%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 GLM-4.1V-9B-Thinking-AWQ
本倉庫託管了GLM-4.1V-9B-Thinking的AWQ量化版本。GLM-4.1V-9B-Thinking是一款強大的視覺語言模型(VLM),旨在實現多模態理解和推理。
該模型在論文GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning中被提出。
官方GitHub倉庫:https://github.com/THUDM/GLM-4.1V-Thinking
基礎模型:ZhipuAI/GLM-4.1V-9B-Thinking
🚀 快速開始
模型更新日期
2025-07-03
1. 首次commit
2. 確定支持1、2、4卡的`tensor-parallel-size`啟動
依賴項
vllm==0.9.2
⚠️ 重要提示
2025年7月3日的臨時安裝命令如下:
pip3 install -r requirements.txt
git clone https://github.com/zRzRzRzRzRzRzR/vllm.git
cd vllm
git checkout glm4_1-v
VLLM_USE_PRECOMPILED=1 pip install --editable .
模型列表
| 文件大小 | 最近更新時間 |
|---|---|
6.9GB |
2025-07-03 |
模型下載
from modelscope import snapshot_download
snapshot_download('dengcao/GLM-4.1V-9B-Thinking-AWQ', cache_dir="本地路徑")
👋 加入我們的 Discord
📖 查看GLM-4.1V-9B-Thinking 論文。
