%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 KcBERT:韓國語評論BERT
KcBERT是一個預訓練的BERT模型,為了應用於具有特定特徵的數據集,它從Naver新聞中收集評論和回覆,從頭開始訓練分詞器和BERT模型。該模型可以通過Huggingface的Transformers庫輕鬆加載和使用。
🚀 快速開始
KcBERT可以通過Huggingface的Transformers庫輕鬆加載和使用,無需額外下載文件。以下是使用示例:
from transformers import AutoTokenizer, AutoModelWithLMHead
# 基礎模型(108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# 大型模型(334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
✨ 主要特性
- 針對特定數據優化:大多數公開的韓語BERT模型是基於韓語維基百科、新聞文章、書籍等經過良好整理的數據進行訓練的。而KcBERT為了應用於具有特定特徵的數據集,從Naver新聞中收集評論和回覆,從頭開始訓練分詞器和BERT模型。
- 易於使用:可以通過Huggingface的Transformers庫輕鬆加載和使用,無需額外下載文件。
📦 安裝指南
依賴項
pytorch <= 1.8.0transformers ~= 3.0.1(也兼容transformers ~= 4.0.0)emoji ~= 0.6.0soynlp ~= 0.0.493
💻 使用示例
基礎用法
from transformers import AutoTokenizer, AutoModelWithLMHead
# 基礎模型(108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# 大型模型(334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
高級用法
你可以在以下鏈接中找到微調代碼:https://github.com/Beomi/KcBERT-finetune 。
📚 詳細文檔
KcBERT性能
| 屬性 | 詳情 |
|---|---|
| 模型類型 | KcBERT-Base、KcBERT-Large |
| 訓練數據 | 2019.01.01 ~ 2020.06.15期間撰寫的評論較多的新聞文章的評論和回覆 |
