🚀 42dot_LLM-PLM-1.3B
42dot LLM-PLM は、42dot 42dot LLM (大規模言語モデル)の一部です。42dot LLM-PLM は、韓国語と英語のテキストコーパスを使用して事前学習されており、いくつかの韓国語と英語の自然言語タスクの基礎言語モデルとして使用できます。このリポジトリには、パラメータ数が 13 億のモデルのバージョンが含まれています。
🚀 クイックスタート
このセクションでは、42dot LLM-PLM-1.3B の概要を説明し、その特徴や事前学習の詳細について解説します。
✨ 主な機能
韓国語と英語の自然言語タスクに対応した事前学習言語モデル。
Transformer デコーダーアーキテクチャをベースに構築されている。
公開されている多様なテキストコーパスを使用して事前学習されている。
📚 ドキュメント
ハイパーパラメータ
42dot LLM-PLM は、LLaMA 2 と同様の Transformer デコーダーアーキテクチャをベースに構築されており、そのハイパーパラメータは以下の通りです。
パラメータ
レイヤー数
アテンションヘッド数
隠れ層サイズ
FFN サイズ
13 億
24
32
2,048
5,632
事前学習
事前学習には、約 49,000 GPU 時間(NVIDIA A100)がかかりました。関連する設定は以下の通りです。
パラメータ
グローバルバッチサイズ*
初期学習率
トレーニングイテレーション数*
最大長*
重み減衰
13 億
400 万
4E-4
140 兆
4,096
0.1
(* 単位: トークン)
事前学習データセット
以下の公開されているテキストコーパスを使用しました。
トークナイザー
トークナイザーは、Byte-level BPE アルゴリズムに基づいています。事前学習コーパスのサブセットを使用して、語彙を最初から学習しました。サブセットを構築するために、韓国語と英語のコーパスからそれぞれ 1000 万件のドキュメントをサンプリングしました。結果として得られた語彙サイズは約 5 万です。
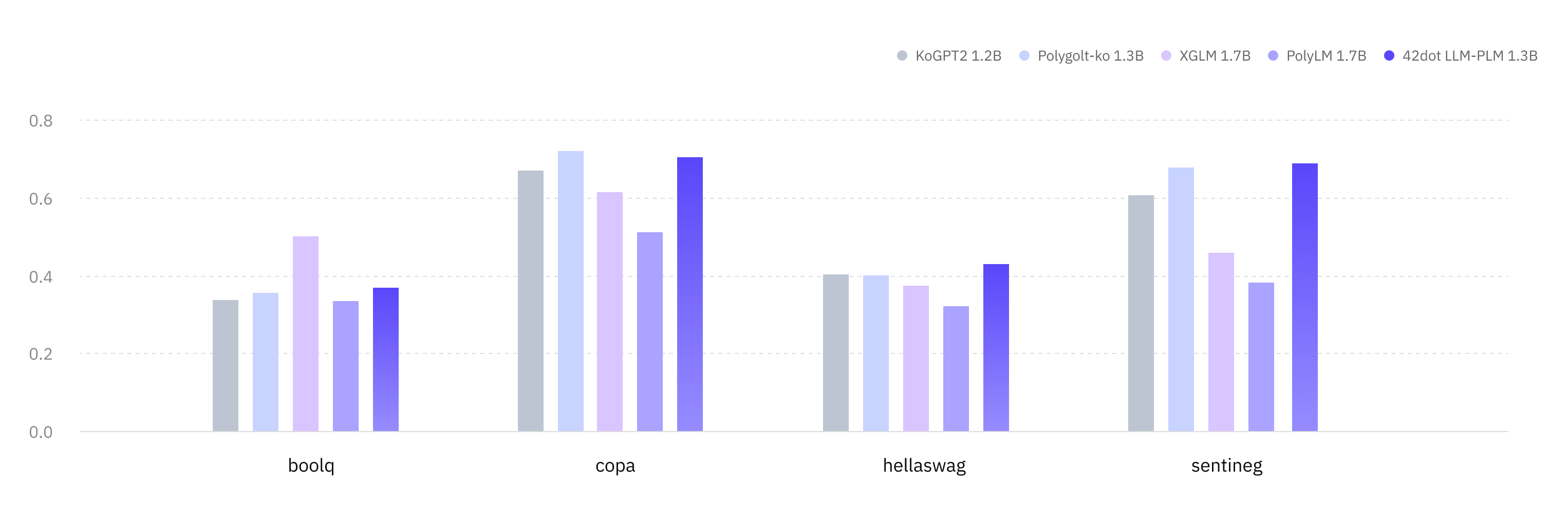
ゼロショット評価
42dot LLM-PLM を、韓国語と英語の様々な学術的ベンチマークで評価しました。すべての結果は、lm-eval-harness と Hugging Face Hub で公開されているモデルを使用して取得されています。
韓国語 (KOBEST)
タスク / Macro-F1
KoGPT2 Polyglot-Ko XGLM PolyLM 42dot LLM-PLM
boolq
0.337
0.355
0.502 0.334
0.369
copa
0.67
0.721 0.616
0.513
0.704
hellaswag
0.404
0.401
0.374
0.321
0.431
sentineg
0.606
0.679
0.46
0.382
0.69
平均 0.504
0.539
0.488
0.388
0.549
英語
タスク / メトリック
MPT
OPT
XGLM
PolyLM
42dot LLM-PLM
anli_r1/acc
0.309
0.341 0.334
0.336
0.325
anli_r2/acc
0.334
0.339
0.331
0.314
0.34
anli_r3/acc
0.33
0.336
0.333
0.339 0.333
arc_challenge/acc
0.268
0.234
0.21
0.198
0.288
arc_challenge/acc_norm
