🚀 中世ラテン語用TROcrモデル
このモデルは、中世ラテン語、特にカロリン文字用のTROcrモデルです。中世の手書きテキストを画像からテキストに変換するために役立ちます。
🚀 クイックスタート
このモデルは、中世ラテン語のカロリン文字を認識するために調整されたTROcrモデルです。ベースモデルは microsoft/trocr-base-handwritten で、CATMuS データセットの例を使って微調整されました。
✨ 主な機能
- 中世ラテン語のカロリン文字を画像からテキストに変換します。
- ベースモデルを微調整して、特定の文字スタイルに適応させています。
📦 インストール
このモデルを使用するには、transformers ライブラリが必要です。以下のコマンドでインストールできます。
pip install transformers
💻 使用例
基本的な使用法
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
https://huggingface.co/medieval-data/trocr-medieval-latin-caroline/resolve/main/images/heldout1.png
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('medieval-data/trocr-medieval-latin-caroline')
model = VisionEncoderDecoderModel.from_pretrained('medieval-data/trocr-medieval-latin-caroline')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
📚 ドキュメント
このモデルは正式にテストされていません。予備的な検査では、さらなる微調整が必要であることが示されています。微調整は、このリポジトリにある finetune.py を使って行われました。
📄 ライセンス
このプロジェクトはMITライセンスの下で公開されています。
📚 引用情報
TrOCR論文
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
CATMuS論文
@unpublished{clerice:hal-04453952,
TITLE = {{CATMuS Medieval: A multilingual large-scale cross-century dataset in Latin script for handwritten text recognition and beyond}},
AUTHOR = {Cl{\'e}rice, Thibault and Pinche, Ariane and Vlachou-Efstathiou, Malamatenia and Chagu{\'e}, Alix and Camps, Jean-Baptiste and Gille-Levenson, Matthias and Brisville-Fertin, Olivier and Fischer, Franz and Gervers, Michaels and Boutreux, Agn{\`e}s and Manton, Avery and Gabay, Simon and O'Connor, Patricia and Haverals, Wouter and Kestemont, Mike and Vandyck, Caroline and Kiessling, Benjamin},
URL = {https://inria.hal.science/hal-04453952},
NOTE = {working paper or preprint},
YEAR = {2024},
MONTH = Feb,
KEYWORDS = {Historical sources ; medieval manuscripts ; Latin scripts ; benchmarking dataset ; multilingual ; handwritten text recognition},
PDF = {https://inria.hal.science/hal-04453952/file/ICDAR24___CATMUS_Medieval-1.pdf},
HAL_ID = {hal-04453952},
HAL_VERSION = {v1},
}
情報テーブル
| 属性 |
详情 |
| モデルタイプ |
中世ラテン語用TROcrモデル |
| 学習データ |
CATMuS データセット |
ウィジェット例

%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors{kind=link}
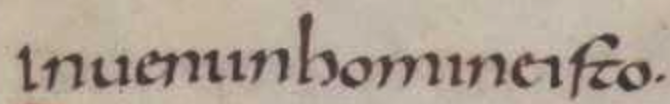{kind=link}
 Transformers 複数言語対応
Transformers 複数言語対応