🚀 WizardMath: 強化進化命令(RLEIF)による大規模言語モデルの数学的推論能力の強化
WizardMathは、強化進化命令(RLEIF)を通じて大規模言語モデルの数学的推論能力を強化するプロジェクトです。複数のモデルバージョンを提供し、様々なベンチマークで高い性能を発揮しています。
🤗 HFリポジトリ •🐱 GitHubリポジトリ • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Discordに参加しましょう
📊 モデル情報
WizardCoder関連モデル
WizardMath関連モデル
WizardLM関連モデル
| モデル |
チェックポイント |
論文 |
MT-Bench |
AlpacaEval |
GSM8k |
HumanEval |
ライセンス |
| WizardLM-70B-V1.0 |
🤗 HFリンク |
📃近日公開予定 |
7.78 |
92.91% |
77.6% |
50.6 pass@1 |
Llama 2 ライセンス |
| WizardLM-13B-V1.2 |
🤗 HFリンク |
|
7.06 |
89.17% |
55.3% |
36.6 pass@1 |
Llama 2 ライセンス |
| WizardLM-13B-V1.1 |
🤗 HFリンク |
|
6.76 |
86.32% |
|
25.0 pass@1 |
非商用 |
| WizardLM-30B-V1.0 |
🤗 HFリンク |
|
7.01 |
|
|
37.8 pass@1 |
非商用 |
| WizardLM-13B-V1.0 |
🤗 HFリンク |
|
6.35 |
75.31% |
|
24.0 pass@1 |
非商用 |
| WizardLM-7B-V1.0 |
🤗 HFリンク |
📃 [WizardLM] |
|
|
|
19.1 pass@1 |
非商用 |
GitHubリポジトリ: https://github.com/nlpxucan/WizardLM/tree/main/WizardMath
Twitter: https://twitter.com/WizardLM_AI/status/1689998428200112128
Discord: https://discord.gg/VZjjHtWrKs
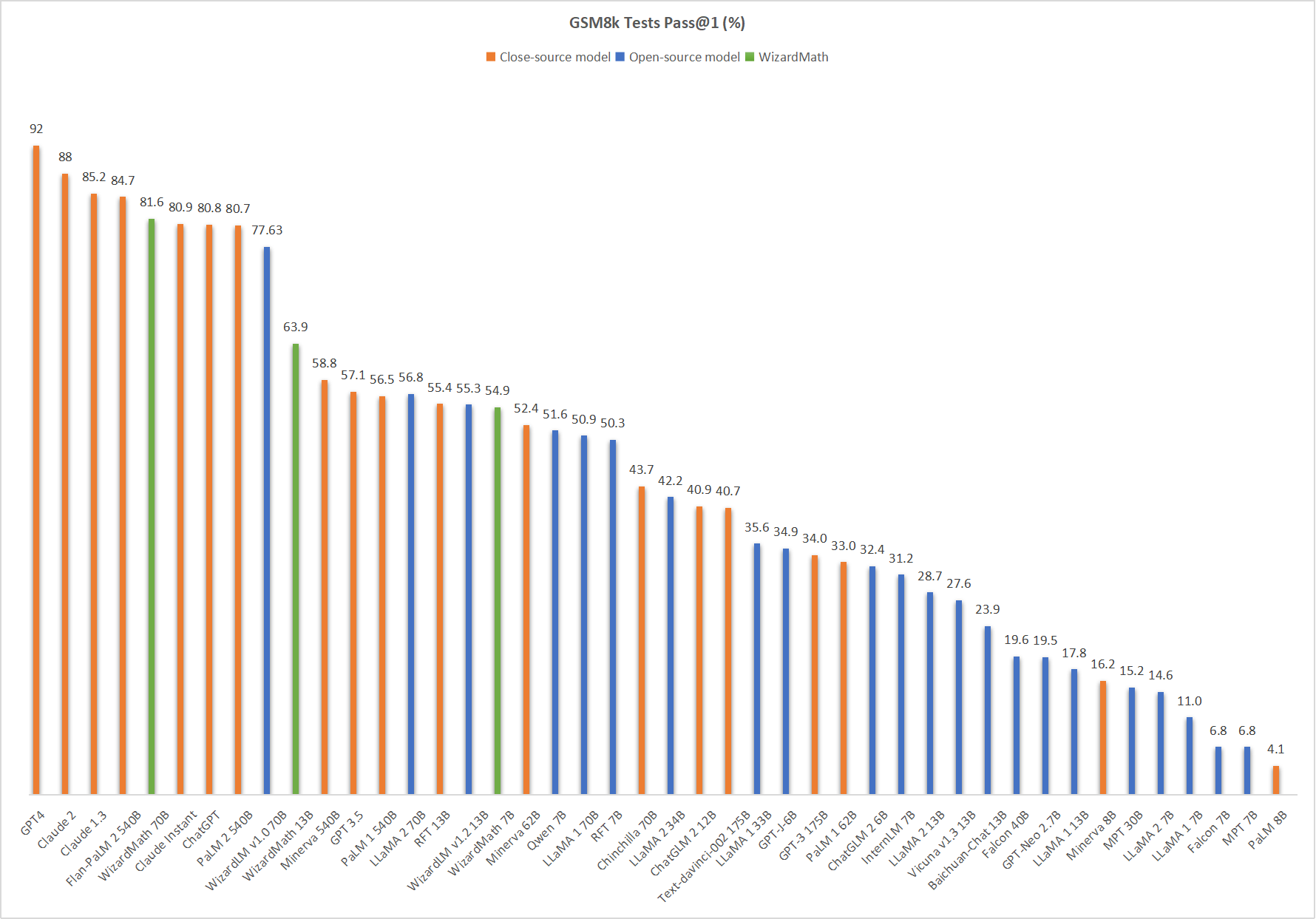
📊 WizardMath-V1.0と他のLLMの比較
🔥 以下の図は、私たちのWizardMath-70B-V1.0がこのベンチマークで5位にランクインし、ChatGPT (81.6 vs. 80.8)、Claude Instant (81.6 vs. 80.9)、PaLM 2 540B (81.6 vs. 80.7)を上回っていることを示しています。
⚠️ 重要提示
モデルのシステムプロンプトの使用に関する注意事項です。私たちと厳密に同じシステムプロンプトを使用してください。また、定量化されたバージョンの精度は保証していません。
デフォルトバージョン
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
CoTバージョン
(❗ 簡単な数学問題に対しては、CoTプロンプトの使用はお勧めしません。)
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response: Let's think step by step."
💻 WizardMath推論デモスクリプト
私たちは、WizardMathの推論デモコードをこちらで提供しています。
⚠️ 重要提示
最近、組織全体のコード、データ、モデルのオープンソースポリシーと規制に明確な変更がありました。それにもかかわらず、私たちはまだモデルの重みを公開するために努力してきましたが、データにはより厳格な審査が必要であり、法務チームによるレビュー中です。研究者は、許可なく公開する権限を持っていません。ご理解いただければ幸いです。
📄 引用
このリポジトリのデータ、方法、またはコードを使用する場合は、以下のように引用してください。
@article{luo2023wizardmath,
title={WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct},
author={Luo, Haipeng and Sun, Qingfeng and Xu, Can and Zhao, Pu and Lou, Jianguang and Tao, Chongyang and Geng, Xiubo and Lin, Qingwei and Chen, Shifeng and Zhang, Dongmei},
journal={arXiv preprint arXiv:2308.09583},
year={2023}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応