0.291
0.295
0.243
0.256
0.317
arc_easy/acc
0.608
0.571
0.537
0.461
0.628
arc_easy/acc_norm
0.555
0.51
0.479
0.404
0.564
boolq/acc
0.517
0.578
0.585
0.617
0.624
hellaswag/acc
0.415
0.415
0.362
0.322
0.422
hellaswag/acc_norm
0.532
0.537
0.458
0.372
0.544
openbookqa/acc
0.238 0.234
0.17
0.166
0.222
openbookqa/acc_norm
0.334
0.334
0.298
0.334
0.34
piqa/acc
0.714
0.718
0.697
0.667
0.725
piqa/acc_norm
0.72
0.724
0.703
0.649
0.727
record/f1
0.84
0.857 0.775
0.681
0.848
record/em
0.832
0.849 0.769
0.674
0.839
rte/acc
0.541
0.523
0.559 0.513
0.542
truthfulqa_mc/mc1
0.224
0.237
0.215
0.251 0.236
truthfulqa_mc/mc2
0.387
0.386
0.373
0.428 0.387
wic/acc
0.498
0.509 0.503
0.5
0.502
winogrande/acc
0.574
0.595 0.55
0.519
0.583
平均 0.479
0.482
0.452
0.429
0.492
🔧 技術詳細
42dot LLM-PLM は、他の大規模言語モデル(LLM)と同様の多くの既知の制限があります。例えば、42dot LLM-PLM も 幻覚現象 の影響を受けるため、誤った情報や誤解を招く内容を生成する可能性があります。また、ウェブ上で利用可能な学習データを使用しているため、有毒な、有害な、偏った内容を生成する可能性があります。42dot LLM-PLM のユーザーは、これらの制限を認識し、それらの問題を軽減するために必要な措置を講じることを強くお勧めします。
📄 ライセンス
42dot LLM-PLM は、Creative Commons Attribution-NonCommercial 4.0(CC BY-NC 4.0)ライセンスの下で提供されています。
引用
@misc{42dot2023llm,
title={42dot LLM: A Series of Large Language Model by 42dot},
author={42dot Inc.},
year={2023},
url = {https://github.com/42dot/42dot_LLM},
version = {1.0.0},
}
⚠️ 重要提示
42dot LLM シリーズ(「42dot LLM」)によって生成される内容は、必ずしも 42dot Inc.(「42dot」)の見解や意見を反映しているとは限りません。42dot は、42dot LLM およびその生成内容の使用に起因する直接的、間接的、黙示的、懲罰的、特別な、偶発的、またはその他の結果的損害に対して、いかなる責任も負いません。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

 Transformers 複数言語対応
Transformers 複数言語対応