🚀 子牙-LLaMA-13B-预训练-v1
子牙-LLaMA-13B-预训练-v1は、中文の生成と理解能力を向上させた大規模事前学習モデルです。本モデルはLLaMAに基づき、中文のトークナイザーを最適化し、1100億トークンの中英語データで事前学習を行っています。
🚀 クイックスタート
(LLaMAのウェイトに関するライセンス制限のため、完全なモデルウェイトを直接公開することはできません。ユーザーは使用方法を参照してウェイトをマージする必要があります。)
✨ 主な機能
姜子牙シリーズモデル
概要
子牙-LLaMA-13B-預訓練-v1は、LLaMAに基づく130億パラメータの大規模事前学習モデルです。中文のトークナイザーを最適化し、中英語の1100億トークンのデータで事前学習を行い、中文の生成と理解能力を向上させました。現在の姜子牙汎用大規模言語モデル 子牙-LLaMA-13B-v1 は、このモデルをベースに、多タスクの教師付き微調整と人間のフィードバック学習を行い、翻訳、プログラミング、テキスト分類、情報抽出、要約、コピーライティング、一般知識の質問応答、数学計算などの能力を備えています。
ユーザーへの注意事項:Metaが公開したLLaMAモデルのライセンスに従うため、このモデルでは事前学習前後のウェイトの差分を公開しています。最終的なモデルは、スクリプトを使用して簡単に取得できます(使用方法を参照)。
📚 ドキュメント
モデル分類
| 要件 |
タスク |
シリーズ |
モデル |
パラメータ |
追加情報 |
| 汎用 |
AGIモデル |
姜子牙 |
LLaMA |
13B |
英語と中国語 |
モデル情報
継続事前学習
元のデータには英語と中国語が含まれています。英語のデータはopenwebtext、Books、Wikipedia、Codeから取得され、中国語のデータは洗浄された悟道データセットと自社で構築した中国語データセットから取得されました。元のデータを重複排除、モデルスコアリング、データバケット化、ルールフィルタリング、敏感トピックフィルタリング、データ評価した後、最終的に1250億トークンの有効データが得られました。
