🚀 GLM-4-9B-Chat
GLM-4-9Bは、智譜AIが発表したGLM-4シリーズの最新世代の事前学習モデルのオープンソース版です。意味論、数学、推論、コード、知識などのデータセットの評価において、GLM-4-9Bとその人間嗜好アラインメント版のGLM-4-9B-Chatは、Llama-3-8Bを上回る優れた性能を示しています。GLM-4-9B-Chatは、多ラウンド会話に加えて、ウェブ閲覧、コード実行、カスタムツール呼び出し(Function Call)、長文脈推論(最大128Kの文脈をサポート)などの高度な機能も備えています。この世代のモデルには多言語サポートが追加され、日本語、韓国語、ドイツ語など26の言語をサポートしています。また、1Mの文脈長(約200万字)をサポートするGLM-4-9B-Chat-1Mモデルと、GLM-4-9Bに基づくマルチモーダルモデルGLM-4V-9Bも発表しています。GLM-4V-9Bは、1120*1120の高解像度で、中国語と英語の両方の対話能力を備えています。中国語と英語の総合能力、知覚と推論、テキスト認識、チャート理解などのさまざまなマルチモーダル評価において、GLM-4V-9Bは、GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max、Claude 3 Opusと比較して優れた性能を示しています。
🚀 クイックスタート
より詳しい推論コードと要件については、GitHubページをご覧ください。
依存関係に厳密に従ってインストールしてください。そうしないと、正常に動作しません。
Transformersライブラリ(4.46.0以降のバージョン)による推論:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('THUDM/glm-4-9b-chat-hf')
model = AutoModelForCausalLM.from_pretrained('THUDM/glm-4-9b-chat-hf', device_map="auto")
message = [
{
"role": "system",
"content": "Answer the following question."
},
{
"role": "user",
"content": "How many legs does a cat have?"
}
]
inputs = tokenizer.apply_chat_template(
message,
return_tensors='pt',
add_generation_prompt=True,
return_dict=True,
