🚀 ドキュメント理解モデル (DocLayNet base で行レベルで微調整された LiLT base)
このモデルは、DocLayNet base データセットを使用して、nielsr/lilt-xlm-roberta-base を微調整したバージョンです。評価セットでは以下の結果を達成しています。
🚀 クイックスタート
このモデルは、文書理解タスクにおいて高い精度を発揮します。以下に評価セットでの結果を示します。
- 損失: 1.0003
- 精度 (Precision): 0.8584
- 再現率 (Recall): 0.8584
- F1 スコア: 0.8584
- トークン精度: 0.8584
- 行精度: 0.9197
✨ 主な機能
- 多言語対応: 複数の言語での文書理解に対応しています。
- 高い精度: 評価セットで高い精度を達成しています。
- 行レベルの分析: 行レベルでの文書理解を行うことができます。
📚 ドキュメント
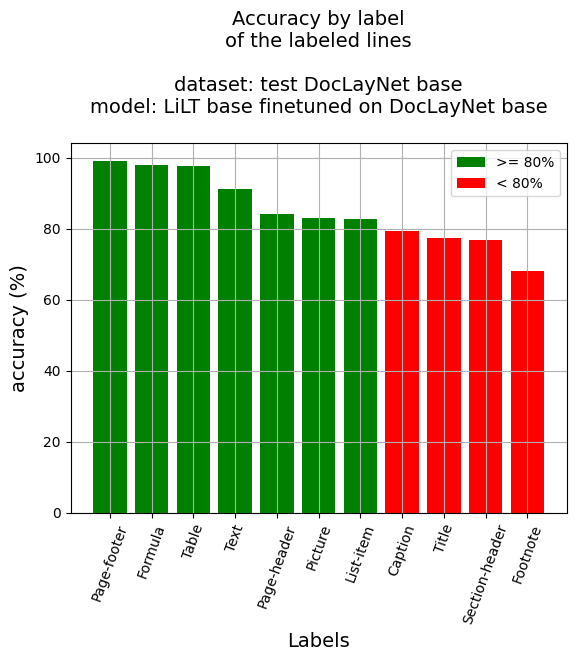
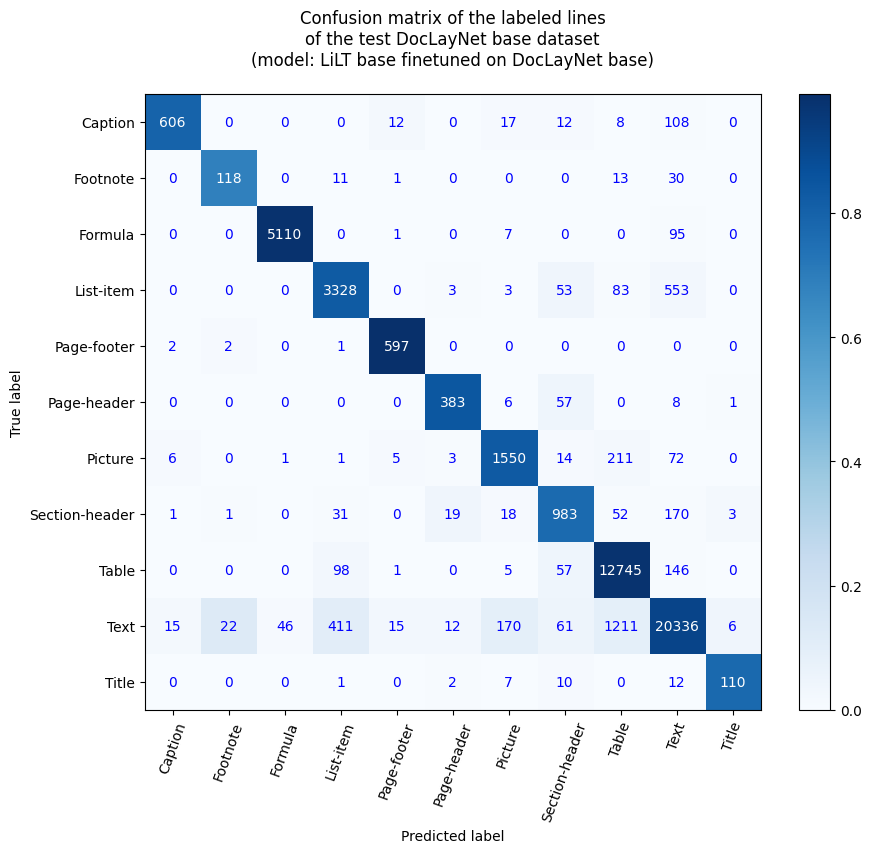
行レベルの精度
- 行精度: 91.97%
- ラベル別精度
- キャプション: 79.42%
- 脚注: 68.21%
- 数式: 98.02%
- リスト項目: 82.72%
- ページフッター: 99.17%
- ページヘッダー: 84.18%
- 画像: 83.2%
- セクションヘッダー: 76.92%
- 表: 97.65%
- テキスト: 91.17%
- タイトル: 77.46%
参考文献
ブログ記事
- Layout XLM base
- LiLT base
ノートブック (段落レベル)
ノートブック (行レベル)
- Layout XLM base
- LiLT base
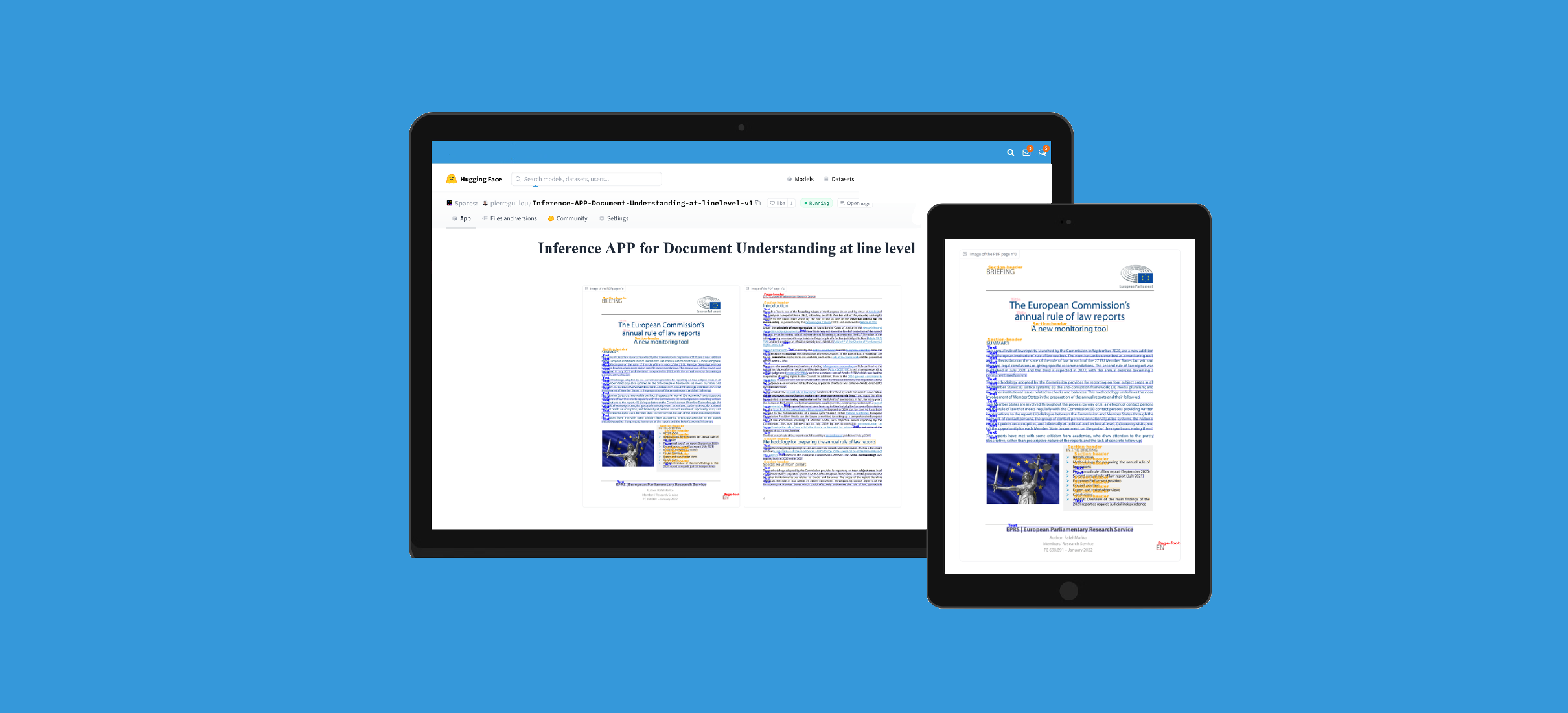
APP
このモデルは、Hugging Face Spaces のこのアプリでテストできます: Inference APP for Document Understanding at line level (v1)。
DocLayNet データセット
DocLayNet データセット (IBM) は、6 つの文書カテゴリからの 80863 の一意のページに対して、11 の異なるクラスラベルに対するバウンディングボックスを使用したページごとのレイアウトセグメンテーションの正解データを提供します。
現在まで、このデータセットは直接リンクまたは Hugging Face のデータセットライブラリからダウンロードできます。
論文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (2022年6月2日)
