%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 GLM-4.1V-9B-Thinking-AWQ
このリポジトリは、多様なマルチモーダル理解と推論に特化した強力なビジョン言語モデル(VLM)であるGLM-4.1V-9B-ThinkingのAWQ量子化バージョンをホストしています。
このモデルは論文GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learningで発表されました。
公式GitHubリポジトリ: https://github.com/THUDM/GLM-4.1V-Thinking
ベースモデル: ZhipuAI/GLM-4.1V-9B-Thinking
🚀 クイックスタート
モデル更新日
2025-07-03
1. 初回コミット
2. 1、2、4カードの`tensor-parallel-size`起動をサポートすることを確定
依存関係
vllm==0.9.2
💡 2025-07-03 一時的なインストールコマンド 💡
pip3 install -r requirements.txt
git clone https://github.com/zRzRzRzRzRzRzR/vllm.git
cd vllm
git checkout glm4_1-v
VLLM_USE_PRECOMPILED=1 pip install --editable .
モデルダウンロード
from modelscope import snapshot_download
snapshot_download('dengcao/GLM-4.1V-9B-Thinking-AWQ', cache_dir="本地路径")
✨ 主な機能
ビジョン言語モデル(VLM)は、インテリジェントシステムの基盤となるコンポーネントになっています。現実世界のAIタスクがますます複雑になるにつれ、VLMは基本的なマルチモーダル知覚を超えて、複雑なタスクでの推論能力を向上させる必要があります。これには、精度、包括性、インテリジェンスの向上が含まれ、複雑な問題解決、長文脈理解、マルチモーダルエージェントなどのアプリケーションを可能にします。
GLM-4-9B-0414ファウンデーションモデルに基づいて、新しいオープンソースのVLMモデルGLM-4.1V-9B-Thinkingを提案します。このモデルは、ビジョン言語モデルの推論の上限を探求するように設計されています。「思考パラダイム」を導入し、強化学習を活用することで、モデルの能力が大幅に向上しています。100億パラメータのVLMの中で最先端の性能を達成し、18のベンチマークタスクで720億パラメータのQwen-2.5-VL-72Bと同等またはそれ以上の性能を発揮します。また、ベースモデルのGLM-4.1V-9B-Baseもオープンソース化し、VLM能力の限界に関するさらなる研究をサポートしています。
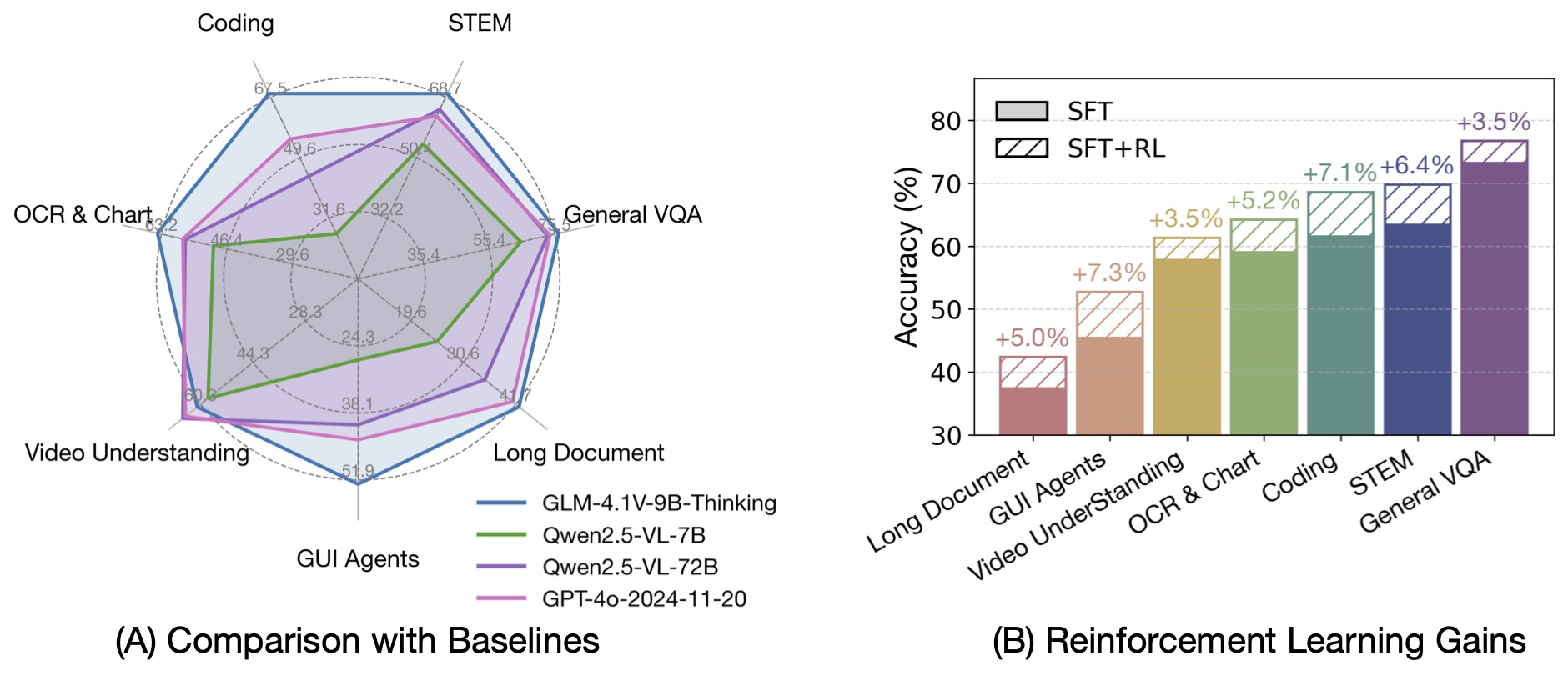
前世代のモデルであるCogVLM2やGLM-4Vシリーズと比較して、GLM-4.1V-Thinkingには以下の改善点があります。
- シリーズの中で初めての推論に焦点を当てたモデルで、数学だけでなく様々なサブドメインで世界トップレベルの性能を達成しています。
- 64kのコンテキスト長をサポートしています。
- 任意のアスペクト比と最大4Kの画像解像度を扱うことができます。
- 中国語と英語のバイリンガル使用をサポートするオープンソースバージョンを提供しています。
📚 ドキュメント
モデル情報
モデルダウンロードリンク
| モデル | ダウンロードリンク | モデルタイプ |
|---|---|---|
| GLM-4.1V-9B-Thinking | 🤗 Hugging Face 🤖 ModelScope |
推論モデル |
| GLM-4.1V-9B-Base | 🤗 Hugging Face 🤖 ModelScope |
ベースモデル |
モデルのアルゴリズム実装は、公式のtransformersリポジトリにあります。