).to(model.device)
input_len = inputs['input_ids'].shape[1]
generate_kwargs = {
"input_ids": inputs['input_ids'],
"attention_mask": inputs['attention_mask'],
"max_new_tokens": 128,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][input_len:], skip_special_tokens=True))
vLLMライブラリ(0.6.4以降のバージョン)による推論:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat-hf"
prompt = [{"role": "user", "content": "what is your name?"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
✨ 主な機能
GLM-4-9Bは、智譜AIが発表したGLM-4シリーズの最新世代の事前学習モデルのオープンソース版です。多くの評価において、Llama-3-8Bを上回る優れた性能を示しています。また、GLM-4-9B-Chatは、多ラウンド会話に加えて、ウェブ閲覧、コード実行、カスタムツール呼び出し、長文脈推論などの高度な機能も備えています。この世代のモデルには多言語サポートが追加され、26の言語をサポートしています。さらに、1Mの文脈長をサポートするGLM-4-9B-Chat-1Mモデルと、マルチモーダルモデルGLM-4V-9Bもあります。
📚 ドキュメント
ベンチマーク
一般ベンチマーク
GLM-4-9B-Chatモデルをいくつかの古典的なタスクで評価し、以下の結果を得ました。
| モデル |
AlignBench-v2 |
MT-Bench |
IFEval |
MMLU |
C-Eval |
GSM8K |
MATH |
HumanEval |
NCB |
| Llama-3-8B-Instruct |
5.12 |
8.00 |
68.58 |
68.4 |
51.3 |
79.6 |
30.0 |
62.2 |
24.7 |
| ChatGLM3-6B |
3.97 |
5.50 |
28.1 |
66.4 |
69.0 |
72.3 |
25.7 |
58.5 |
11.3 |
| GLM-4-9B-Chat |
6.61 |
8.35 |
69.0 |
72.4 |
75.6 |
79.6 |
50.6 |
71.8 |
32.2 |
長文脈
