🚀 Ziya-LLaMA-13B-Pretrain-v1
Ziya-LLaMA-13B-Pretrain-v1 is a large-scale pre-trained model based on LLaMA, optimized for Chinese tokenization and further enhancing Chinese generation and understanding capabilities.
🚀 Quick Start
Due to the license restrictions of LLaMA weights, this model cannot be used for commercial purposes. Please strictly adhere to the LLaMA usage policy. We cannot directly release the complete model weights. Therefore, we used the FastChat open-source tool as a basis and further optimized it. We calculated and released the difference between the Ziya-LLaMA-13B-v1 weights and the original LLaMA weights. Users can follow the steps below to obtain the complete weights of Ziya-LLaMA-13B-v1:
Step 1: Obtain the LLaMA weights and convert them into the Hugging Face Transformers model format. You can refer to the conversion script (skip this step if you already have the Hugging Face weights).
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Step 2: Download the delta weights of Ziya-LLaMA-13B-v1 and the pre-converted original LLaMA weights from step 1. Use the following script for conversion: https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py.
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1
Step 3: Load the model obtained in step 2 for inference.
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
query="帮我写一份去西安的旅游计划"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt)
inputs = query.strip()
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
✨ Features
- Optimized for Chinese: Optimized the LLaMA tokenizer for Chinese, adding 7k+ common Chinese characters to the LLaMA vocabulary, significantly improving the encoding and decoding efficiency of Chinese.
- Large-scale Incremental Training: Incrementally trained 110 billion tokens of data on the native LLaMA-13B model, which is the largest-scale incremental training on LLaMA-13B so far.
- Enhanced Performance: The Ziya-LLaMA-13B-v1 model, based on this pre-trained model, has the ability to perform tasks such as translation, programming, text classification, information extraction, summarization, copywriting, common sense Q&A, and mathematical calculation.
📦 Installation
Not provided in the original document, so this section is skipped.
💻 Usage Examples
Basic Usage
The steps to obtain the complete model weights and perform inference are described in the "Quick Start" section.
Advanced Usage
Not provided in the original document, so this part is skipped.
📚 Documentation
Brief Introduction
The Ziya-LLaMA-13B-Pretrain-v1 is a large-scale pre-trained model based on LLaMA with 13 billion parameters. We optimized the LLaMA tokenizer for Chinese and incrementally trained 110 billion tokens of data on the LLaMA-13B model, which significantly improved the understanding and generation ability on Chinese. Based on the Ziya-LLaMA-13B-Pretrain-v1, the Ziya-LLaMA-13B-v1 is further trained with two stages: multi-task supervised fine-tuning (SFT) and human feedback learning (RM, PPO). The Ziya-LLaMA-13B-v1 has the ability to perform tasks such as translation, programming, text classification, information extraction, summarization, copywriting, common sense Q&A, and mathematical calculation.
README: To follow the License of LLaMA released by Meta, we only release the incremental weights after continual pretraining. The final model Ziya-LLaMA-13B-Pretrain-v1 could be easily got via the script (refer to Usage).
Model Taxonomy
| Property |
Details |
| Demand |
General |
| Task |
AGI Model |
| Series |
Ziya |
| Model |
LLaMA |
| Parameter |
13B |
| Extra |
English & Chinese |
Model Information
Continual Pretraining
The original data contains both English and Chinese, with English data from openwebtext, Books, Wikipedia, and Code, and Chinese data from the cleaned Wudao dataset and self-built Chinese dataset. After deduplication, model scoring, data bucketing, rule filtering, sensitive topic filtering, and data evaluation, we finally obtained 125 billion tokens of data.
To address the issue of low efficiency in Chinese encoding and decoding caused by the tokenizer of LLaMa, we added 8,000 commonly used Chinese characters to the LLaMa SentencePiece vocabulary. Deduplicating with the original LLaMa vocabulary, we finally obtained a vocabulary of size 39,410. We achieved this by reusing the LlamaTokenizer in Transformers.
During the incremental training process, we used 160 A100s with a total of 40GB memory, using a training dataset with 2.6 million tokens and mixed precision of FP16. The throughput reached 118 TFLOP per GPU per second. As a result, we were able to incrementally train 110 billion tokens of data on the native LLaMA-13B model in just 8 days. As far as we know, this is also the largest-scale incremental training on LLaMA-13B to date.
Throughout the training process, we encountered various issues such as machine crashes, underlying framework bugs, and loss spikes. However, we ensured the stability of the incremental training by making rapid adjustments. We also released the loss curve during the training process to help everyone understand the potential issues that may arise.
Performance
Here are comparisons of the Ziya-LLaMA-13B-Pretrain-v1 model and the LLaMA model before continual pre-training, evaluated on the English benchmark (HeLM) and our Chinese multiple-choice evaluation datasets.
