%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
Glm 4 9b Chat Hf
GLM-4-9B是智谱AI推出的GLM-4系列最新一代预训练模型的开源版本,具备卓越的语义、数学、推理、代码和知识能力。
下载量 7,919
发布时间 : 10/23/2024
模型简介
GLM-4-9B-Chat是GLM-4-9B的人类偏好对齐版本,支持多轮对话、网页浏览、代码执行、自定义工具调用和长上下文推理(128K上下文)。
模型特点
多语言支持
支持26种语言,包括中文、英文、日语、韩语、德语等。
长上下文推理
支持128K上下文长度,具备强大的长文本处理能力。
工具调用
支持自定义工具调用(Function Call),可执行代码和网页浏览等高级功能。
卓越性能
在语义、数学、推理、代码和知识等数据集评测中超越Llama-3-8B。
模型能力
文本生成
多轮对话
代码执行
网页浏览
工具调用
长上下文推理
使用案例
自然语言处理
多语言对话
支持26种语言的对话交流。
在多语言数据集上表现优异。
代码生成与执行
生成并执行代码片段。
在HumanEval评测中得分71.8。
知识问答
复杂问题解答
回答涉及多领域知识的复杂问题。
在MMLU和C-Eval等评测中表现优异。
🚀 GLM-4-9B-Chat
GLM-4-9B-Chat 是智谱 AI 推出的 GLM-4 系列预训练模型的开源版本。它在语义、数学、推理、代码和知识等数据集评估中表现出色,超越了 Llama-3-8B。除多轮对话外,还具备网页浏览、代码执行、自定义工具调用和长上下文推理等高级功能。
🚀 快速开始
如需更多推理代码和要求,请访问我们的 GitHub 页面。
请严格按照 依赖项 进行安装,否则将无法正常运行。
使用 Transformers 库(4.46.0 及更高版本)进行推理:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('THUDM/glm-4-9b-chat-hf')
model = AutoModelForCausalLM.from_pretrained('THUDM/glm-4-9b-chat-hf', device_map="auto")
message = [
{
"role": "system",
"content": "Answer the following question."
},
{
"role": "user",
"content": "How many legs does a cat have?"
}
]
inputs = tokenizer.apply_chat_template(
message,
return_tensors='pt',
add_generation_prompt=True,
return_dict=True,
).to(model.device)
input_len = inputs['input_ids'].shape[1]
generate_kwargs = {
"input_ids": inputs['input_ids'],
"attention_mask": inputs['attention_mask'],
"max_new_tokens": 128,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][input_len:], skip_special_tokens=True))
使用 vLLM 库(0.6.4 及更高版本)进行推理:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# max_model_len, tp_size = 1048576, 4
# If you encounter OOM phenomenon, it is recommended to reduce max_model_len or increase tp_size
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat-hf"
