🚀 文档理解模型(在DocLayNet基础数据集上按行微调LiLT基础模型)
该模型是一个文档理解模型,基于nielsr/lilt-xlm-roberta-base在DocLayNet基础数据集上进行微调。它能对文档布局进行精准分析和分类,在文档理解任务中表现出色,为处理各类文档提供了有效的解决方案。
🚀 快速开始
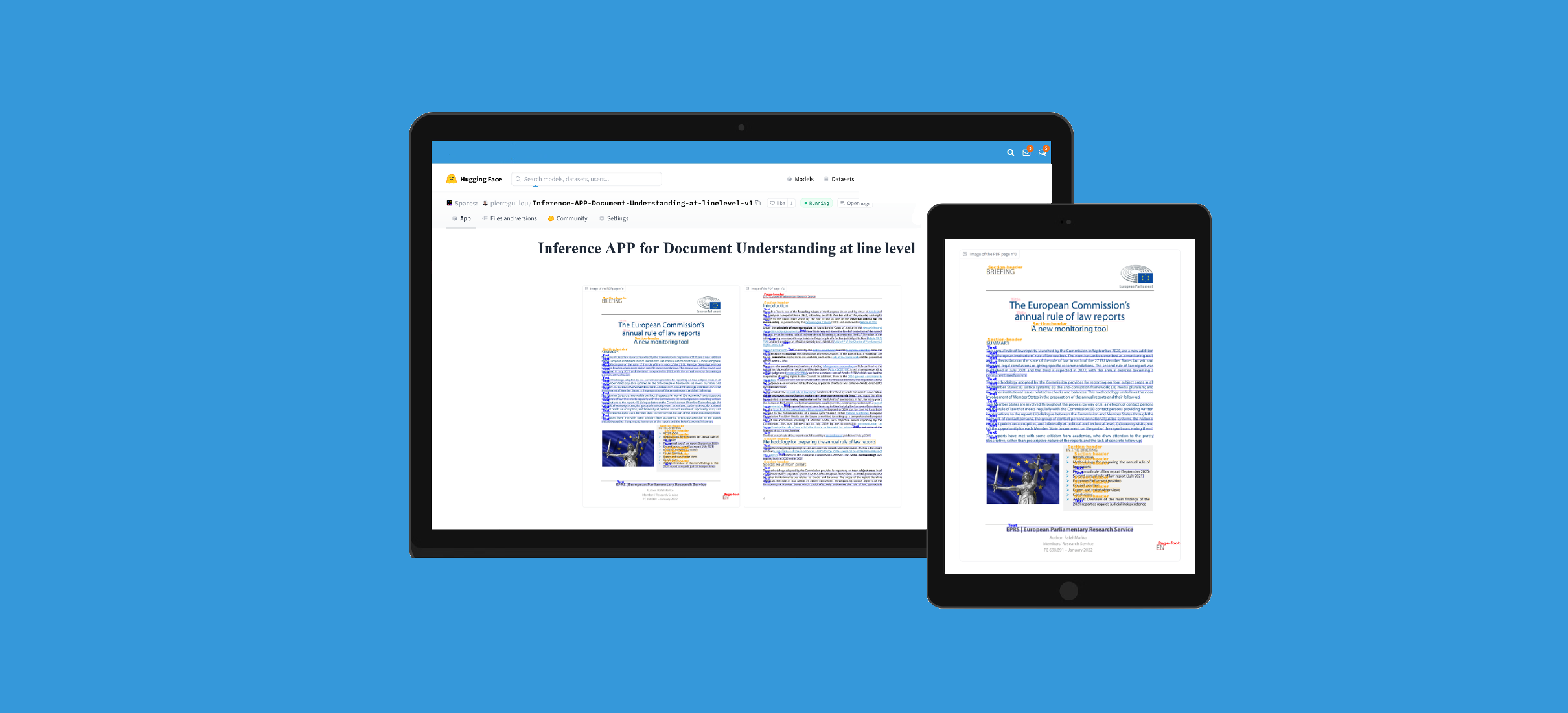
此模型可通过Hugging Face Spaces中的APP进行测试:行级文档理解推理应用(v1)。
✨ 主要特性
- 多语言支持:支持多种语言,包括英语、德语、法语和日语等。
- 多任务处理:可用于目标检测、图像分割和标记分类等任务。
- 高精度表现:在评估集上取得了较高的准确率、召回率和F1值。
📚 详细文档
评估集结果
该模型在评估集上取得了以下结果:
- 损失:1.0003
- 精确率:0.8584
- 召回率:0.8584
- F1值:0.8584
- 标记准确率:0.8584
- 行准确率:0.9197
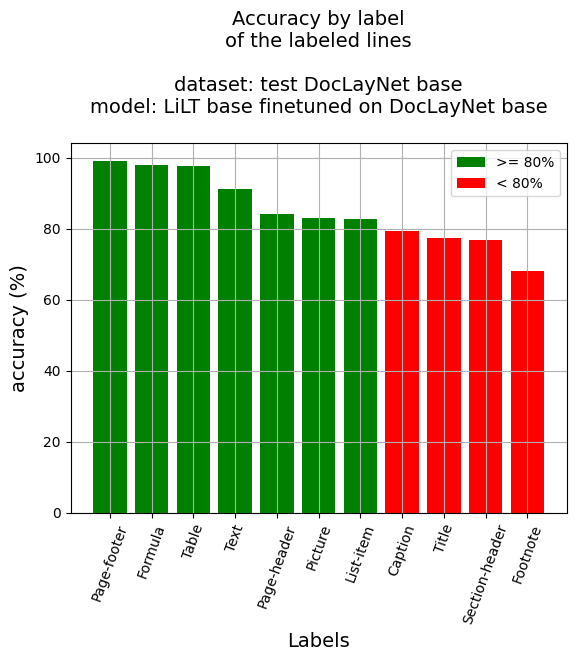
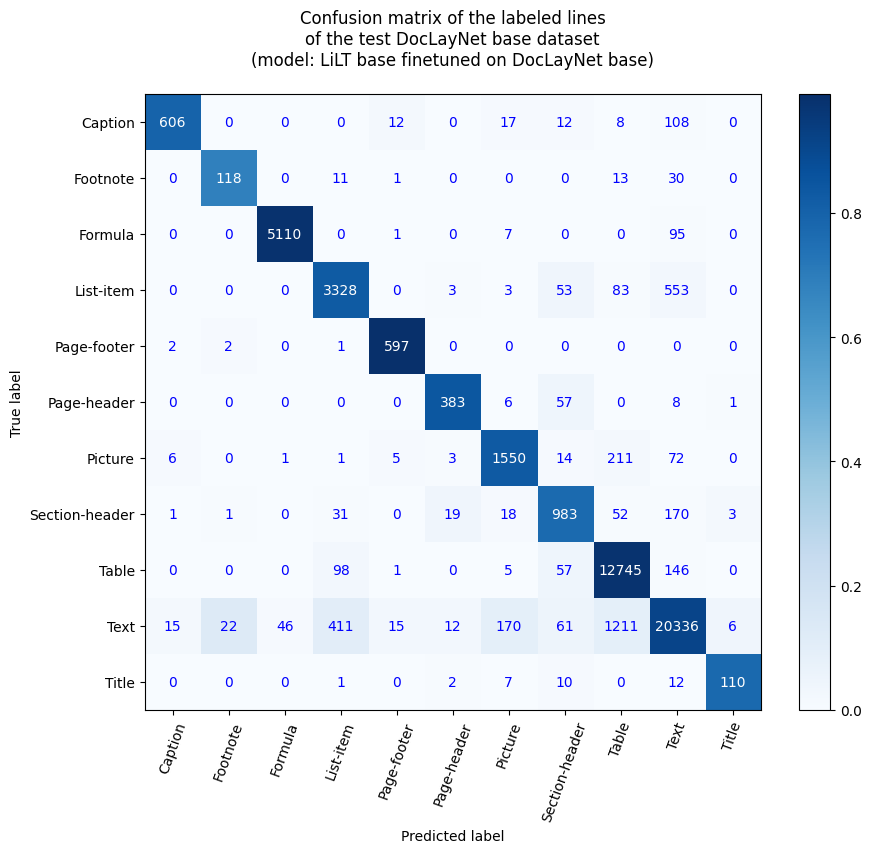
行级准确率
- 行准确率:91.97%
- 按标签分类的准确率:
- 标题说明:79.42%
- 脚注:68.21%
- 公式:98.02%
- 列表项:82.72%
- 页面页脚:99.17%
- 页面页眉:84.18%
- 图片:83.2%
- 章节标题:76.92%
- 表格:97.65%
- 文本:91.17%
- 标题:77.46%
参考资料
博客文章
笔记本(段落级)
笔记本(行级)
DocLayNet数据集
DocLayNet数据集(IBM)为来自6个文档类别的80863个唯一页面,提供了逐页布局分割的真实标注,使用边界框标注了11个不同的类别标签。
到目前为止,该数据集可以通过直接链接下载,也可以从Hugging Face数据集库中获取:
论文:DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis(2022年6月2日)
模型描述
该模型是在384个标记块上按行级进行微调,标记块重叠128个标记。因此,该模型使用了数据集中所有页面的布局和文本数据进行训练。
在推理时,通过计算最佳概率为每个行边界框分配标签。
推理
