%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Llama 3 8B 64K
Llama 3 8B 64K模型借助PoSE技术将Llama的上下文长度从8k扩展到64k,在特定数据集上进行训练,优化了语言生成能力,适用于对话等多种自然语言处理场景。
![]()
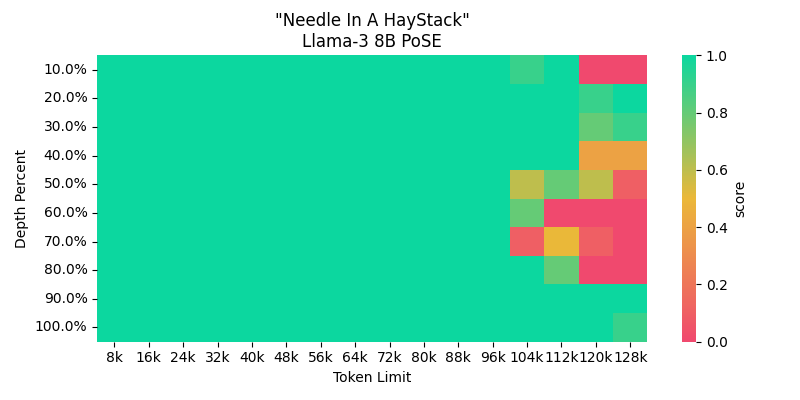
该模型使用PoSE将Llama的上下文长度从8k扩展到64k,rope_theta设置为500000.0。我们在RedPajama V1数据集中6k - 8k标记的3亿个标记上使用PoSE进行持续预训练。
在持续预训练之后,我们进一步将rope_theta设置为200万,以潜在地将上下文扩展到64k以上。
该模型在RedPajama v1数据集的一个子集上进行训练,文本上下文长度在6k - 8k之间。我们训练了一个秩稳定的LoRA,秩为256。WandB
📚 详细文档
模型详情
Meta开发并发布了Meta Llama 3系列大语言模型(LLM),这是一组包含80亿和700亿参数的预训练和指令调优生成式文本模型。Llama 3指令调优模型针对对话用例进行了优化,在常见行业基准测试中优于许多可用的开源聊天模型。此外,在开发这些模型时,我们非常注重优化模型的实用性和安全性。
| 属性 | 详情 |
|---|---|
| 模型开发者 | Meta |
| 变体 | Llama 3有两种规模——80亿和700亿参数,包括预训练和指令调优变体 |
| 输入 | 模型仅接受文本输入 |
| 输出 | 模型仅生成文本和代码 |
| 模型架构 | Llama 3是一种自回归语言模型,采用优化的Transformer架构。调优版本使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)来符合人类对实用性和安全性的偏好 |
预期用途
- 预期用例:Llama 3旨在用于英语商业和研究用途。指令调优模型适用于类似助手的聊天场景,而预训练模型可用于各种自然语言生成任务。
- 超出范围的使用:以任何违反适用法律法规(包括贸易合规法律)的方式使用;以《可接受使用政策》和《Llama 3社区许可协议》禁止的任何其他方式使用;使用除英语以外的其他语言。
⚠️ 重要提示
开发者可以在遵守《Llama 3社区许可协议》和《可接受使用政策》的前提下,对Llama 3模型进行微调以支持英语以外的其他语言。
💻 使用示例
基础用法
本仓库包含两个版本的Meta-Llama-3-8B,分别适用于transformers库和原始llama3代码库。
使用transformers库
以下是使用transformers库的代码示例:
>>> import transformers
>>> import torch
>>> model_id = "meta-llama/Meta-Llama-3-8B"
>>> pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
>>> pipeline("Hey how are you doing today?")
