%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 KcBERT: 韓国語コメント用BERT
KcBERTは、韓国語のニュースコメントや返信コメントを収集し、トークナイザーとBERTモデルを最初から学習した事前学習済みBERTモデルです。これにより、未整形のデータや口語的な表現、新語、誤字などが多いデータセットにも適用できます。また、HuggingfaceのTransformersライブラリを通じて簡単に利用できます。
🚀 クイックスタート
KcBERTを使い始めるには、以下の手順に従ってください。
必要条件
pytorch <= 1.8.0transformers ~= 3.0.1transformers ~= 4.0.0も互換性があります。
emoji ~= 0.6.0soynlp ~= 0.0.493
コード例
from transformers import AutoTokenizer, AutoModelWithLMHead
# Base Model (108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# Large Model (334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
✨ 主な機能
- 未整形データへの適用性: 韓国語のニュースコメントや返信コメントなど、未整形のデータや口語的な表現、新語、誤字などが多いデータセットにも適用できます。
- 簡単な利用: HuggingfaceのTransformersライブラリを通じて簡単に利用できます。
- 高性能: 様々なタスクで高い性能を発揮します。
📦 インストール
必要なライブラリをインストールするには、以下のコマンドを実行してください。
pip install soynlp emoji
💻 使用例
HuggingFace MASK LM
HuggingFace kcbert-baseモデル で以下のようにテストできます。
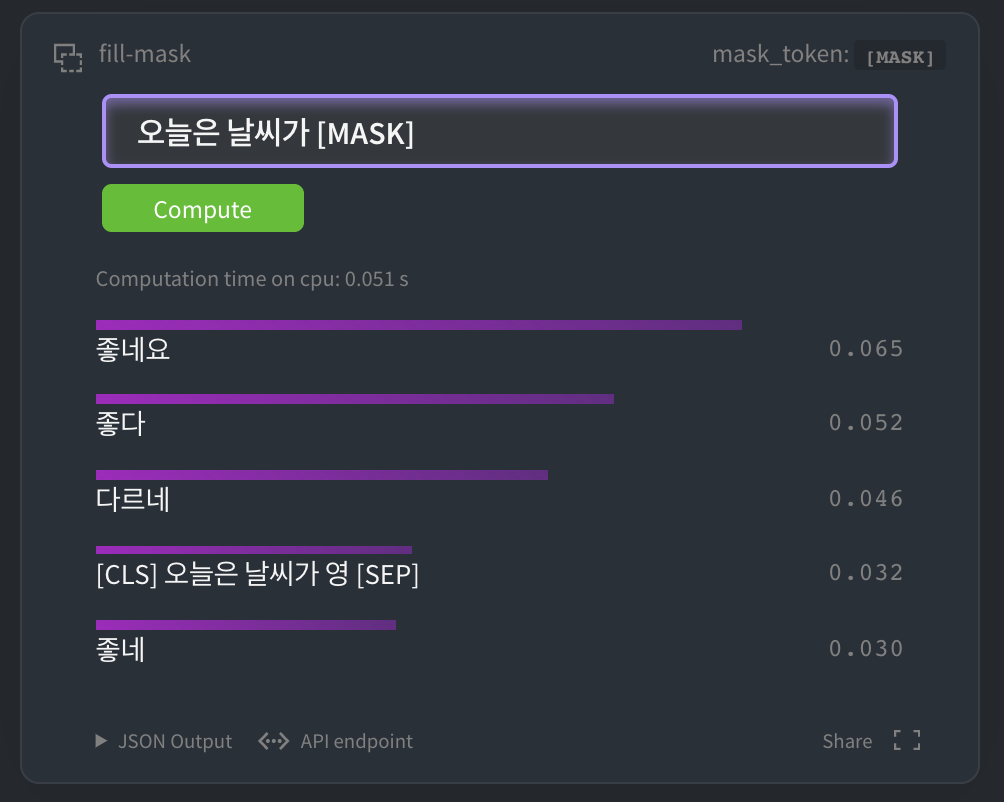
もちろん kcbert-largeモデル でもテストできます。
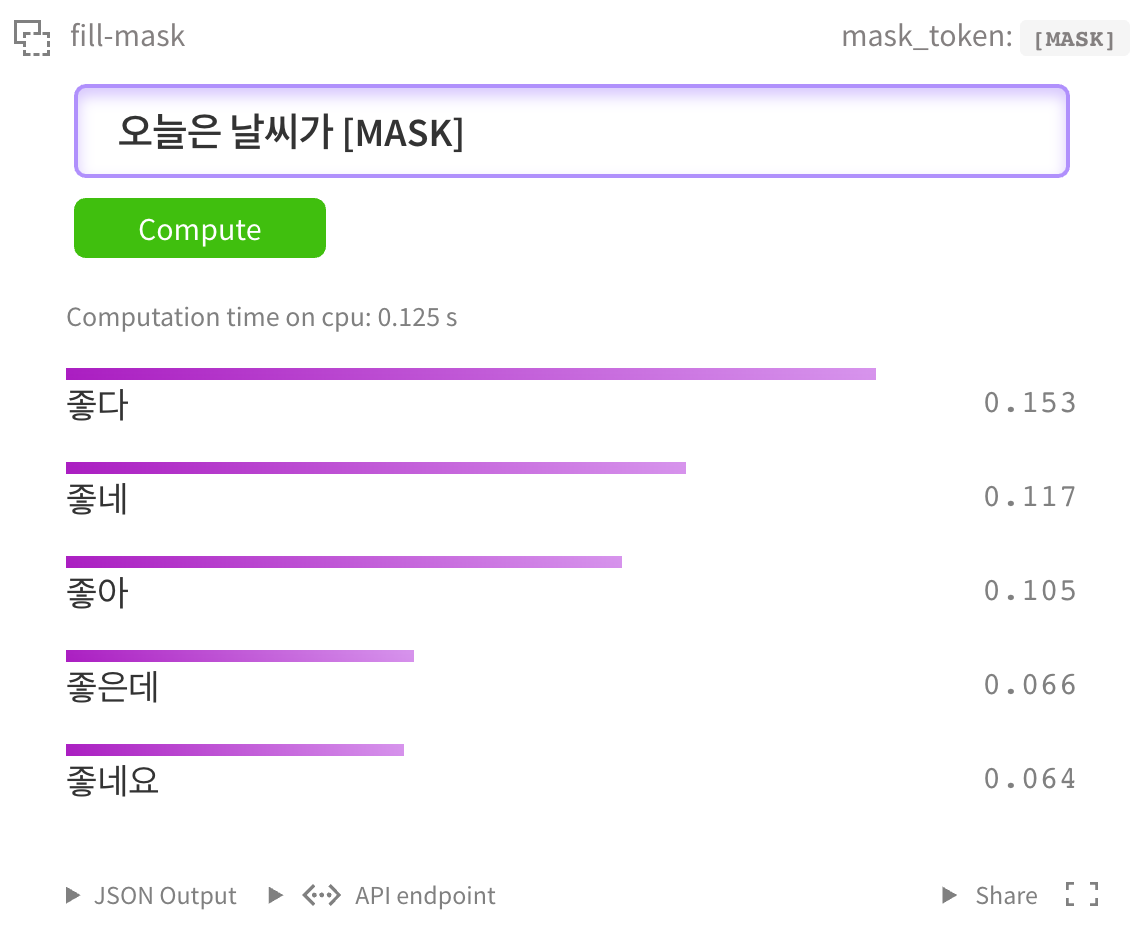
NSMC Binary Classification
ネイバ映画評コーパス データセットを対象にFine Tuningを行い、性能を簡単にテストしました。
BaseモデルをFine Tuneするコードは
![]() で直接実行できます。
で直接実行できます。
LargeモデルをFine Tuneするコードは
![]() で直接実行できます。
で直接実行できます。
- GPUはP100 x1台基準で1エポックに2 - 3時間、TPUは1エポックに1時間以内です。
- GPU RTX Titan x4台基準で30分/エポックです。
- サンプルコードは pytorch-lightning で開発されています。
実験結果
- KcBERT-Baseモデルの実験結果: Val acc
.8905
- KcBERT-Largeモデルの実験結果: Val acc
.9089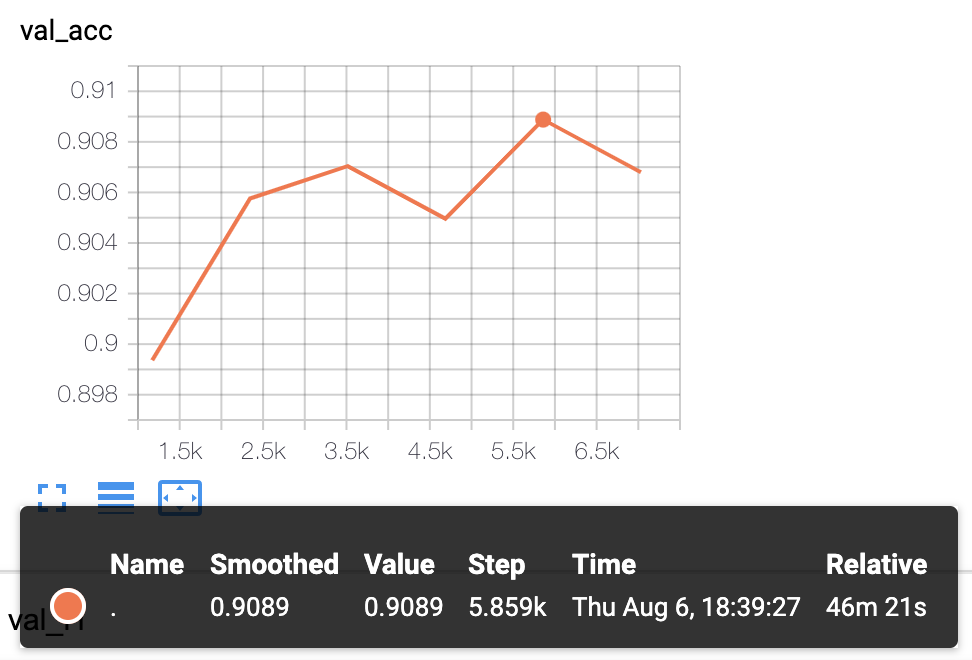
より多様なDownstream Taskについてテストを行い、公開する予定です。
📚 ドキュメント
KcBERTの性能
Finetuneコードは https://github.com/Beomi/KcBERT-finetune で確認できます。
| サイズ (容量) |