prompt = [{"role": "user", "content": "what is your name?"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M-HF If you encounter OOM phenomenon, it is recommended to enable the following parameters
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
✨ 主要特性
- 高性能表现:在语义、数学、推理、代码和知识等数据集评估中,GLM-4-9B 及其人工偏好对齐版本 GLM-4-9B-Chat 表现超越 Llama-3-8B。
- 高级功能丰富:除多轮对话外,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长上下文推理(支持高达 128K 上下文)等高级功能。
- 多语言支持:支持日语、韩语和德语等 26 种语言。
- 长上下文模型:推出支持 1M 上下文长度(约 200 万汉字)的 GLM-4-9B-Chat-1M 模型。
- 多模态能力:基于 GLM-4-9B 的多模态模型 GLM-4V-9B 在 1120*1120 的高分辨率下具备中英双语对话能力,在多种多模态评估中表现优于 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus。
📚 详细文档
基准测试
综合基准测试
我们在一些经典任务上对 GLM-4-9B-Chat 模型进行了评估,结果如下:
| 模型 | AlignBench-v2 | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NCB |
|---|---|---|---|---|---|---|---|---|---|
| Llama-3-8B-Instruct | 5.12 | 8.00 | 68.58 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
| ChatGLM3-6B | 3.97 | 5.50 | 28.1 | 66.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
| GLM-4-9B-Chat | 6.61 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
长上下文测试
- 在上下文长度为 1M 的 eval_needle 实验 中,结果如下:
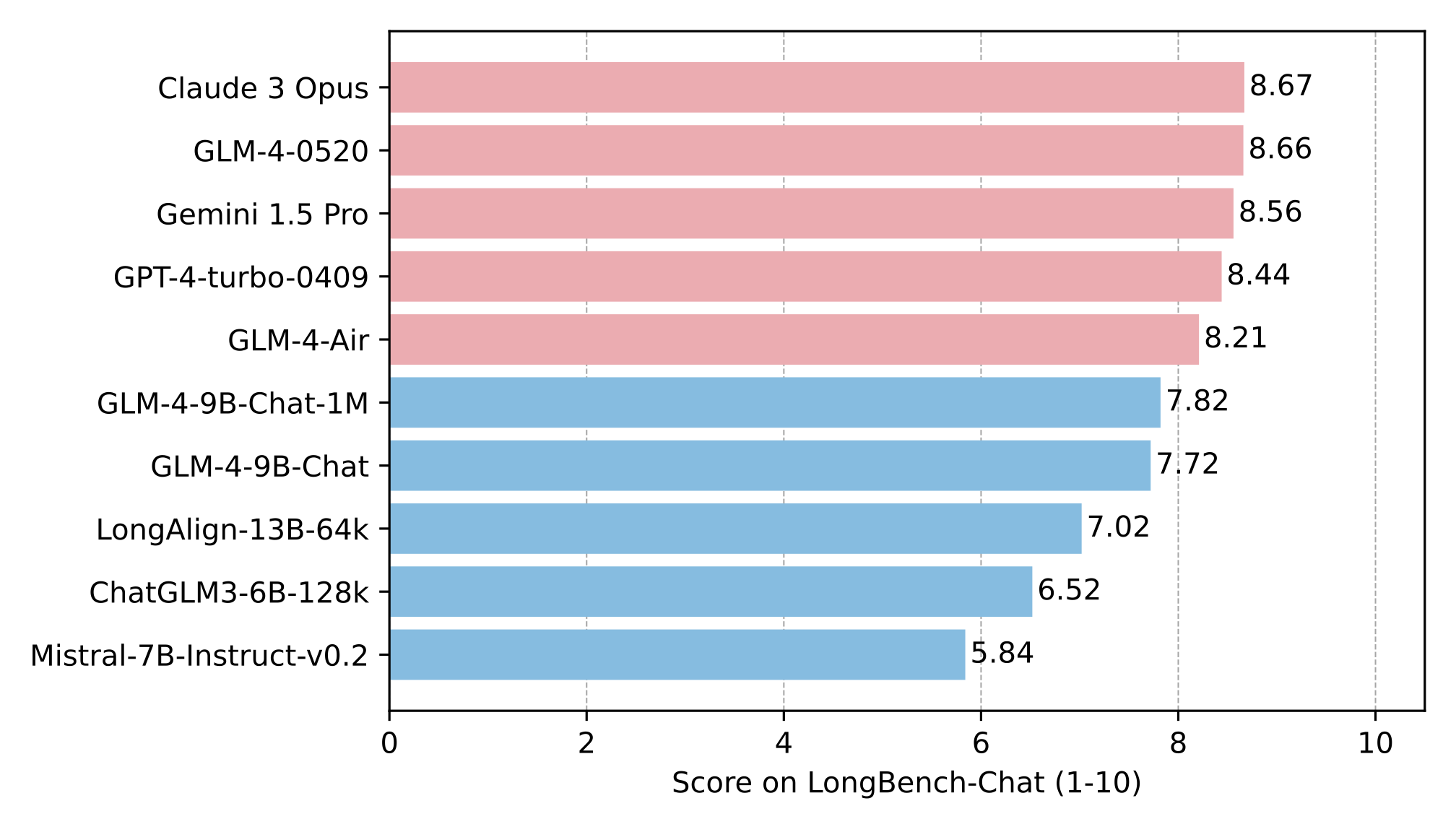
- 在 LongBench 上进一步评估长文本能力,结果如下:
多语言测试
在六个多语言数据集上对 GLM-4-9B-Chat 和 Llama-3-8B-Instruct 进行了测试,测试结果和每个数据集选择的相应语言如下表所示:
| 数据集 | Llama-3-8B-Instruct | GLM-4-9B-Chat | 语言 |
|---|---|---|---|
| M-MMLU | 49.6 | 56.6 | 所有语言 |
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th |
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt |
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te |
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
函数调用测试
在 Berkeley Function Calling Leaderboard 上进行测试,结果如下:
