🚀 M-CTC-T
Meta AIによる大規模な多言語音声認識モデルです。このモデルは10億パラメータのTransformerエンコーダで、8065の文字ラベルに対するCTCヘッドと60の言語IDラベルに対する言語識別ヘッドを備えています。Common Voice(バージョン6.1、2020年12月リリース)とVoxPopuliで学習され、その後はCommon Voiceのみで学習されまし。ラベルは正規化されていない文字レベルの文字起こし(句読点や大文字は削除されていません)です。モデルは16Khzの音声信号からのメルフィルタバンク特徴量を入力とします。
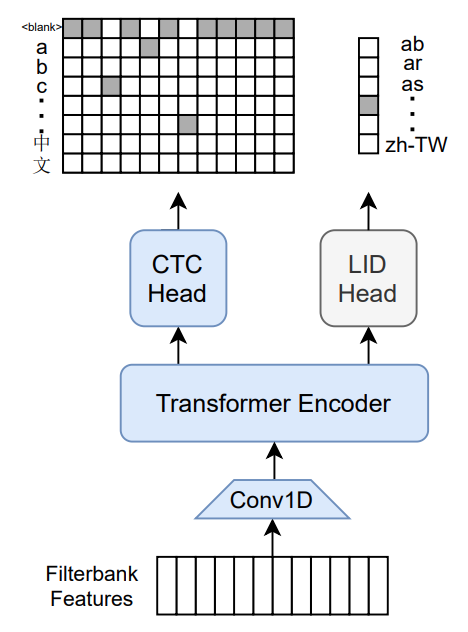
オリジナルのFlashlightコード、モデルチェックポイント、およびColabノートブックは、https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl で見つけることができます。
✨ 主な機能
- 大規模な多言語音声認識が可能です。
- 10億パラメータのTransformerエンコーダを使用しています。
- 8065の文字ラベルに対するCTCヘッドと60の言語IDラベルに対する言語識別ヘッドを備えています。
📦 インストール
ドキュメントに具体的なインストール手順が記載されていないため、このセクションをスキップします。
💻 使用例
基本的な使用法
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/m-ctc-t-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/m-ctc-t-large")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
input_features = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt").input_features
with torch.no_grad():
logits = model(input_features).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
高度な使用法
ドキュメントに高度な使用法のコード例が記載されていないため、このセクションをスキップします。
📚 ドキュメント
モデル情報
| 属性 |
详情 |
| モデルタイプ |
大規模な多言語音声認識モデル |
| 学習データ |
Common Voice(バージョン6.1、2020年12月リリース)とVoxPopuli |
引用情報
論文
著者: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
貢献者
Chan Woo Kim氏(https://huggingface.co/cwkeam )に、Flashlight C++からPyTorchへのモデルの移植に対して大きな感謝を表します。
学習方法
モデルの学習方法の詳細については、公式論文を参照してください。
評価結果
Common Voiceに対する結果(すべての言語で平均):
文字誤り率 (CER):
質問とヘルプ
このモデルに関する質問やヘルプが必要な場合は、このリポジトリでディスカッションを開くか、プルリクエストを送信し、@lorenlugosch、@cwkeamまたは@patrickvonplatenをタグ付けしてください。
📄 ライセンス
このモデルはApache-2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応