💡 在 Hugging Face 或 ModelScope 上嘗試GLM-4.1V-9B-Thinking的在線演示。
📍 在 智譜基礎模型開放平臺 使用GLM-4.1V-9B-Thinking API。
✨ 主要特性
視覺語言模型(VLM)已成為智能系統的基礎組成部分。隨著現實世界中的AI任務日益複雜,VLM必須超越基本的多模態感知,提升其在複雜任務中的推理能力。這包括提高準確性、全面性和智能性,以實現複雜問題解決、長上下文理解和多模態智能體等應用。
基於GLM-4-9B-0414基礎模型,我們推出了新的開源VLM模型GLM-4.1V-9B-Thinking,旨在探索視覺語言模型推理能力的上限。通過引入“思維範式”並利用強化學習,該模型顯著提升了其能力。在100億參數的VLM中,它達到了領先水平,在18個基準任務上與甚至超過了720億參數的Qwen-2.5-VL-72B。我們還開源了基礎模型GLM-4.1V-9B-Base,以支持對VLM能力邊界的進一步研究。
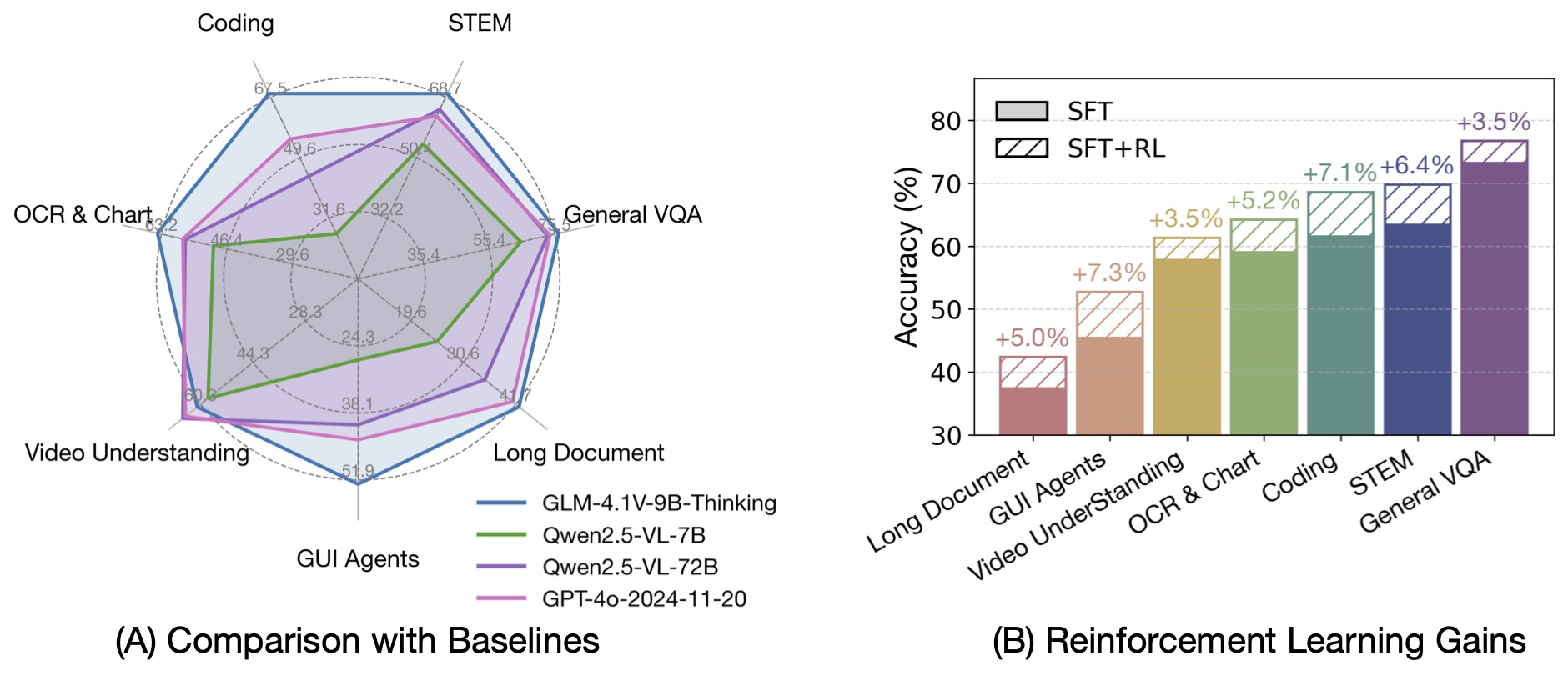
與上一代模型CogVLM2和GLM-4V系列相比,GLM-4.1V-Thinking有以下改進:
- 該系列中首個專注於推理的模型,不僅在數學領域,而且在各個子領域都取得了世界領先的性能。
- 支持64k上下文長度。
- 處理任意寬高比和最高4K的圖像分辨率。
- 提供支持中英文雙語使用的開源版本。
📦 安裝指南
依賴項
vllm==0.9.2
⚠️ 重要提示
2025年7月3日的臨時安裝命令如下:
pip3 install -r requirements.txt
git clone https://github.com/zRzRzRzRzRzRzR/vllm.git
cd vllm
git checkout glm4_1-v
VLLM_USE_PRECOMPILED=1 pip install --editable .