| 模型 | 总体准确率 | AST 摘要 | 执行摘要 | 相关性 |
|---|---|---|---|---|
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
此仓库是 GLM-4-9B-Chat 的模型仓库,支持 128K 上下文长度。
📄 许可证
GLM-4 模型的权重可在 许可证 的条款下使用。
🔖 引用
如果您认为我们的工作有用,请考虑引用以下论文:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
⚠️ 重要提示
如果您使用此仓库中的权重,请更新到 transformers>=4.46.0 ,这些权重与旧版本的 transformers 库 不兼容。
💡 使用建议
请严格按照 依赖项 进行安装,否则模型将无法正常运行。在使用 vLLM 库进行推理时,如果遇到 OOM 现象,建议降低
max_model_len或增加tp_size;对于 GLM-4-9B-Chat-1M-HF,若遇到 OOM 现象,建议启用enable_chunked_prefill=True和max_num_batched_tokens=8192等参数。
Phi 2 GGUF
其他
Phi-2是微软开发的一个小型但强大的语言模型,具有27亿参数,专注于高效推理和高质量文本生成。
大型语言模型 支持多种语言
P
TheBloke
41.5M
205
Roberta Large
MIT
基于掩码语言建模目标预训练的大型英语语言模型,采用改进的BERT训练方法
大型语言模型 英语
R
FacebookAI
19.4M
212
Distilbert Base Uncased
Apache-2.0
DistilBERT是BERT基础模型的蒸馏版本,在保持相近性能的同时更轻量高效,适用于序列分类、标记分类等自然语言处理任务。
大型语言模型 英语
D
distilbert
11.1M
669
Llama 3.1 8B Instruct GGUF
Meta Llama 3.1 8B Instruct 是一个多语言大语言模型,针对多语言对话用例进行了优化,在常见的行业基准测试中表现优异。
大型语言模型 英语
L
modularai
9.7M
4
Xlm Roberta Base
MIT
XLM-RoBERTa是基于100种语言的2.5TB过滤CommonCrawl数据预训练的多语言模型,采用掩码语言建模目标进行训练。
大型语言模型 支持多种语言
X
FacebookAI
9.6M
664
Roberta Base
MIT
基于Transformer架构的英语预训练模型,通过掩码语言建模目标在海量文本上训练,支持文本特征提取和下游任务微调
大型语言模型 英语
R
FacebookAI
9.3M
488
Opt 125m
其他
OPT是由Meta AI发布的开放预训练Transformer语言模型套件,参数量从1.25亿到1750亿,旨在对标GPT-3系列性能,同时促进大规模语言模型的开放研究。
大型语言模型 英语
O
facebook
6.3M
198
1
基于transformers库的预训练模型,适用于多种NLP任务
大型语言模型 Transformers
Transformers
1
unslothai
6.2M
1
Llama 3.1 8B Instruct
Llama 3.1是Meta推出的多语言大语言模型系列,包含8B、70B和405B参数规模,支持8种语言和代码生成,优化了多语言对话场景。
大型语言模型 Transformers 支持多种语言
L
meta-llama
5.7M
3,898
T5 Base
Apache-2.0
T5基础版是由Google开发的文本到文本转换Transformer模型,参数规模2.2亿,支持多语言NLP任务。
大型语言模型 支持多种语言
T
google-t5
5.4M
702
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98