🚀 Qwen2.5-Omni-7B-GPTQ-Int4
Qwen2.5-Omni-7B-GPTQ-Int4 是一个端到端的多模态模型,能够感知文本、图像、音频和视频等多种模态信息,并以流式方式生成文本和自然语音响应,有效提升了在不同硬件配置下的运行效率。
🚀 快速开始
本模型卡介绍了一系列旨在提升 Qwen2.5-Omni-7B 在 GPU 内存受限设备上可操作性的增强功能。关键优化点如下:
- 使用 GPTQ 对 Thinker 的权重进行 4 位量化,有效减少 GPU VRAM 的使用。
- 增强推理管道,使每个模块按需加载模型权重,并在推理完成后将其卸载到 CPU 内存,防止 VRAM 峰值使用过高。
- 将 token2wav 模块转换为支持流式推理,避免预先分配过多的 GPU 内存。
- 将 ODE 求解器从二阶(RK4)方法调整为一阶(Euler)方法,进一步降低计算开销。
这些改进旨在确保 Qwen2.5-Omni 在各种硬件配置下,尤其是 GPU 内存较低的设备(如 RTX3080、4080、5070 等)上高效运行。
以下是使用 gptqmodel 调用 Qwen2.5-Omni-7B-GPTQ-Int4 的简单示例:
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
pip install accelerate
pip install gptqmodel==2.0.0
pip install numpy==2.0.0
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni/low-VRAM-mode/
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_gptq.py
我们提供了一个工具包,可帮助你更方便地处理各种类型的音频和视觉输入,就像使用 API 一样。它支持 base64、URL 以及交错的音频、图像和视频。你可以使用以下命令安装该工具包,并确保你的系统已安装 ffmpeg:
pip install qwen-omni-utils[decord] -U
如果你不使用 Linux 系统,可能无法从 PyPI 安装 decord。在这种情况下,你可以使用 pip install qwen-omni-utils -U,它将回退到使用 torchvision 进行视频处理。不过,你仍然可以从源代码安装 decord,以便在加载视频时使用 decord。
性能和 GPU 内存要求
以下两个表格展示了 Qwen2.5-Omni-7B-GPTQ-Int4 和 Qwen2.5-Omni-7B 在特定评估基准上的性能比较和 GPU 内存消耗情况。数据表明,GPTQ-Int4 模型在保持相近性能的同时,将 GPU 内存需求降低了 50% 以上,使更多设备能够运行和体验高性能的 Qwen2.5-Omni-7B 模型。值得注意的是,由于量化技术和 CPU 卸载机制,GPTQ-Int4 变体的推理速度比原生 Qwen2.5-Omni-7B 模型略慢。