| 評估指標 | NSMC(acc)、Naver NER(F1)、PAWS(acc)、KorNLI(acc)、KorSTS(spearman)、Question Pair(acc)、KorQuaD (Dev)(EM/F1) |
具體性能數據如下:
| 模型 | 大小(容量) | NSMC (acc) |
Naver NER (F1) |
PAWS (acc) |
KorNLI (acc) |
KorSTS (spearman) |
Question Pair (acc) |
KorQuaD (Dev) (EM/F1) |
|---|---|---|---|---|---|---|---|---|
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
*HanBERT的大小是Bert模型和分詞器數據庫的總和。
*結果是在保持配置設置不變的情況下運行得到的,如果進行額外的超參數調整,可能會獲得更好的性能。
預訓練和微調Colab鏈接彙總
預訓練數據
預訓練代碼
在Colab中使用TPU進行KcBERT預訓練:
![]()
微調示例
- KcBERT-Base 在NSMC上使用PyTorch-Lightning進行微調(Colab):

- KcBERT-Large 在NSMC上使用PyTorch-Lightning進行微調(Colab):
以上兩個代碼除了預訓練模型(base,large)和批量大小不同外,其餘代碼完全相同。
訓練數據與預處理
原始數據
訓練數據是2019.01.01至2020.06.15期間撰寫的評論較多的新聞文章的評論和回覆。數據大小約為15.4GB(僅提取文本),包含超過1.1億個句子。
預處理
為了進行PLM訓練,進行了以下預處理步驟:
- 包含韓語、英語、特殊字符和表情符號:使用正則表達式將韓語、英語、特殊字符和表情符號納入訓練範圍。同時,將韓語範圍指定為
ㄱ-ㅎ가-힣,排除了ㄱ-힣內的漢字。 - 縮寫評論中的重複字符串:將重複的字符(如
ㅋㅋㅋㅋㅋ)合併為ㅋㅋ。 - 大小寫敏感模型:KcBERT是一個大小寫敏感的模型,對於英文保留大小寫。
- 刪除10個字符以下的文本:由於10個字符以下的文本通常由單個單詞組成,因此排除了這部分文本。
- 去重:合併重複的評論以去除重複內容。
最終生成的訓練數據大小為12.5GB,包含8900萬個句子。你可以使用以下命令通過pip安裝所需庫,並使用 clean 函數進行清理,以提高下游任務的性能(減少 [UNK]):
pip install soynlp emoji