ランタイム要件
推論
| デバイス(単一GPU) | フレームワーク | 最小メモリ | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 トークン / 秒 | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 トークン / 秒 | BF16 |
ファインチューニング
以下の結果は、LLaMA-Factoryツールキットを使用した画像ファインチューニングに基づいています。
| デバイス(クラスター) | 戦略 | 最小メモリ / GPU数 | バッチサイズ(GPUごと) | 凍結 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | VITを凍結 |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | VITを凍結 |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | VITを凍結 |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | 凍結しない |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | 凍結しない |
注意: Zero2でのファインチューニングでは損失がゼロになる可能性があります。安定したトレーニングにはZero3を推奨します。
ベンチマーク性能
GLM-4-9B-0414ファウンデーションモデルに基づいて、新しいオープンソースのVLMモデルGLM-4.1V-9B-Thinkingを提案します。このモデルは「思考」パラダイムを導入し、カリキュラムサンプリングを用いた強化学習(RLCS)を活用して、モデルの能力を総合的に向上させています。100億パラメータ規模のビジョン言語モデルの中で最先端の性能を達成し、18のベンチマークタスクで720億パラメータのQwen-2.5-VLと同等またはそれ以上の性能を発揮します。また、ベースモデルのGLM-4.1V-9B-Baseもオープンソース化し、ビジョン言語モデルのフロンティアに関するさらなる研究をサポートしています。

モデル推論
すべての推論スクリプトはinferenceフォルダにあり、以下のものが含まれています。
trans_infer_cli.py:transformersライブラリをバックエンドとして使用するコマンドラインインタラクティブスクリプトで、マルチターンダイアログをサポートしています。trans_infer_gradio.py:transformersバックエンドを使用するGradioベースのウェブUIスクリプトで、画像、動画、PDF、PPTなどのマルチモーダル入力をサポートしています。vllmを使用したOpenAI互換APIサービスで、vllm_api_request.pyに簡単なリクエスト例が提供されています。
vllm serve THUDM/GLM-4.1V-9B-Thinking --limit-mm-per-prompt '{"image":32}' --allowed-local-media-path /
--limit-mm-per-promptを指定しない場合、1枚の画像のみがサポートされます。モデルは入力ごとに最大1つの動画または300枚の画像をサポートしていますが、画像と動画の同時入力はサポートしていません。--allowed-local-media-pathを設定する必要があり、ローカルのマルチモーダル入力へのアクセスを許可します。trans_infer_bench:GLM-4.1V-9B-Thinkingでの推論用の学術的なベンチマークスクリプト。主な機能:- 思考が8192トークンを超えた場合、自動的に中断し、
</think><answer>を追加してモデルに最終回答を生成させます。 - 動画ベースの入力を示していますが、他のモダリティの場合は変更が必要です。