NSMC (acc) |
Naver NER (F1) |
PAWS (acc) |
KorNLI (acc) |
KorSTS (spearman) |
Question Pair (acc) |
KorQuaD (Dev) (EM/F1) |
|
|---|---|---|---|---|---|---|---|---|
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
*HanBERTのサイズはBertモデルとTokenizer DBを合計したものです。
*configの設定をそのまま適用した結果であり、ハイパーパラメーターのチューニングを追加すると、より良い性能が得られる可能性があります。
事前学習と微調整のColabリンク集
事前学習データ
事前学習コード
ColabでTPUを使用してKcBERTの事前学習を試す:
![]()
微調整サンプル
KcBERT-Base NSMCのPyTorch-Lightningを使用した微調整 (Colab)
![]()
KcBERT-Large NSMCのPyTorch-Lightningを使用した微調整 (Colab)
![]()
上記の2つのコードは、事前学習モデル(base, large)とバッチサイズのみが異なり、その他のコードは完全に同じです。
学習データと前処理
生データ
学習データは、2019年1月1日から2020年6月15日までに書かれた コメントの多いニュース 記事の コメントと返信コメント をすべて収集したデータです。
データサイズは、テキストのみを抽出した場合、約15.4GBで、1億1000万以上の文 で構成されています。
前処理
PLM学習のために行った前処理の手順は以下の通りです。
- 韓国語、英語、特殊文字、そして絵文字(🥳)まで!