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
emojis = ''.join(emojis)
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
清理後的數據(在Kaggle上發佈)
你可以從以下Kaggle數據集下載使用上述 clean 函數清理後的12GB文本文件:Kaggle數據集
分詞器訓練
分詞器使用Huggingface的 Tokenizers 庫進行訓練。具體使用了 BertWordPieceTokenizer,詞彙表大小設置為 30000。訓練時使用了採樣率為 1/10 的數據,並按日期進行分層採樣,以確保更均勻的採樣。
BERT模型預訓練
KcBERT Base配置
{
"max_position_embeddings": 300,
"hidden_dropout_prob": 0.1,
"hidden_act": "gelu",
"initializer_range": 0.02,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30000,
"hidden_size": 768,
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"num_attention_heads": 12,
"intermediate_size": 3072,
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert"
}
KcBERT Large配置
{
"type_vocab_size": 2,
"initializer_range": 0.02,
"max_position_embeddings": 300,
"vocab_size": 30000,
"hidden_size": 1024,
"hidden_dropout_prob": 0.1,
"model_type": "bert",
"directionality": "bidi",
"pad_token_id": 0,
"layer_norm_eps": 1e-12,
"hidden_act": "gelu",
"num_hidden_layers": 24,
"num_attention_heads": 16,
"attention_probs_dropout_prob": 0.1,
"intermediate_size": 4096,