使用llama3代码库
请遵循仓库中的说明。
要下载原始检查点,请参考以下使用huggingface-cli的示例命令:
huggingface-cli download meta-llama/Meta-Llama-3-8B --include "original/*" --local-dir Meta-Llama-3-8B
对于Hugging Face支持,我们建议使用transformers或TGI,但类似的命令也适用。
🔧 技术细节
硬件和软件
- 训练因素:我们使用自定义训练库、Meta的研究超级集群和生产集群进行预训练。微调、注释和评估也在第三方云计算平台上进行。
- 碳足迹:预训练在H100 - 80GB类型的硬件上累计使用了770万个GPU小时的计算资源(TDP为700W)。估计总排放量为2290吨二氧化碳当量,其中100%由Meta的可持续发展计划进行了抵消。
| 模型 | 时间(GPU小时) | 功耗(W) | 碳排放(tCO2eq) |
|---|---|---|---|
| Llama 3 8B | 130万 | 700 | 390 |
| Llama 3 70B | 640万 | 700 | 1900 |
| 总计 | 770万 | - | 2290 |
训练数据
- 概述:Llama 3在超过15万亿个来自公开可用来源的标记数据上进行预训练。微调数据包括公开可用的指令数据集以及超过1000万个经过人工注释的示例。预训练和微调数据集均不包含Meta用户数据。
- 数据新鲜度:预训练数据的截止时间分别为7B模型的2023年3月和70B模型的2023年12月。
基准测试
在本节中,我们报告了Llama 3模型在标准自动基准测试中的结果。所有评估均使用我们的内部评估库。有关方法论的详细信息,请参阅此处。
基础预训练模型
| 类别 | 基准测试 | Llama 3 8B | Llama2 7B | Llama2 13B | Llama 3 70B | Llama2 70B |
|---|---|---|---|---|---|---|
| 通用 | MMLU (5-shot) | 66.6 | 45.7 | 53.8 | 79.5 | 69.7 |
| 通用 | AGIEval English (3 - 5 shot) | 45.9 | 28.8 | 38.7 | 63.0 | 54.8 |
| 通用 | CommonSenseQA (7-shot) | 72.6 | 57.6 | 67.6 | 83.8 | 78.7 |
| 通用 | Winogrande (5-shot) | 76.1 | 73.3 | 75.4 | 83.1 | 81.8 |
| 通用 | BIG-Bench Hard (3-shot, CoT) | 61.1 | 38.1 | 47.0 | 81.3 | 65.7 |
| 通用 | ARC-Challenge (25-shot) | 78.6 | 53.7 | 67.6 | 93.0 | 85.3 |
| 知识推理 | TriviaQA-Wiki (5-shot) | 78.5 | 72.1 | 79.6 | 89.7 | 87.5 |
| 阅读理解 | SQuAD (1-shot) | 76.4 | 72.2 | 72.1 | 85.6 | 82.6 |
| 阅读理解 | QuAC (1-shot, F1) | 44.4 | 39.6 | 44.9 | 51.1 | 49.4 |
| 阅读理解 | BoolQ (0-shot) | 75.7 | 65.5 | 66.9 | 79.0 | 73.1 |
| 阅读理解 | DROP (3-shot, F1) | 58.4 | 37.9 | 49.8 | 79.7 | 70.2 |
指令调优模型
| 基准测试 | Llama 3 8B | Llama 2 7B | Llama 2 13B | Llama 3 70B | Llama 2 70B |
|---|---|---|---|---|---|
| MMLU (5-shot) | 68.4 | 34.1 | 47.8 | 82.0 | 52.9 |
| GPQA (0-shot) | 34.2 | 21.7 | 22.3 | 39.5 | 21.0 |
| HumanEval (0-shot) | 62.2 | 7.9 | 14.0 | 81.7 | 25.6 |
| GSM-8K (8-shot, CoT) | 79.6 | 25.7 | 77.4 | 93.0 | 57.5 |
| MATH (4-shot, CoT) | 30.0 | 3.8 | 6.7 | 50.4 | 11.6 |
责任与安全
我们相信,开放的AI方法能够带来更好、更安全的产品,加速创新,并开拓更大的整体市场。我们致力于负责任的AI开发,并采取了一系列措施来限制滥用和危害,支持开源社区。
基础模型是功能广泛的技术,旨在用于各种不同的应用。它们并非旨在开箱即用地满足所有开发者在所有用例中的安全级别偏好,因为这些偏好本质上会因不同应用而异。
相反,负责任的大语言模型应用部署是通过在应用开发的整个过程中实施一系列安全最佳实践来实现的,从模型预训练、微调,到部署包含保障措施的系统,以根据具体用例和受众量身定制安全需求。