正規表現を使用して、韓国語、英語、特殊文字を含め、絵文字まで学習対象に含めました。
一方、韓国語の範囲を
ㄱ - ㅎ가 - 힣に指定し、ㄱ - 힣内の漢字を除外しました。 - コメント内の重複文字列の省略
ㅋㅋㅋㅋㅋのような重複文字をㅋㅋのようにまとめました。 - Casedモデル KcBERTは、英語については大文字と小文字を区別するCasedモデルです。
- 文字単位で10文字以下の削除 10文字未満のテキストは、多くの場合、単一の単語で構成されているため、この部分を除外しました。
- 重複の削除 重複して書かれたコメントを削除するために、重複するコメントを1つにまとめました。
これによって作成された最終的な学習データは、12.5GB、8900万の文 です。
以下のコマンドでpipを使用してインストールした後、以下のclean関数を使用してクリーニングを行うと、下流タスクでより良い性能が得られます。([UNK] の減少)
pip install soynlp emoji
以下の clean 関数をテキストデータに適用してください。
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
emojis = ''.join(emojis)
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
クリーニング済みデータ (Kaggleで公開)
元のデータを上記の clean 関数でクリーニングした12GBのtxtファイルは、以下のKaggleデータセットからダウンロードできます。
https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments
Tokenizerの学習
Tokenizerは、Huggingfaceの Tokenizers ライブラリを使用して学習されました。
その中でも BertWordPieceTokenizer を使用して学習を行い、語彙サイズは 30000 としました。
Tokenizerの学習には、1/10 にサンプリングしたデータを使用し、より均等にサンプリングするために日付ごとに層化を指定して学習を行いました。
BERTモデルの事前学習
- KcBERT Baseの設定
{
"max_position_embeddings": 300,
"hidden_dropout_prob": 0.1,
"hidden_act": "gelu",
"initializer_range": 0.02,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30000,
"hidden_size": 768,
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"num_attention_heads": 12,
"intermediate_size": 3072,
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert"
}
- KcBERT Largeの設定
{
"type_vocab_size": 2,
"initializer_range": 0.02,
"max_position_embeddings": 300,
"vocab_size": 30000,
"hidden_size": 1024,
"hidden_dropout_prob": 0.1,
"model_type": "bert",
"directionality": "bidi",
"pad_token_id": 0,
"layer_norm_eps": 1e-12,
"hidden_act": "gelu",
"num_hidden_layers": 24,
"num_attention_heads": 16,
"attention_probs_dropout_prob": 0.1,
"intermediate_size": 4096,
"architectures": [
"BertForMaskedLM"
]
}
BERTモデルの設定は、BaseとLargeの基本設定値をそのまま使用しました。(MLM 15%など)
TPU v3 - 8 を使用して、それぞれ3日間、N日間(Largeは学習中)学習を行い、現在Huggingfaceに公開されているモデルは、100万ステップ学習したチェックポイントがアップロードされています。
モデルの学習損失は、ステップに応じて、初期の20万ステップで最も急速に減少し、40万ステップ以降は徐々に減少することがわかります。
-
Baseモデルの損失
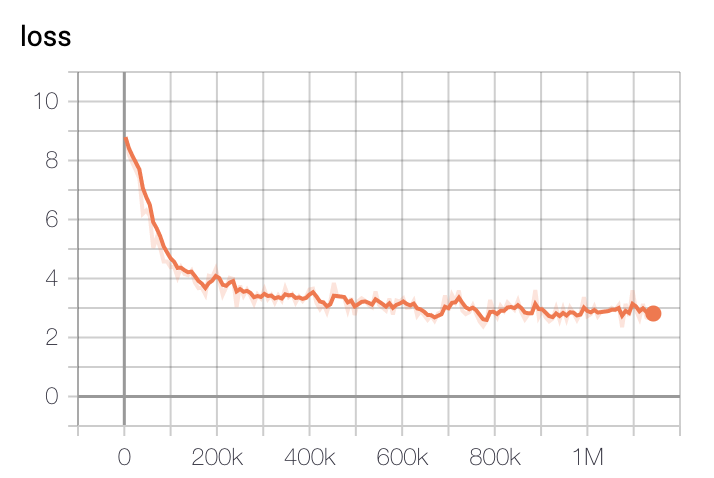
-
Largeモデルの損失
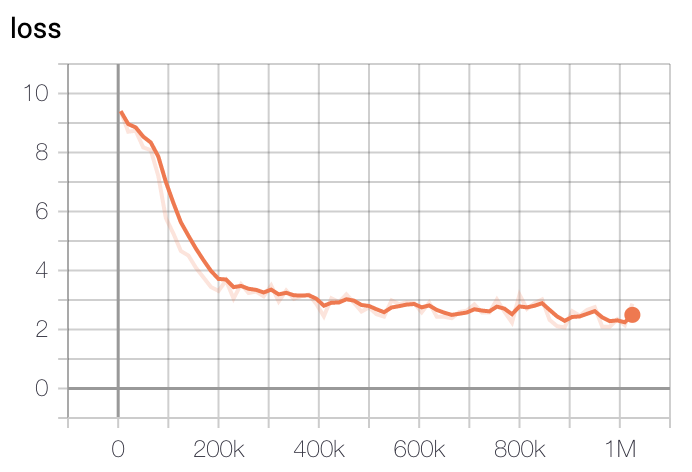
学習はGCPのTPU v3 - 8を使用して行われ、学習時間はBaseモデルを基準に約2.5日間でした。Largeモデルは約5日間学習した後、最も低い損失を持つチェックポイントを選択しました。
🔧 技術詳細
コードの依存関係
pytorch <= 1.8.0transformers ~= 3.0.1transformers ~= 4.0.0も互換性があります。