| 评估集 |
任务 |
指标 |
Qwen2.5-Omni-7B |
Qwen2.5-Omni-7B-GPTQ-Int4 |
| LibriSpeech test-other |
自动语音识别(ASR) |
词错误率(WER) ⬇️ |
3.4 |
3.71 |
| WenetSpeech test-net |
自动语音识别(ASR) |
词错误率(WER) ⬇️ |
5.9 |
6.62 |
| Seed-TTS test-hard |
文本转语音(TTS,说话人:Chelsie) |
词错误率(WER) ⬇️ |
8.7 |
10.3 |
| MMLU-Pro |
文本到文本 |
准确率 ⬆️ |
47.0 |
43.76 |
| OmniBench |
语音到文本 |
准确率 ⬆️ |
56.13 |
53.59 |
| VideoMME |
多模态到文本 |
准确率 ⬆️ |
72.4 |
68.0 |
| 模型 |
精度 |
15 秒视频 |
30 秒视频 |
60 秒视频 |
| Qwen-Omni-7B |
FP32 |
93.56 GB |
不推荐 |
不推荐 |
| Qwen-Omni-7B |
BF16 |
31.11 GB |
41.85 GB |
60.19 GB |
| Qwen-Omni-7B |
GPTQ-Int4 |
11.64 GB |
17.43 GB |
29.51 GB |
✨ 主要特性
全模态与新颖架构
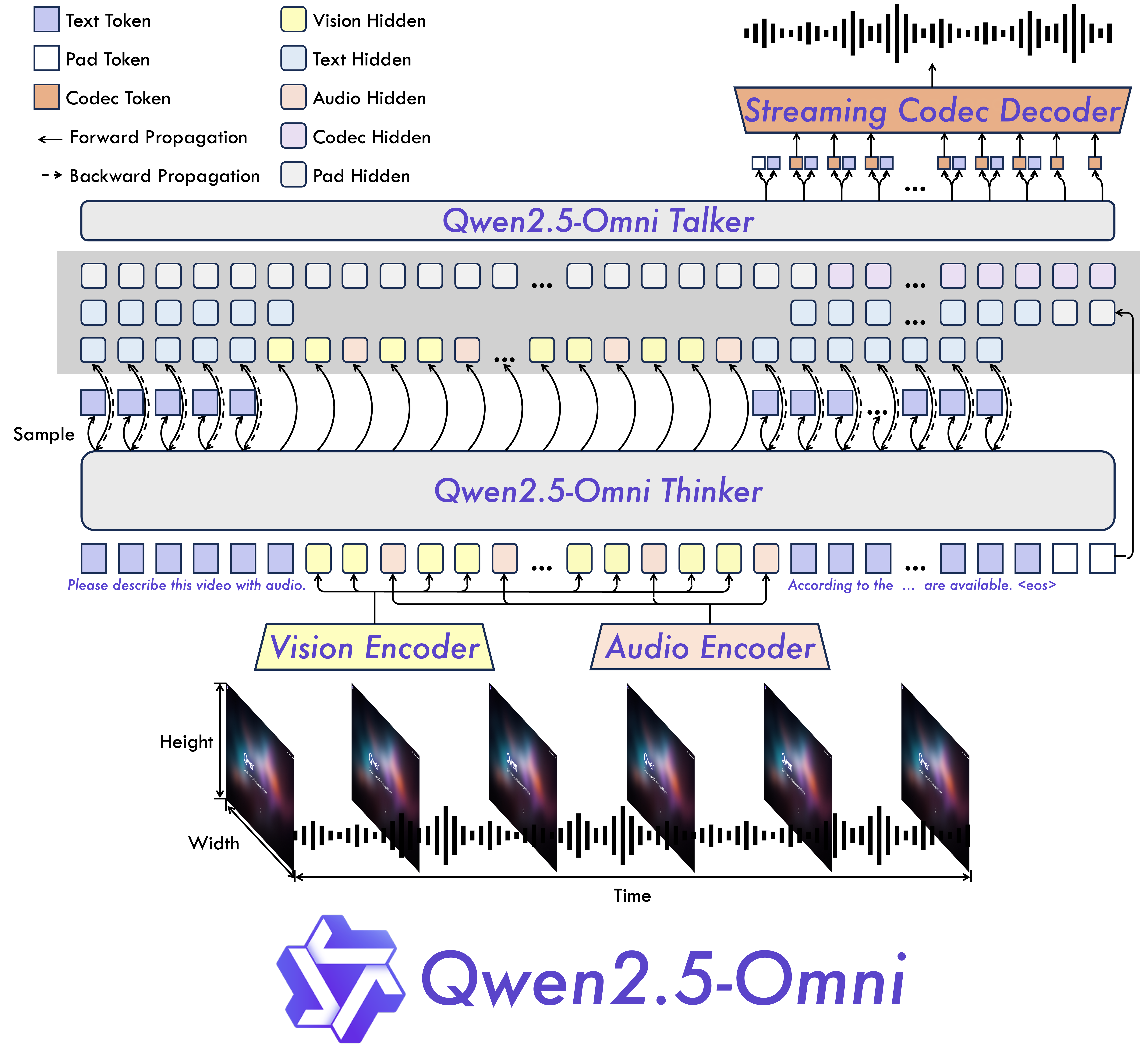
我们提出了 Thinker-Talker 架构,这是一种端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态信息,同时以流式方式同步生成文本和自然语音响应。此外,我们还提出了一种新颖的位置嵌入方法,名为 TMRoPE(时间对齐多模态旋转位置编码),用于将视频输入的时间戳与音频同步。
实时语音和视频聊天
该架构专为全实时交互而设计,支持分块输入和即时输出。
自然且稳健的语音生成
在语音生成方面,该模型超越了许多现有的流式和非流式替代方案,展现出卓越的稳健性和自然度。
跨模态的强大性能
与同等规模的单模态模型相比,Qwen2.5-Omni 在所有模态上均表现出色。在音频能力方面,Qwen2.5-Omni 优于同等规模的 Qwen2-Audio,并且在性能上与 Qwen2.5-VL-7B 相当。
出色的端到端语音指令遵循能力
Qwen2.5-Omni 在端到端语音指令遵循方面的表现与其在文本输入时的效果相当,这在 MMLU 和 GSM8K 等基准测试中得到了验证。
模型架构
📄 许可证
本项目采用 Apache-2.0 许可证。
📚 引用
如果你在研究中发现我们的论文和代码很有用,请考虑给我们点个星 :star: 并引用 :pencil: 哦!
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言