モデルの説明
このモデルは、384 トークンのチャンクで 128 トークンのオーバーラップを持つ行レベルで微調整されています。したがって、モデルはデータセットのすべてのページのすべてのレイアウトとテキストデータを使用してトレーニングされました。
推論時には、最適な確率の計算により、各行のバウンディングボックスにラベルが付けられます。
推論
ノートブックを参照してください: Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
トレーニングと評価データ
ノートブックを参照してください: Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
トレーニング手順
トレーニングハイパーパラメータ
トレーニング中に以下のハイパーパラメータが使用されました。
- 学習率: 5e-05
- トレーニングバッチサイズ: 8
- 評価バッチサイズ: 16
- シード: 42
- オプティマイザ: Adam (betas=(0.9,0.999), epsilon=1e-08)
- 学習率スケジューラ: 線形
- エポック数: 5
- 混合精度トレーニング: Native AMP
トレーニング結果
| トレーニング損失 |
エポック |
ステップ |
検証損失 |
精度 |
再現率 |
F1 スコア |
正解率 |
| 0.7223 |
0.21 |
500 |
0.7765 |
0.7741 |
0.7741 |
0.7741 |
0.7741 |
| 0.4469 |
0.42 |
1000 |
0.5914 |
0.8312 |
0.8312 |
0.8312 |
0.8312 |
| 0.3819 |
0.62 |
1500 |
0.8745 |
0.8102 |
0.8102 |
0.8102 |
0.8102 |
| 0.3361 |
0.83 |
2000 |
0.6991 |
0.8337 |
0.8337 |
0.8337 |
0.8337 |
| 0.2784 |
1.04 |
2500 |
0.7513 |
0.8119 |
0.8119 |
0.8119 |
0.8119 |
| 0.2377 |
1.25 |
3000 |
0.9048 |
0.8166 |
0.8166 |
0.8166 |
0.8166 |
| 0.2401 |
1.45 |
3500 |
1.2411 |
0.7939 |
0.7939 |
0.7939 |
0.7939 |
| 0.2054 |
1.66 |
4000 |
1.1594 |
0.8080 |
0.8080 |
0.8080 |
0.8080 |
| 0.1909 |
1.87 |
4500 |
0.7545 |
0.8425 |
0.8425 |