transformersバージョンのみ提供されています。vLLMの場合は、このロジックをサポートするためにカスタム実装が必要です。
- 思考が8192トークンを超えた場合、自動的に中断し、
vllm_request_gui_agent.py: このスクリプトは、モデルの応答を処理し、GUIエージェントのユースケースのためのプロンプトを構築する方法を示しています。モバイル、デスクトップ、ウェブ環境の戦略をカバーしており、あなたのアプリケーションフレームワークに統合することができます。GUIエージェントに関する詳細なドキュメントは、このファイルを参照してください。- 昇腾NPU推論については、こちらを確認してください。
モデルファインチューニング
LLaMA-Factoryは現在、このモデルのファインチューニングをサポートしています。以下は、2枚の画像を使用したサンプルデータセットです。finetune.jsonファイルに次のようにデータセットを準備してください。
[
{
"messages": [
{
"content": "<image>Who are they?",
"role": "user"
},
{
"content": "<think>
User ask me to observe the image and get the answer. I Know they are Kane and Gretzka from Bayern Munich.</think>
<answer>They're Kane and Gretzka from Bayern Munich.</answer>",
"role": "assistant"
},
{
"content": "<image>What are they doing?",
"role": "user"
},
{
"content": "<think>
I need to observe what this people are doing. Oh, They are celebrating on the soccer field.</think>
<answer>They are celebrating on the soccer field.</answer>",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg",
"mllm_demo_data/2.jpg"
]
}
]
<think> ... </think>内の内容は、会話履歴に保存されず、ファインチューニング中に使用されません。<image>タグは、前処理中に実際の画像データに置き換えられます。
データセットを準備した後、標準のLLaMA-Factoryパイプラインを使用してファインチューニングを進めることができます。
📄 ライセンス
- このリポジトリ内のコードは、Apache License 2.0の下で公開されています。
- モデルGLM-4.1V-9B-ThinkingとGLM-4.1V-9B-Baseは両方ともMITライセンスの下で提供されています。
引用
もし私たちの研究が役に立った場合は、以下の論文を引用していただけると幸いです。
@misc{glmvteam2025glm41vthinkingversatilemultimodalreasoning,
title={GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={GLM-V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Wenkai Li and Wei Jia and Xin Lyu and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuxuan Zhang and Zhanxiao Du and Zhenyu Hou and Zhao Xue and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}
 Safetensors Safetensors
Safetensors Safetensors