"architectures": [
"BertForMaskedLM"
]
}
BERT模型配置使用了Base和Large的默認設置(如MLM 15%等)。使用TPU v3-8 分別進行了3天和N天(Large模型仍在訓練中)的訓練。目前在Huggingface上公開的模型是經過100萬步訓練的檢查點。
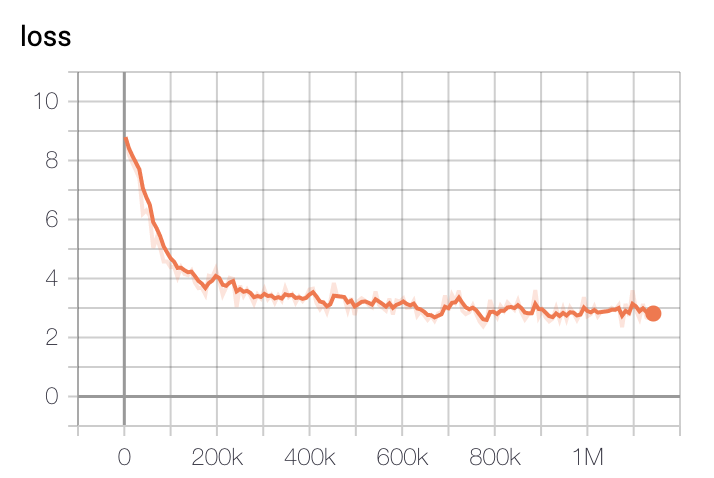
模型訓練損失在初始200k步時下降最快,400k步後逐漸減緩。
- 基礎模型損失
- 大型模型損失
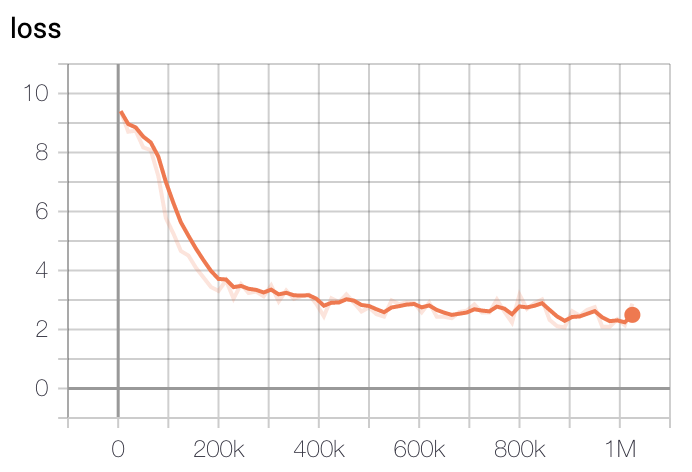
訓練使用了GCP的TPU v3-8,基礎模型訓練時間約為2.5天,大型模型訓練約5天后選擇損失最低的檢查點。
示例
HuggingFace MASK LM
你可以在 HuggingFace kcbert-base模型 中進行如下測試:
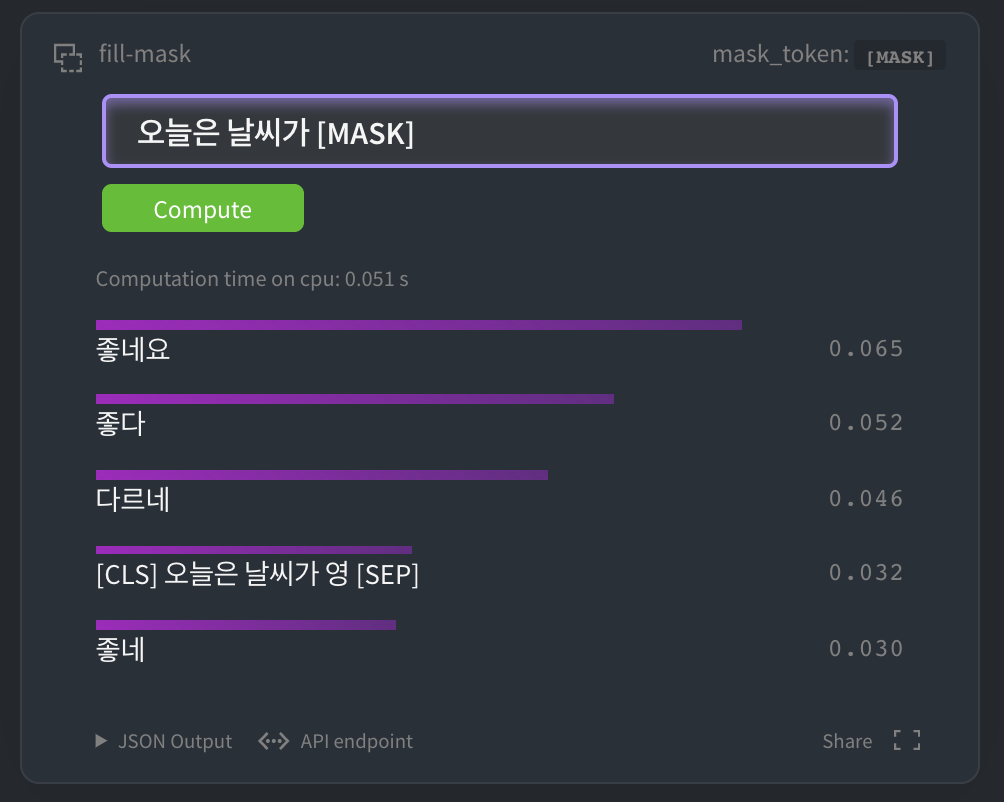
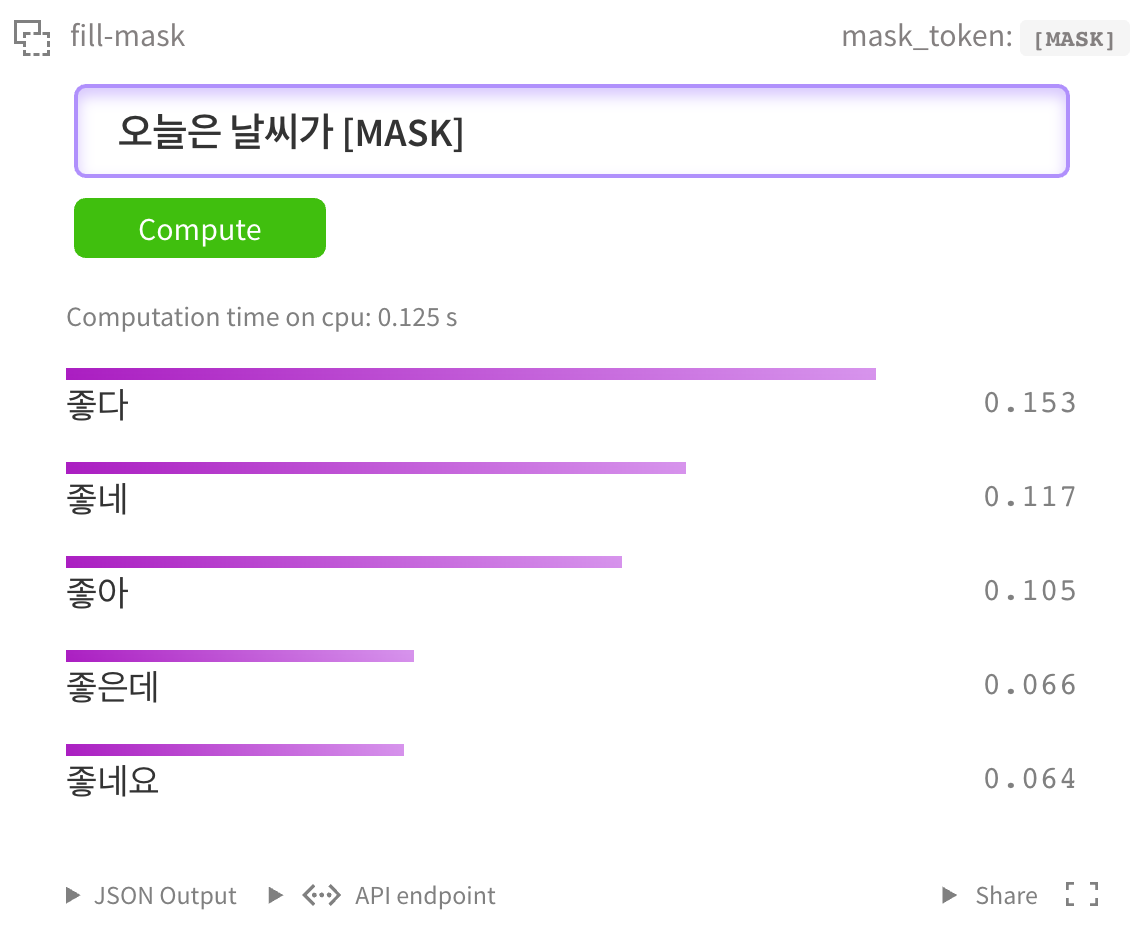
當然,你也可以在 kcbert-large模型 中進行測試:
NSMC二分類
我們使用 Naver電影評論語料庫 數據集進行了微調,並簡單測試了性能。
基礎模型微調代碼可以在
![]() 中直接運行。
中直接運行。
大型模型微調代碼可以在
![]() 中直接運行。
中直接運行。
- GPU(P100 x1)每個epoch約需2 - 3小時,TPU每個epoch在1小時內完成。
- GPU(RTX Titan x4)每個epoch約需30分鐘。
- 示例代碼使用 pytorch-lightning 開發。
實驗結果
- KcBERT-Base模型實驗結果:驗證準確率為
.8905
- KcBERT-Large模型實驗結果:驗證準確率為
.9089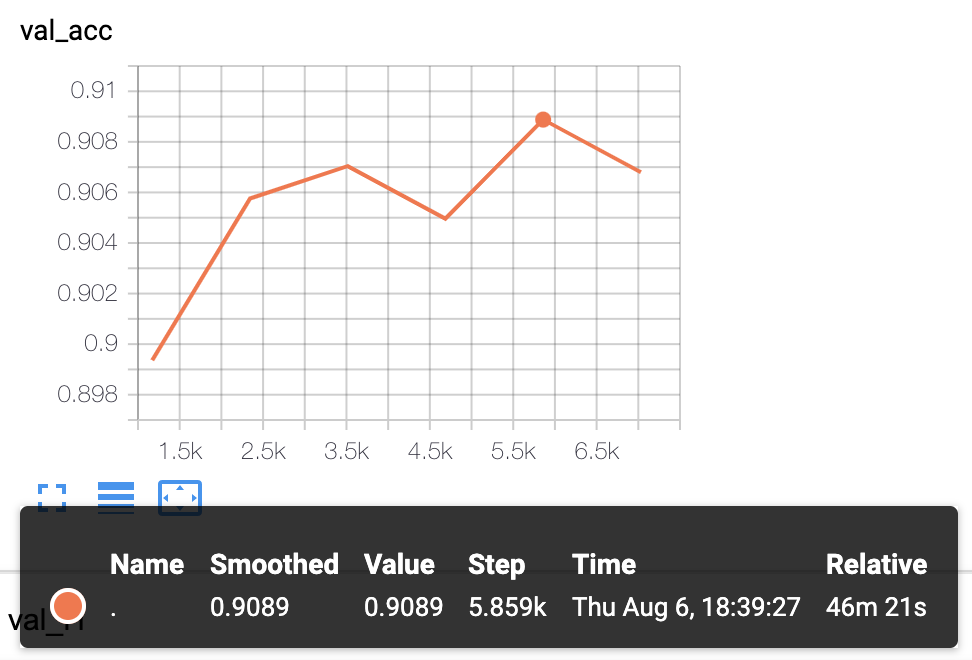
我們計劃對更多下游任務進行測試並公開結果。
🔧 技術細節
預訓練數據
KcBERT使用了2019年1月1日至2020年6月15日期間發佈的評論較多的新聞文章的評論和回覆作為預訓練數據。這些數據包含了大量的口語化表達、新造詞和拼寫錯誤,與傳統的韓語語料庫有所不同。
預處理步驟
為了處理這些非標準的文本數據,KcBERT進行了一系列的預處理步驟,包括:
- 字符過濾:使用正則表達式過濾掉非韓語、英語、特殊字符和表情符號的字符。
- 重複字符壓縮:將連續重複的字符壓縮為兩個字符,例如