请参阅笔记本:文档AI | 使用文档理解模型(在DocLayNet数据集上微调的LiLT)进行行级推理
训练和评估数据
请参阅笔记本:文档AI | 在任何语言下按行级(384个标记块,有重叠)在DocLayNet基础数据集上微调LiLT
训练过程
训练超参数
训练期间使用了以下超参数:
- 学习率:5e-05
- 训练批次大小:8
- 评估批次大小:16
- 随机种子:42
- 优化器:Adam(β1=0.9,β2=0.999,ε=1e-08)
- 学习率调度器类型:线性
- 训练轮数:5
- 混合精度训练:原生自动混合精度(Native AMP)
训练结果
| 训练损失 |
轮数 |
步数 |
验证损失 |
精确率 |
召回率 |
F1值 |
准确率 |
| 0.7223 |
0.21 |
500 |
0.7765 |
0.7741 |
0.7741 |
0.7741 |
0.7741 |
| 0.4469 |
0.42 |
1000 |
0.5914 |
0.8312 |
0.8312 |
0.8312 |
0.8312 |
| 0.3819 |
0.62 |
1500 |
0.8745 |
0.8102 |
0.8102 |
0.8102 |
0.8102 |
| 0.3361 |
0.83 |
2000 |
0.6991 |
0.8337 |
0.8337 |
0.8337 |
0.8337 |
| 0.2784 |
1.04 |
2500 |
0.7513 |
0.8119 |
0.8119 |
0.8119 |
0.8119 |
| 0.2377 |
1.25 |
3000 |
0.9048 |
0.8166 |
0.8166 |
0.8166 |
0.8166 |
| 0.2401 |
1.45 |
3500 |
1.2411 |
0.7939 |
0.7939 |
0.7939 |
0.7939 |
| 0.2054 |
1.66 |
4000 |
1.1594 |
0.8080 |
0.8080 |
0.8080 |
0.8080 |
| 0.1909 |
1.87 |
4500 |
0.7545 |
0.8425 |
0.8425 |
0.8425 |
0.8425 |
| 0.1704 |
2.08 |
5000 |
0.8567 |
0.8318 |
0.8318 |
0.8318 |
0.8318 |
| 0.1294 |
2.29 |
5500 |
0.8486 |
0.8489 |
0.8489 |