💻 使用示例
模型推理
所有推理腳本都位於inference文件夾中,包括:
trans_infer_cli.py:一個使用transformers庫作為後端的命令行交互腳本,支持多輪對話。trans_infer_gradio.py:一個基於Gradio的Web UI腳本,使用transformers後端,支持圖像、視頻、PDF和PPT等多模態輸入。- 使用
vllm的OpenAI兼容API服務,vllm_api_request.py中提供了一個簡單的請求示例。
vllm serve THUDM/GLM-4.1V-9B-Thinking --limit-mm-per-prompt '{"image":32}' --allowed-local-media-path /
-
如果未指定
--limit-mm-per-prompt,則僅支持1張圖像。該模型每個輸入最多支持1個視頻或300張圖像,不支持同時輸入圖像和視頻。 -
必須設置
--allowed-local-media-path以允許訪問本地多模態輸入。 -
trans_infer_bench:用於GLM-4.1V-9B-Thinking推理的學術基準測試腳本。主要特點:- 如果思考超過8192個標記,會自動中斷思考並追加
</think><answer>以提示模型生成最終答案。 - 演示了基於視頻的輸入,對於其他模態,需要進行修改。
- 僅提供了
transformers版本。對於vllm,需要自定義實現以支持此邏輯。
- 如果思考超過8192個標記,會自動中斷思考並追加
-
vllm_request_gui_agent.py:此腳本演示瞭如何處理模型響應並構建用於GUI智能體用例的提示。它涵蓋了移動、桌面和Web環境的策略,可集成到您的應用框架中。有關GUI智能體的詳細文檔,請參閱此文件。 -
對於昇騰NPU推理,請查看此處。
模型微調
LLaMA-Factory現在支持對該模型進行微調。以下是一個使用兩張圖像的示例數據集。請像下面這樣在finetune.json文件中準備您的數據集:
[
{
"messages": [
{
"content": "<image>Who are they?",
"role": "user"
},
{
"content": "<think>
User ask me to observe the image and get the answer. I Know they are Kane and Gretzka from Bayern Munich.</think>
<answer>They're Kane and Gretzka from Bayern Munich.</answer>",
"role": "assistant"
},
{
"content": "<image>What are they doing?",
"role": "user"
},
{
"content": "<think>
I need to observe what this people are doing. Oh, They are celebrating on the soccer field.</think>
<answer>They are celebrating on the soccer field.</answer>",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg",
"mllm_demo_data/2.jpg"
]
}
]
<think> ... </think>內的內容將不存儲在對話歷史中,也不會在微調期間使用。<image>標籤將在預處理期間被實際圖像數據替換。
準備好數據集後,您可以使用標準的LLaMA-Factory管道進行微調。
📚 詳細文檔
模型信息
模型下載鏈接
| 模型 | 下載鏈接 | 模型類型 |
|---|---|---|
| GLM-4.1V-9B-Thinking | 🤗 Hugging Face 🤖 ModelScope |
推理模型 |
| GLM-4.1V-9B-Base | 🤗 Hugging Face 🤖 ModelScope |
基礎模型 |
該模型的算法實現可在官方transformers倉庫中找到。
運行時要求
推理
| 設備(單GPU) | 框架 | 最小內存 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
微調
以下結果基於使用LLaMA-Factory工具包進行的圖像微調。
| 設備(集群) | 策略 | 最小內存 / GPU數量 | 批量大小(每個GPU) | 凍結設置 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | 凍結VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | 凍結VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | 凍結VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | 不凍結 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | 不凍結 |
注意:使用Zero2進行微調可能會導致零損失,建議使用Zero3進行穩定訓練。
基準性能
基於GLM-4-9B-0414基礎模型,我們推出了新的開源VLM模型GLM-4.1V-9B-Thinking,它引入了“思維”範式並利用課程採樣強化學習(RLCS)全面提升了模型能力。在100億參數的視覺語言模型中,它達到了領先水平,在18個基準任務上與甚至超過了720億參數的Qwen-2.5-VL。我們還開源了基礎模型GLM-4.1V-9B-Base,以支持對視覺語言模型前沿的進一步研究。

🔧 技術細節
本倉庫代碼基於GLM-4-9B-0414基礎模型,通過引入“思維範式”和強化學習的方式,提升了模型的推理能力。具體實現細節可參考官方transformers倉庫。
📄 許可證
- 本倉庫中的代碼根據Apache License 2.0發佈。
- 模型GLM-4.1V-9B-Thinking和GLM-4.1V-9B-Base均根據MIT License許可。
引用
如果您認為我們的工作有幫助,請考慮引用以下論文:
@misc{glmvteam2025glm41vthinkingversatilemultimodalreasoning,
title={GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={GLM-V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Wenkai Li and Wei Jia and Xin Lyu and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuxuan Zhang and Zhanxiao Du and Zhenyu Hou and Zhao Xue and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}
 Safetensors Safetensors
Safetensors Safetensors