0.8425 |
0.8425 |
| 0.1704 |
2.08 |
5000 |
0.8567 |
0.8318 |
0.8318 |
0.8318 |
0.8318 |
| 0.1294 |
2.29 |
5500 |
0.8486 |
0.8489 |
0.8489 |
0.8489 |
0.8489 |
| 0.134 |
2.49 |
6000 |
0.7682 |
0.8573 |
0.8573 |
0.8573 |
0.8573 |
| 0.1354 |
2.7 |
6500 |
0.9871 |
0.8256 |
0.8256 |
0.8256 |
0.8256 |
| 0.1239 |
2.91 |
7000 |
1.1430 |
0.8189 |
0.8189 |
0.8189 |
0.8189 |
| 0.1012 |
3.12 |
7500 |
0.8272 |
0.8386 |
0.8386 |
0.8386 |
0.8386 |
| 0.0788 |
3.32 |
8000 |
1.0288 |
0.8365 |
0.8365 |
0.8365 |
0.8365 |
| 0.0802 |
3.53 |
8500 |
0.7197 |
0.8849 |
0.8849 |
0.8849 |
0.8849 |
| 0.0861 |
3.74 |
9000 |
1.1420 |
0.8320 |
0.8320 |
0.8320 |
0.8320 |
| 0.0639 |
3.95 |
9500 |
0.9563 |
0.8585 |
0.8585 |
0.8585 |
0.8585 |
| 0.0464 |
4.15 |
10000 |
1.0768 |
0.8511 |
0.8511 |
0.8511 |
0.8511 |
| 0.0412 |
4.36 |
10500 |
1.1184 |
0.8439 |
0.8439 |
0.8439 |
0.8439 |
| 0.039 |
4.57 |
11000 |
0.9634 |
0.8636 |
0.8636 |
0.8636 |
0.8636 |
| 0.0469 |
4.78 |
11500 |
0.9585 |
0.8634 |
0.8634 |
0.8634 |
0.8634 |
| 0.0395 |
4.99 |
12000 |
1.0003 |
0.8584 |
0.8584 |
0.8584 |
0.8584 |
フレームワークのバージョン
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
その他のモデル
📄 ライセンス
このモデルは MIT ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応