🚀 M-CTC-T
M-CTC-T 是 Meta AI 推出的大規模多語言語音識別器。該模型是一個具有 10 億參數的 Transformer 編碼器,配備了一個針對 8065 個字符標籤的 CTC 頭部和一個針對 60 個語言 ID 標籤的語言識別頭部。它在 Common Voice(2020 年 12 月發佈的 6.1 版本)和 VoxPopuli 數據集上進行訓練。在這兩個數據集上完成訓練後,模型僅在 Common Voice 上繼續訓練。標籤為未歸一化的字符級轉錄(未去除標點和大小寫)。該模型以 16Khz 音頻信號的梅爾濾波器組特徵作為輸入。
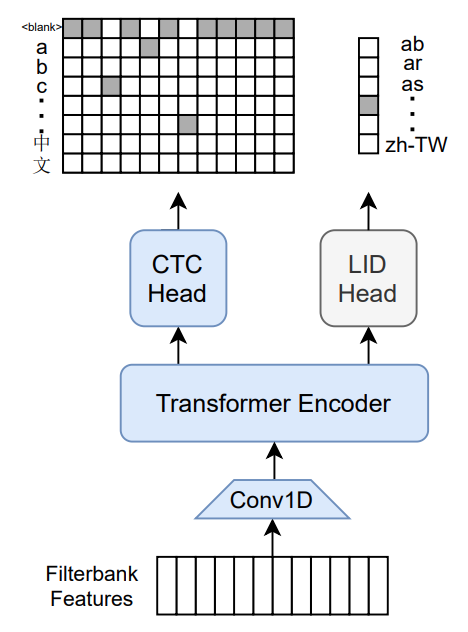
原始的 Flashlight 代碼、模型檢查點和 Colab 筆記本可在 此處 找到。
✨ 主要特性
- 大規模多語言語音識別能力。
- 基於 10 億參數的 Transformer 編碼器架構。
- 配備 CTC 頭部和語言識別頭部。
📚 詳細文檔
引用信息
- 論文
- 作者:Loren Lugosch、Tatiana Likhomanenko、Gabriel Synnaeve、Ronan Collobert
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
貢獻者
非常感謝 Chan Woo Kim 將模型從 Flashlight C++ 移植到 PyTorch。
訓練方法
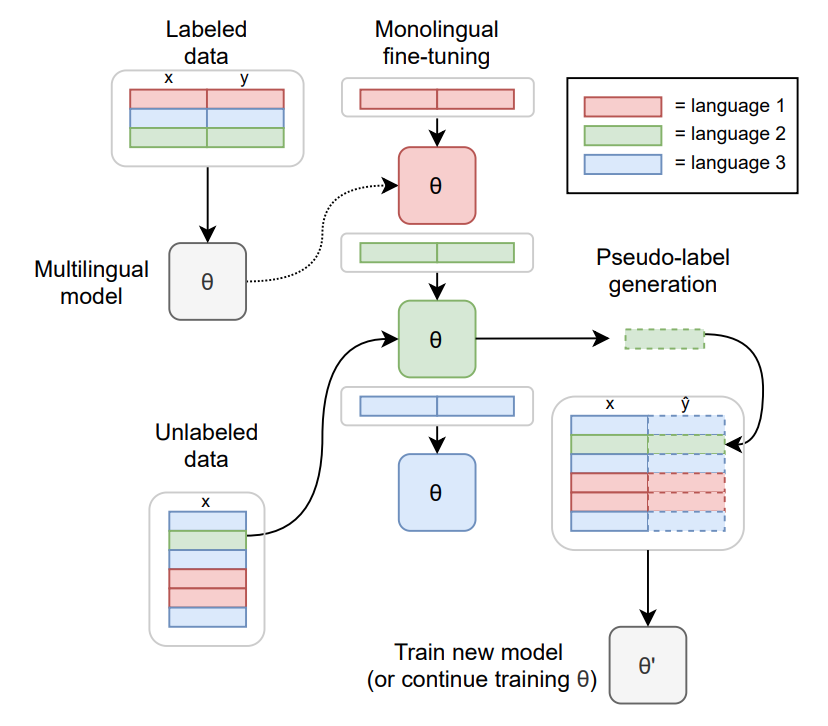
有關該模型的訓練方式的更多信息,請查看 官方論文。
💻 使用示例
基礎用法
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/m-ctc-t-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/m-ctc-t-large")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
input_features = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt").input_features
with torch.no_grad():
logits = model(input_features).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
模型表現
Common Voice 數據集上所有語言的平均結果:
| 屬性 |
詳情 |
| 字符錯誤率 (CER) - 驗證集 |
21.4 |
| 字符錯誤率 (CER) - 測試集 |
23.3 |
📄 許可證
本項目採用 Apache-2.0 許可證。
📥 問題與幫助
如果您對該模型有疑問或需要幫助,請考慮在本倉庫中開啟討論或提交拉取請求,並標記 @lorenlugosch、@cwkeam 或 @patrickvonplaten。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言