作为Llama 3发布的一部分,我们更新了《负责任使用指南》,以概述开发者为其应用实施模型和系统级安全的步骤和最佳实践。我们还提供了一系列资源,包括Meta Llama Guard 2和Code Shield保障措施。这些工具已被证明能够在保持高度实用性的同时,大幅降低大语言模型系统的残余风险。我们鼓励开发者根据自身需求调整和部署这些保障措施,并提供了参考实现以帮助您入门。
Llama 3-Instruct
正如《负责任使用指南》中所述,模型实用性和模型对齐性之间可能不可避免地存在一些权衡。开发者应根据其具体用例和受众,谨慎权衡对齐性和实用性的好处。开发者在使用Llama模型时应注意残余风险,并根据需要利用额外的安全工具,以达到其用例所需的安全标准。
安全性:对于我们的指令调优模型,我们进行了广泛的红队测试、对抗性评估,并实施了安全缓解技术以降低残余风险。与任何大语言模型一样,残余风险可能仍然存在,我们建议开发者在其用例的背景下评估这些风险。同时,我们正在与社区合作,使AI安全基准标准更加透明、严格和可解释。
拒绝回复:除了残余风险,我们非常重视模型对良性提示的拒绝回复问题。过度拒绝不仅会影响用户体验,在某些情况下甚至可能有害。我们听取了开发者社区的反馈,并改进了微调过程,以确保Llama 3比Llama 2更不可能错误地拒绝回答提示。我们建立了内部基准测试并开发了缓解措施,以限制错误拒绝,使Llama 3成为我们迄今为止最实用的模型。
负责任的发布
除了上述负责任使用的考虑因素外,我们遵循了严格的流程,在做出发布决定之前,采取了额外的措施来防范滥用和重大风险。
滥用:如果您访问或使用Llama 3,即表示您同意《可接受使用政策》。该政策的最新版本可在此处查看。
重大风险
- CBRNE(化学、生物、放射、核和高当量爆炸物):我们对模型在这一领域的安全性进行了双重评估:在模型训练期间进行迭代测试,以评估与CBRNE威胁和其他对抗性风险相关的回复安全性;邀请外部CBRNE专家进行提升测试,评估模型准确提供专家知识并减少潜在CBRNE滥用障碍的能力,参考不使用模型时通过网络搜索所能达到的效果。
- 网络安全:我们使用Meta的网络安全评估套件CyberSecEval对Llama 3进行了评估,测量了Llama 3作为编码助手时建议不安全代码的倾向,以及Llama 3响应进行网络攻击请求的倾向,其中攻击由行业标准的MITRE ATT&CK网络攻击本体定义。在我们的不安全编码和网络攻击实用性测试中,Llama 3的表现与具有同等编码能力的模型处于相同范围或更安全。
- 儿童安全:我们使用专家团队进行了儿童安全风险评估,以评估模型产生可能导致儿童安全风险输出的能力,并通过微调提供必要和适当的风险缓解建议。我们利用这些专家红队测试扩展了我们在Llama 3模型开发过程中评估基准的覆盖范围。对于Llama 3,我们使用基于目标的方法进行了新的深入测试,以评估模型在多个攻击向量下的风险。我们还与内容专家合作进行红队测试,评估潜在违规内容,同时考虑特定市场的细微差别或经验。
社区
生成式AI安全需要专业知识和工具,我们相信开放社区的力量能够加速其发展。我们是多个开放联盟的积极成员,包括AI联盟、AI合作组织和MLCommons,积极为安全标准化和透明度做出贡献。我们鼓励社区采用MLCommons概念验证评估等分类法,以促进安全和内容评估的协作和透明度。我们的Purple Llama工具已开源供社区使用,并广泛分发到包括云服务提供商在内的生态系统合作伙伴。我们鼓励社区为我们的GitHub仓库做出贡献。
最后,我们建立了一系列资源,包括输出报告机制和漏洞赏金计划,以在社区的帮助下不断改进Llama技术。
伦理考量与局限性
Llama 3的核心价值观是开放性、包容性和实用性。它旨在服务于所有人,并适用于广泛的用例。因此,它设计为对来自不同背景、经验和观点的人都具有可访问性。Llama 3以用户的实际情况和需求为出发点,不插入不必要的判断或规范性内容,同时认识到即使在某些情况下可能看起来有问题的内容,在其他情况下也可能有其价值。它尊重所有用户的尊严和自主权,特别是在推动创新和进步的自由思想和表达价值观方面。
但Llama 3是一项新技术,与任何新技术一样,其使用存在一定风险。到目前为止进行的测试均使用英语,且无法涵盖所有场景。因此,与所有大语言模型一样,Llama 3的潜在输出无法提前预测,在某些情况下,模型可能会对用户提示产生不准确、有偏见或其他令人反感的回复。因此,在部署Llama 3模型的任何应用之前,开发者应针对其特定应用对模型进行安全测试和调整。正如《负责任使用指南》中所述,我们建议将Purple Llama解决方案纳入您的工作流程,特别是Llama Guard,它提供了一个基础模型,用于过滤输入和输出提示,在模型级安全的基础上增加系统级安全。
请参阅《负责任使用指南》。
📄 许可证
自定义商业许可证可在此处获取。
引用说明
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
贡献者
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; B