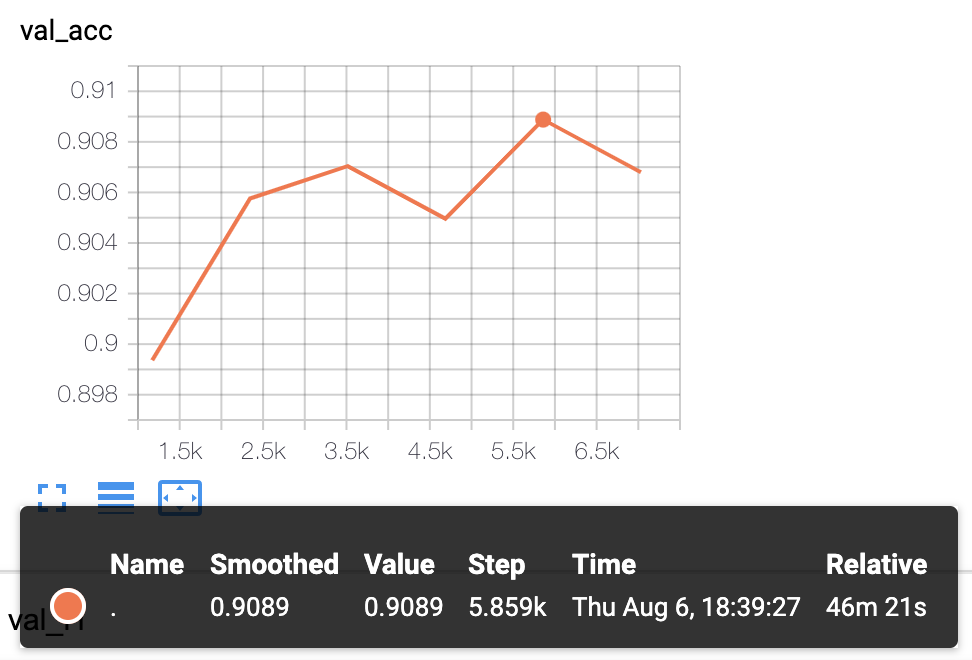
我们计划对更多下游任务进行测试并公开结果。
🔧 技术细节
预训练数据
KcBERT使用了2019年1月1日至2020年6月15日期间发布的评论较多的新闻文章的评论和回复作为预训练数据。这些数据包含了大量的口语化表达、新造词和拼写错误,与传统的韩语语料库有所不同。
预处理步骤
为了处理这些非标准的文本数据,KcBERT进行了一系列的预处理步骤,包括:
- 字符过滤:使用正则表达式过滤掉非韩语、英语、特殊字符和表情符号的字符。
- 重复字符压缩:将连续重复的字符压缩为两个字符,例如
ㅋㅋㅋㅋㅋ压缩为ㅋㅋ。 - 大小写敏感:KcBERT是一个大小写敏感的模型,因此在预处理过程中保留了英语单词的大小写。
- 短文本过滤:过滤掉长度小于10个字符的文本,因为这些文本通常不包含足够的信息。
- 去重:去除重复的评论,以减少数据的冗余。
分词器训练
KcBERT使用了Huggingface的 Tokenizers 库中的 BertWordPieceTokenizer 进行分词器的训练。训练过程中,使用了采样率为1/10的数据,并按日期进行分层采样,以确保训练数据的多样性。最终的词汇表大小为30,000。
模型架构和训练
KcBERT基于标准的BERT架构,有Base和Large两个版本。Base版本有12层,隐藏层大小为768;Large版本有24层,隐藏层大小为1024。模型使用了MLM(Masked Language Modeling)任务进行预训练,训练过程中使用了TPU v3-8进行加速。
性能评估
KcBERT在多个韩语自然语言处理任务上进行了评估,包括NSMC(Naver Sentiment Movie Corpus)、Naver NER(Named Entity Recognition)、PAWS(Paraphrase Adversaries from Word Scrambling)、KorNLI(Korean Natural Language Inference)、KorSTS(Korean Semantic Textual Similarity)、Question Pair和KorQuaD(Korean Question Answering Dataset)。实验结果表明,KcBERT在这些任务上取得了较好的性能。
📄 许可证
本项目采用Apache-2.0许可证。
引用标注
引用KcBERT时,请使用以下格式:
@inproceedings{lee2020kcbert,
title={KcBERT: Korean Comments BERT},
author={Lee, Junbum},
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
pages={437--440},
year={2020}
}
- 论文集下载链接:http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (或者 http://hclt.kr/symp/?lnb=conference )
致谢
KcBERT模型的训练得到了 TFRC 项目的GCP/TPU资源支持。感谢 Monologg 在模型训练过程中提供的宝贵建议。