LLaMAの元のトークナイザーが中国語のエンコードとデコードの効率が低い問題を解決するため、LLaMAの語彙に7000以上の一般的な中国語文字を追加し、LLaMAの元の語彙と重複排除して、最終的に39410の語彙を得ました。これは、TransformersのLlamaTokenizerを再利用することで実現されました。
増分学習の過程では、160枚の40GBのA100を使用し、260万トークンの学習セットサンプル数とFP16の混合精度を採用し、スループットはGPUあたり118TFLOP/秒に達しました。これにより、8日間で元のLLaMA-13Bモデルに基づいて1100億トークンのデータを増分学習することができました。私たちの知る限り、これはLLaMA-13Bでこれまでで最大規模の増分学習です。
学習中は、マシンのクラッシュ、基盤フレームワークのバグ、損失の急激な変動など、さまざまな問題に直面しましたが、迅速な調整により増分学習の安定性を確保しました。また、学習過程の損失曲線も公開して、起こりうる問題を理解してもらえるようにしています。
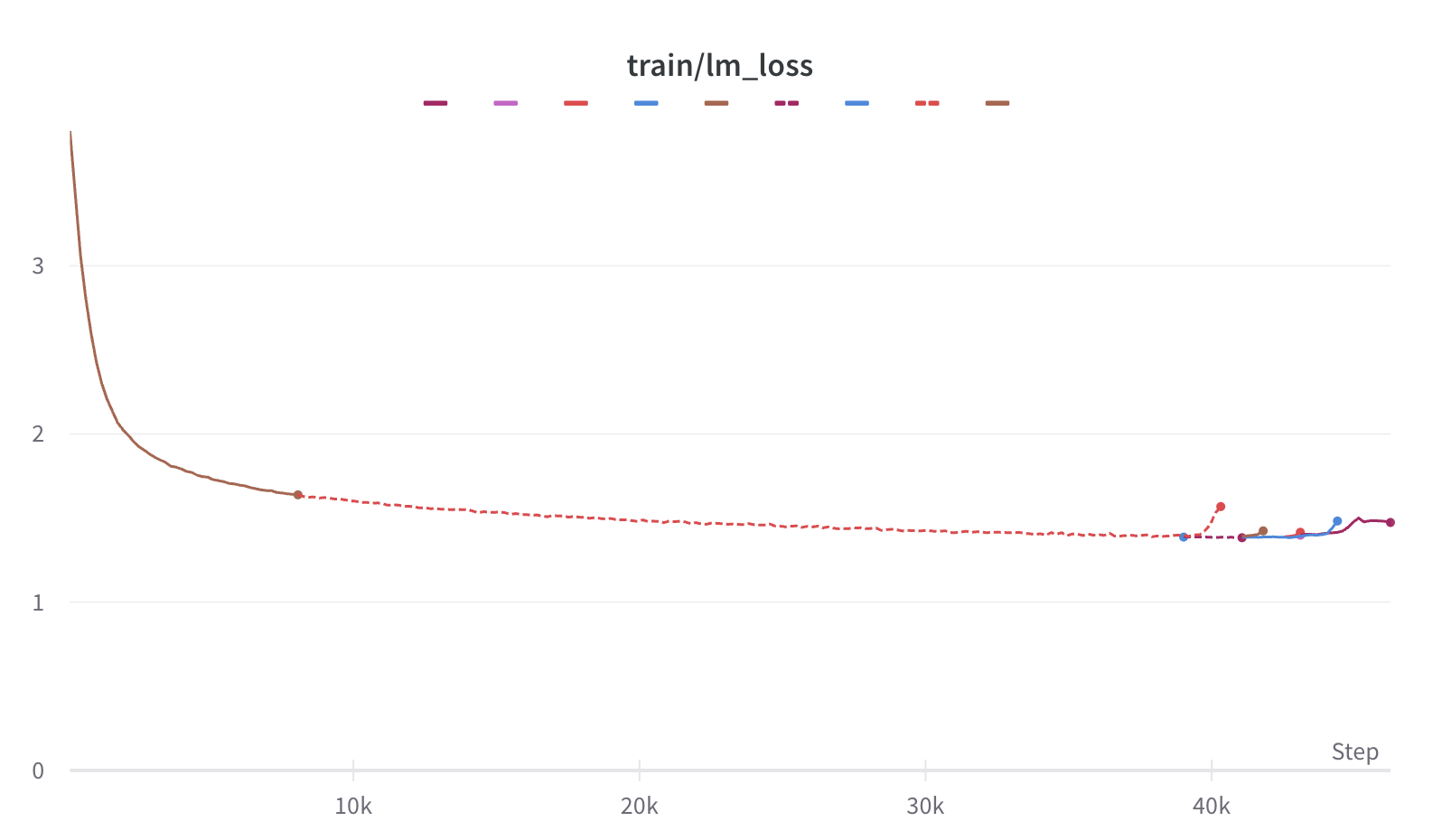
性能評価
以下は、子牙-LLaMA-13B-預訓練-v1と事前学習前のLLaMAモデルを、英語の公開評価 HeLM と中国語の多肢選択評価セットで評価した結果の比較です。
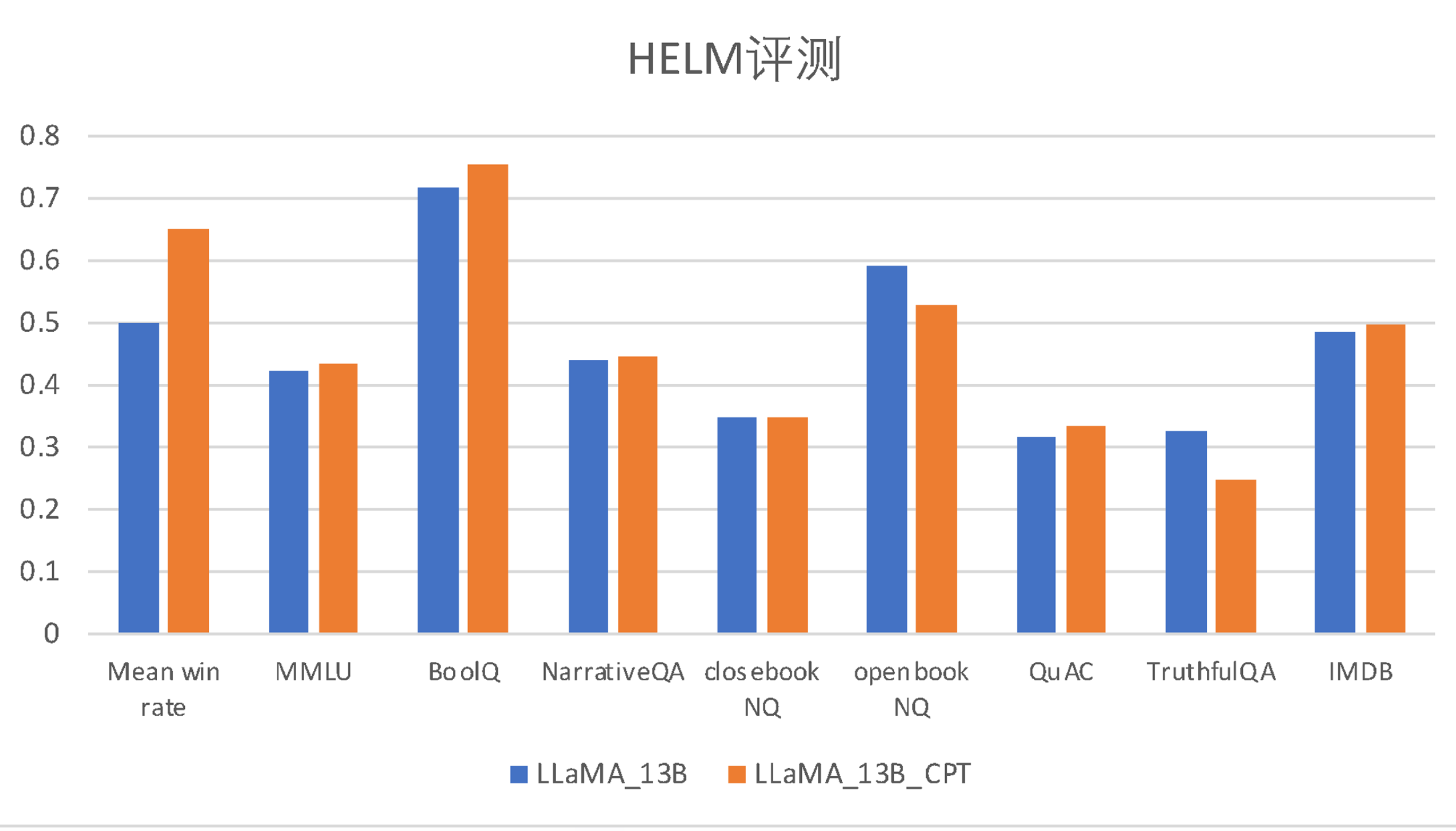
| モデル |
平均勝率 |
MMLU |
BoolQ |
NarrativeQA |
NaturalQuestion(クローズドブック) |
NaturalQuestion(オープンブック) |
QuAC |
TruthfulQA |
IMDB |
| LLaMA-13B |
0.500 |
0.424 |
0.718 |
0.440 |
0.349 |
0.591 |
0.318 |
0.326 |
0.487 |