ㅋㅋㅋㅋㅋ壓縮為ㅋㅋ。 - 大小寫敏感:KcBERT是一個大小寫敏感的模型,因此在預處理過程中保留了英語單詞的大小寫。
- 短文本過濾:過濾掉長度小於10個字符的文本,因為這些文本通常不包含足夠的信息。
- 去重:去除重複的評論,以減少數據的冗餘。
分詞器訓練
KcBERT使用了Huggingface的 Tokenizers 庫中的 BertWordPieceTokenizer 進行分詞器的訓練。訓練過程中,使用了採樣率為1/10的數據,並按日期進行分層採樣,以確保訓練數據的多樣性。最終的詞彙表大小為30,000。
模型架構和訓練
KcBERT基於標準的BERT架構,有Base和Large兩個版本。Base版本有12層,隱藏層大小為768;Large版本有24層,隱藏層大小為1024。模型使用了MLM(Masked Language Modeling)任務進行預訓練,訓練過程中使用了TPU v3-8進行加速。
性能評估
KcBERT在多個韓語自然語言處理任務上進行了評估,包括NSMC(Naver Sentiment Movie Corpus)、Naver NER(Named Entity Recognition)、PAWS(Paraphrase Adversaries from Word Scrambling)、KorNLI(Korean Natural Language Inference)、KorSTS(Korean Semantic Textual Similarity)、Question Pair和KorQuaD(Korean Question Answering Dataset)。實驗結果表明,KcBERT在這些任務上取得了較好的性能。
📄 許可證
本項目採用Apache-2.0許可證。
引用標註
引用KcBERT時,請使用以下格式:
@inproceedings{lee2020kcbert,
title={KcBERT: Korean Comments BERT},
author={Lee, Junbum},
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
pages={437--440},
year={2020}
}
- 論文集下載鏈接:http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (或者 http://hclt.kr/symp/?lnb=conference )
致謝
KcBERT模型的訓練得到了 TFRC 項目的GCP/TPU資源支持。感謝 Monologg 在模型訓練過程中提供的寶貴建議。