emoji ~= 0.6.0soynlp ~= 0.0.493
モデルの設定
KcBERT BaseとKcBERT Largeの設定については、上記の「BERTモデルの事前学習」セクションを参照してください。
前処理の詳細
前処理の詳細については、上記の「学習データと前処理」セクションを参照してください。
📄 ライセンス
このプロジェクトはApache 2.0ライセンスの下でライセンスされています。
インストール
KcBERTを使用するには、以下の依存関係をインストールする必要があります。
pip install soynlp emoji
インポート
以下のコードを使用して、KcBERTのトークナイザーとモデルをインポートできます。
from transformers import AutoTokenizer, AutoModelWithLMHead
# Base Model (108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# Large Model (334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
インスタンス化
上記のコードを実行すると、トークナイザーとモデルがインスタンス化されます。
サンプルコード
HuggingFace MASK LM
HuggingFace kcbert-baseモデル で以下のようにテストできます。
もちろん kcbert-largeモデル でもテストできます。
NSMC Binary Classification
ネイバ映画評コーパス データセットを対象にFine Tuningを行い、性能を簡単にテストしました。
BaseモデルをFine Tuneするコードは
![]() で直接実行できます。
で直接実行できます。
LargeモデルをFine Tuneするコードは
![]() で直接実行できます。
で直接実行できます。
- GPUはP100 x1台基準で1エポックに2 - 3時間、TPUは1エポックに1時間以内です。
- GPU RTX Titan x4台基準で30分/エポックです。
- サンプルコードは pytorch-lightning で開発されています。
実験結果
- KcBERT-Baseモデルの実験結果: Val acc
.8905 - KcBERT-Largeモデルの実験結果: Val acc
.9089
より多様なDownstream Taskについてテストを行い、公開する予定です。
インポート
from transformers import AutoTokenizer, AutoModelWithLMHead
# Base Model (108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# Large Model (334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
インスタンス化
上記のコードを実行すると、トークナイザーとモデルがインスタンス化されます。
サンプルコード
HuggingFace MASK LM
HuggingFace kcbert-baseモデル で以下のようにテストできます。
もちろん kcbert-largeモデル でもテストできます。
NSMC Binary Classification
ネイバ映画評コーパス データセットを対象にFine Tuningを行い、性能を簡単にテストしました。
BaseモデルをFine Tuneするコードは
![]() で直接実行できます。
で直接実行できます。
LargeモデルをFine Tuneするコードは
![]() で直接実行できます。
で直接実行できます。
- GPUはP100 x1台基準で1エポックに2 - 3時間、TPUは1エポックに1時間以内です。
- GPU RTX Titan x4台基準で30分/エポックです。
- サンプルコードは pytorch-lightning で開発されています。
実験結果
- KcBERT-Baseモデルの実験結果: Val acc
.8905 - KcBERT-Largeモデルの実験結果: Val acc
.9089
より多様なDownstream Taskについてテストを行い、公開する予定です。
引用表記
KcBERTを引用する場合は、以下の形式を使用してください。
@inproceedings{lee2020kcbert,
title={KcBERT: Korean Comments BERT},
author={Lee, Junbum},
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
pages={437--440},
year={2020}
}
- 論文集のダウンロードリンク: http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (*または http://hclt.kr/symp/?lnb=conference )
謝辞
KcBERTモデルの学習に使用されたGCP/TPU環境は、TFRC プログラムの支援を受けています。
モデルの学習過程で多くのアドバイスをくれた Monologg 氏に感謝します。