0.8489 |
0.8489 |
| 0.134 |
2.49 |
6000 |
0.7682 |
0.8573 |
0.8573 |
0.8573 |
0.8573 |
| 0.1354 |
2.7 |
6500 |
0.9871 |
0.8256 |
0.8256 |
0.8256 |
0.8256 |
| 0.1239 |
2.91 |
7000 |
1.1430 |
0.8189 |
0.8189 |
0.8189 |
0.8189 |
| 0.1012 |
3.12 |
7500 |
0.8272 |
0.8386 |
0.8386 |
0.8386 |
0.8386 |
| 0.0788 |
3.32 |
8000 |
1.0288 |
0.8365 |
0.8365 |
0.8365 |
0.8365 |
| 0.0802 |
3.53 |
8500 |
0.7197 |
0.8849 |
0.8849 |
0.8849 |
0.8849 |
| 0.0861 |
3.74 |
9000 |
1.1420 |
0.8320 |
0.8320 |
0.8320 |
0.8320 |
| 0.0639 |
3.95 |
9500 |
0.9563 |
0.8585 |
0.8585 |
0.8585 |
0.8585 |
| 0.0464 |
4.15 |
10000 |
1.0768 |
0.8511 |
0.8511 |
0.8511 |
0.8511 |
| 0.0412 |
4.36 |
10500 |
1.1184 |
0.8439 |
0.8439 |
0.8439 |
0.8439 |
| 0.039 |
4.57 |
11000 |
0.9634 |
0.8636 |
0.8636 |
0.8636 |
0.8636 |
| 0.0469 |
4.78 |
11500 |
0.9585 |
0.8634 |
0.8634 |
0.8634 |
0.8634 |
| 0.0395 |
4.99 |
12000 |
1.0003 |
0.8584 |
0.8584 |
0.8584 |
0.8584 |
框架版本
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
其他模型
📄 许可证
本项目采用MIT许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言