| 子牙-LLaMA-13B-預訓練-v1 |
0.650 |
0.433 |
0.753 |
0.445 |
0.348 |
0.528 |
0.335 |
0.249 |
0.497 |
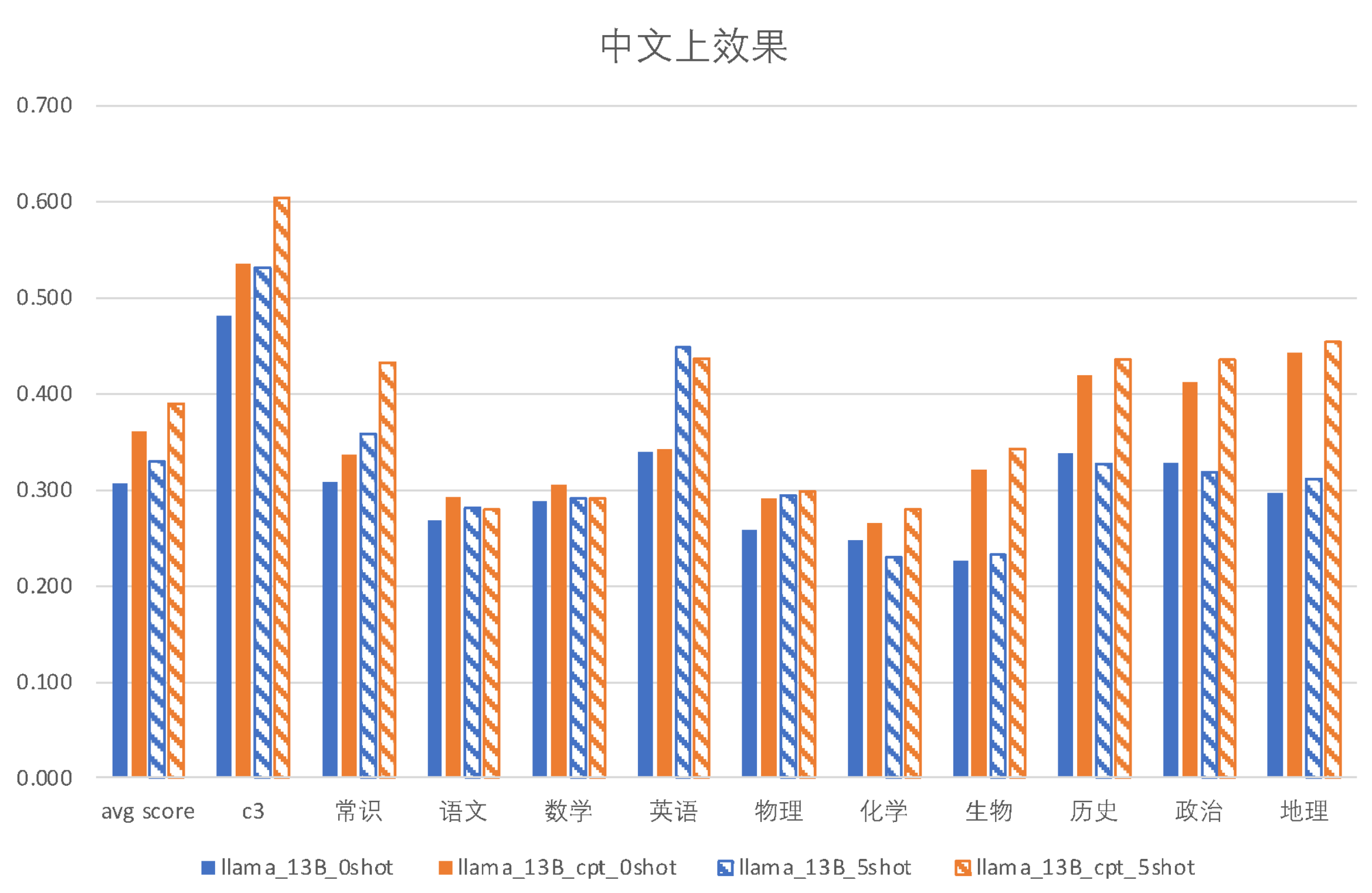
| モデル |
インコンテキスト |
c3 |
一般知識 |
国語 |
数学 |
英語 |
物理 |
化学 |
生物 |
歴史 |
政治 |
地理 |
| LLaMA-13B (0-shot) |
0-shot |
0.4817 |
0.3088 |
0.2674 |
0.2882 |
0.3399 |
0.2581 |
0.2478 |
0.2271 |
0.3380 |
0.3275 |
0.296 |
| 子牙-LLaMA-13B-預訓練-v1 (0-shot) |
0-shot |
0.5354 |
0.3373 |
0.2925 |
0.3059 |
0.3428 |
0.2903 |
0.2655 |
0.3215 |
0.4190 |
0.4123 |
0.4425 |
| LLaMA-13B (5-shot) |
5-shot |
0.5314 |
0.3586 |
0.2813 |
0.2912 |
0.4476 |
0.2939 |
0.2301 |
0.2330 |
0.3268 |
0.3187 |
0.3103 |
| 子牙-LLaMA-13B-預訓練-v1 (5-shot) |
5-shot |
0.6037 |
0.4330 |
0.2802 |
0.2912 |
0.4363 |
0.2975 |
0.2802 |
0.3422 |
0.4358 |
0.4357 |
0.4540 |
💻 使用例
基本的な使用法
LLaMAのウェイトに関するライセンス制限のため、このモデルは商用利用には使用できません。LLaMAの使用ポリシーを厳守してください。LLaMAのウェイトに関するライセンス制限のため、完全なモデルウェイトを直接公開することはできません。そのため、FastChatオープンソースツール をベースにさらに最適化を行いました。子牙-LLaMA-13B-v1のウェイトと元のLLaMAのウェイトの差分を計算して公開しています。ユーザーは以下の手順で子牙-LLaMA-13B-v1の完全なウェイトを取得できます。
Step 1: LLaMA のウェイトを取得し、Hugging Face Transformersモデル形式に変換します。変換 スクリプト を参照できます(すでにHugging Faceのウェイトを持っている場合はこの手順をスキップ)。
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Step 2: 子牙-LLaMA-13B-v1のdeltaウェイトとStep 1で変換した元のLLaMAのウェイトをダウンロードし、以下のスクリプトを使用して変換します:https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1
Step 3: Step 2で得られたモデルをロードして推論を行います。
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
query="帮我写一份去西安的旅游计划"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt)
inputs = query.strip()
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
高度な使用法
📄 ライセンス
本モデルはGPL-3.0ライセンスの下で公開されています。
引用
もしあなたの研究や開発でこのモデルを使用した場合、以下の論文を引用してください:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
また、以下のウェブサイトも引用することができます:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応