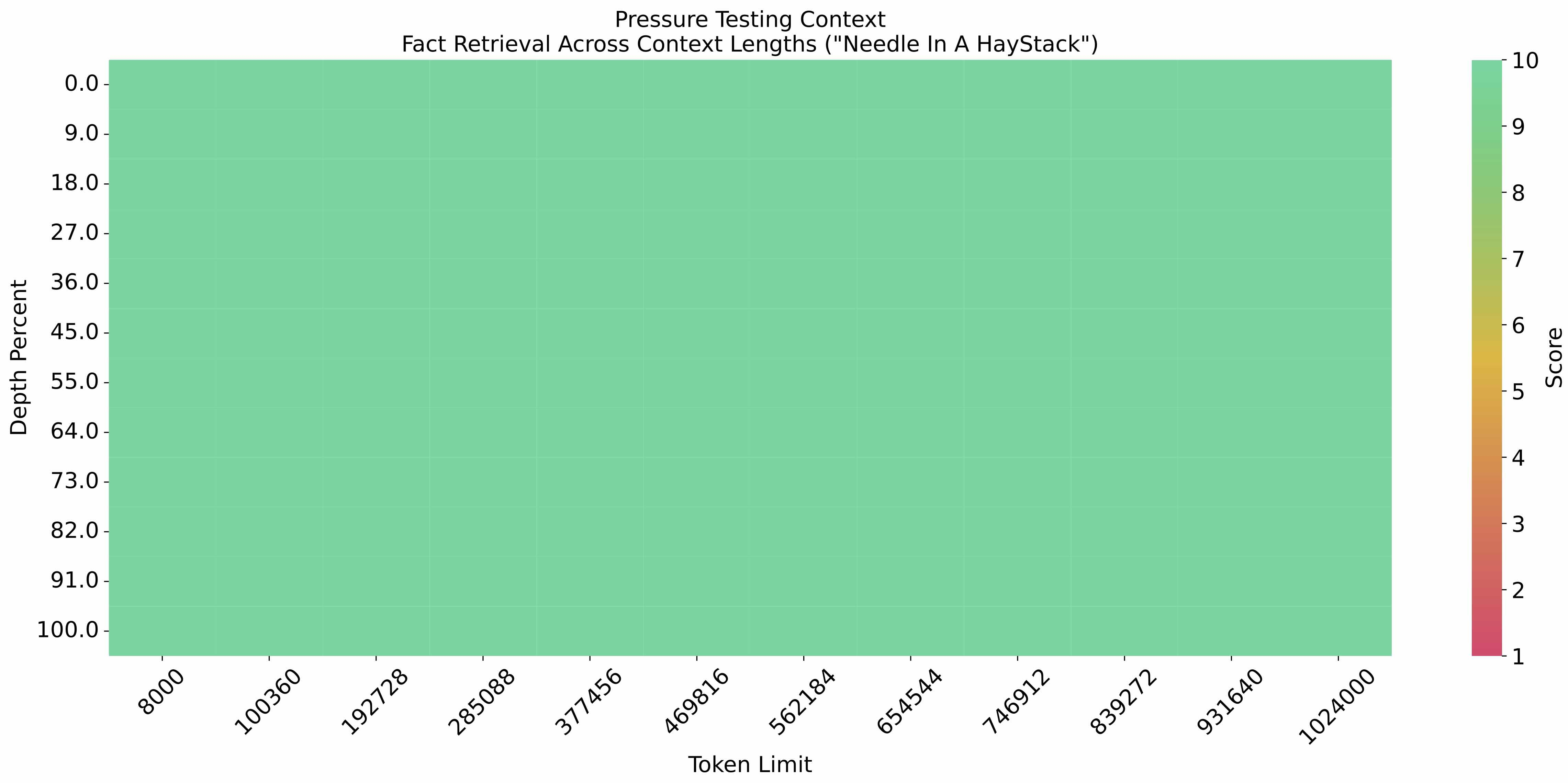
eval_needle実験を文脈長1Mで行い、結果は以下の通りです。
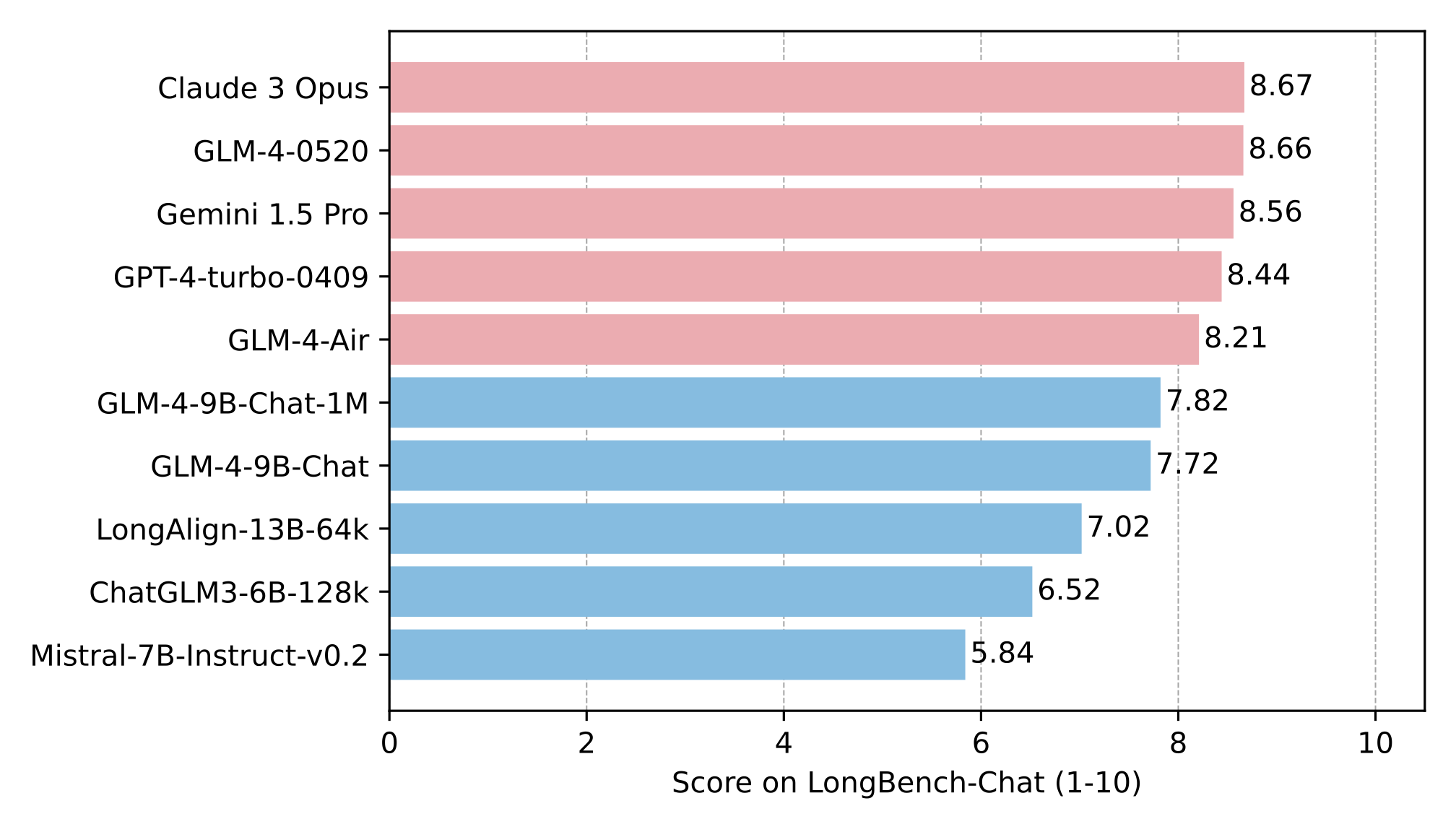
長文能力をLongBenchでさらに評価し、結果は以下の通りです。
多言語
GLM-4-9B-ChatとLlama-3-8B-Instructのテストを6つの多言語データセットで行いました。テスト結果と各データセットで選択された言語は、以下の表に示しています。
| データセット |
Llama-3-8B-Instruct |
GLM-4-9B-Chat |
言語 |
| M-MMLU |
49.6 |
56.6 |
すべて |
| FLORES |
25.0 |
28.8 |
ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
| MGSM |
54.0 |
65.3 |
zh, en, bn, de, es, fr, ja, ru, sw, te, th |
| XWinograd |
61.7 |
73.1 |
zh, en, fr, jp, ru, pt |
| XStoryCloze |
84.7 |
90.7 |
zh, en, ar, es, eu, hi, id, my, ru, sw, te |
| XCOPA |
73.3 |
80.1 |
zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
関数呼び出し
Berkeley Function Calling Leaderboardでテストしました。
| モデル |
全体的な精度 |
AST要約 |
実行要約 |
関連性 |
| Llama-3-8B-Instruct |
58.88 |
59.25 |
70.01 |
45.83 |
| gpt-4-turbo-2024-04-09 |
81.24 |
82.14 |
78.61 |
88.75 |
| ChatGLM3-6B |
57.88 |
62.18 |
69.78 |
5.42 |
| GLM-4-9B-Chat |
81.00 |
80.26 |
84.40 |
87.92 |
このリポジトリは、128Kの文脈長をサポートするGLM-4-9B-Chatのモデルリポジトリです。
📄 ライセンス
GLM-4モデルの重みは、ライセンスの条件の下で利用可能です。
引用
もし私たちの研究が役に立った場合は、以下の論文を引用していただけると幸いです。
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応