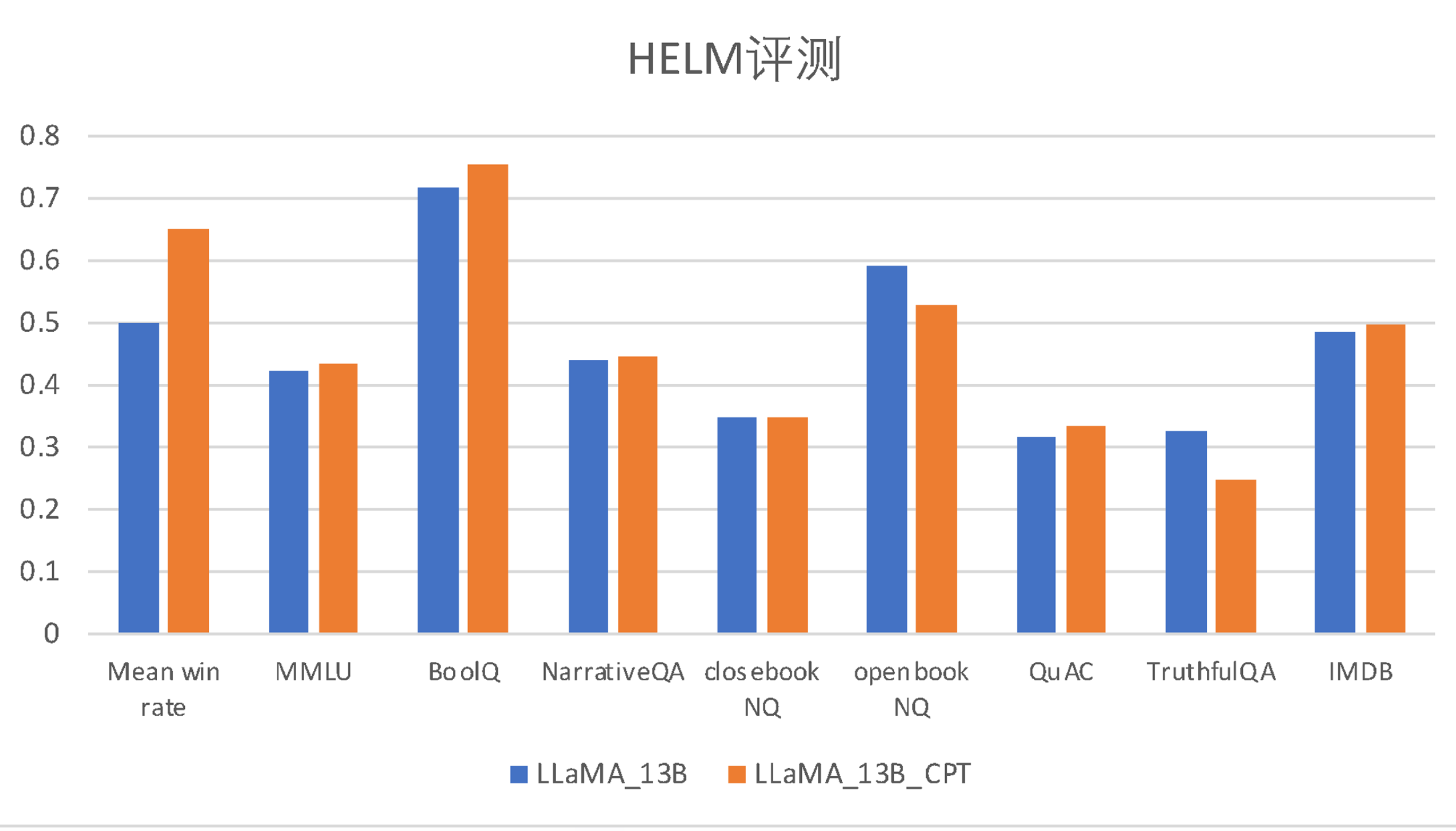
| Model |
Meanwin_rate |
MMLU |
BoolQ |
NarrativeQA |
NaturalQuestion(closed-book) |
NaturalQuestion(open-book) |
QuAC |
TruthfulQA |
IMDB |
| LLaMA-13B |
0.500 |
0.424 |
0.718 |
0.440 |
0.349 |
0.591 |
0.318 |
0.326 |
0.487 |
| Ziya-LLaMA-13B-Pretrain-v1 |
0.650 |
0.433 |
0.753 |
0.445 |
0.348 |
0.528 |
0.335 |
0.249 |
0.497 |
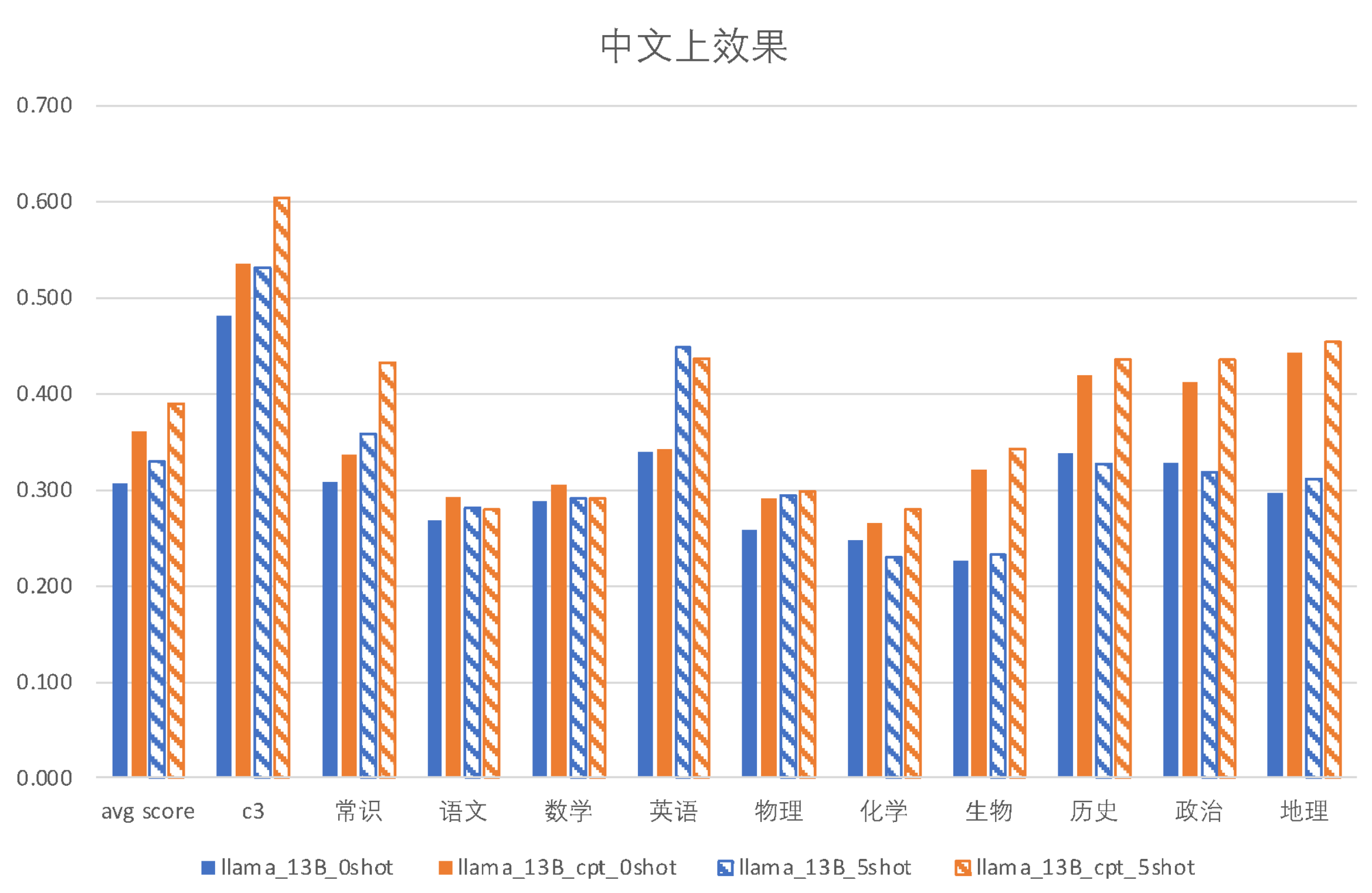
| Model |
incontext |
c3 |
Common Sense |
Chinese |
Math |
English |
Physics |
Chemistry |
Biology |
History |
Politics |
Geography |
| LLaMA-13B |
0-shot |
0.4817 |
0.3088 |
0.2674 |
0.2882 |
0.3399 |
0.2581 |
0.2478 |
0.2271 |
0.3380 |
0.3275 |
0.296 |
| Ziya-LLaMA-13B-Pretrain-v1 |
0-shot |
0.5354 |
0.3373 |
0.2925 |
0.3059 |
0.3428 |
0.2903 |
0.2655 |
0.3215 |
0.4190 |
0.4123 |
0.4425 |
| LLaMA-13B |
5-shot |
0.5314 |
0.3586 |
0.2813 |
0.2912 |
0.4476 |
0.2939 |
0.2301 |
0.2330 |
0.3268 |
0.3187 |
0.3103 |
| Ziya-LLaMA-13B-Pretrain-v1 |
5-shot |
0.6037 |
0.4330 |
0.2802 |
0.2912 |
0.4363 |
0.2975 |
0.2802 |
0.3422 |
0.4358 |
0.4357 |
0.4540 |
Finetune Example
Refer to ziya_finetune
Inference & Quantization Example
Refer to ziya_inference
Citation
If you are using the resource for your work, please cite our paper:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
You can also cite our website:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
🔧 Technical Details
Not provided in the original document, so this section is skipped.
📄 License
The model is licensed under GPL-3.0.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)