🚀 Qwen2.5-Omni-7B-GPTQ-Int4
Qwen2.5-Omni-7B-GPTQ-Int4は、多様なモダリティ(テキスト、画像、音声、ビデオ)を感知し、同時にテキストと自然な音声応答をストリーミング方式で生成できるエンドツーエンドのマルチモーダルモデルです。
🚀 クイックスタート
このモデルカードでは、GPUメモリが制限されたデバイスでのQwen2.5-Omni-7Bの操作性を向上させるための一連の機能強化について紹介します。主な最適化点は以下の通りです。
- GPTQを使用してThinkerの重みを4ビット量子化し、GPU VRAMの使用量を効果的に削減します。
- 推論パイプラインを強化し、各モジュールのモデル重みを必要に応じてロードし、推論が完了したらCPUメモリにオフロードし、VRAMのピーク使用量が過大にならないようにします。
- token2wavモジュールを変換してストリーミング推論をサポートし、過剰なGPUメモリの事前割り当てを回避します。
- ODEソルバーを2次(RK4)から1次(オイラー法)に調整し、計算オーバーヘッドをさらに削減します。
これらの改善により、特にGPUメモリが少ないハードウェア構成(RTX3080、4080、5070など)でも、Qwen2.5-Omniが効率的に動作することが保証されます。
以下に、gptqmodelを使用してQwen2.5-Omni-7B-GPTQ-Int4を使用する簡単な例を示します。
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
pip install accelerate
pip install gptqmodel==2.0.0
pip install numpy==2.0.0
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni/low-VRAM-mode/
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_gptq.py
様々なタイプのオーディオとビジュアル入力をより便利に扱うためのツールキットを提供しています。これはAPIを使用するような感覚で使え、base64、URL、インターリーブされたオーディオ、画像、ビデオをサポートしています。以下のコマンドを使用してインストールできますが、システムにffmpegがインストールされていることを確認してください。
pip install qwen-omni-utils[decord] -U
Linuxを使用していない場合、PyPIからdecordをインストールできない可能性があります。その場合は、pip install qwen-omni-utils -Uを使用すると、ビデオ処理にtorchvisionを使用するようにフォールバックします。ただし、ソースからdecordをインストールすることで、ビデオロード時にdecordを使用することもできます。
パフォーマンスとGPUメモリ要件
以下の2つの表は、特定の評価ベンチマークにおけるQwen2.5-Omni-7B-GPTQ-Int4とQwen2.5-Omni-7Bのパフォーマンス比較とGPUメモリ消費量を示しています。データから、GPTQ-Int4モデルは同等のパフォーマンスを維持しながら、GPUメモリ要件を50%以上削減し、より広範なデバイスで高性能なQwen2.5-Omni-7Bモデルを実行して体験できるようになります。なお、GPTQ-Int4バリアントは、量子化技術とCPUオフロードメカニズムのため、ネイティブのQwen2.5-Omni-7Bモデルと比較して推論速度が若干遅くなります。
| 評価セット |
タスク |
メトリクス |
Qwen2.5-Omni-7B |
Qwen2.5-Omni-7B-GPTQ-Int4 |
| LibriSpeech test-other |
ASR |
WER ⬇️ |
3.4 |
3.71 |
| WenetSpeech test-net |
ASR |
WER ⬇️ |
5.9 |
6.62 |
| Seed-TTS test-hard |
TTS (Speaker: Chelsie) |
WER ⬇️ |
8.7 |
10.3 |
| MMLU-Pro |
テキスト -> テキスト |
正解率 ⬆️ |
47.0 |
43.76 |
| OmniBench |
音声 -> テキスト |
正解率 ⬆️ |
56.13 |
53.59 |
| VideoMME |
マルチモーダル -> テキスト |
正解率 ⬆️ |
72.4 |
68.0 |
| モデル |
精度 |
15秒ビデオ |
30秒ビデオ |
60秒ビデオ |
| Qwen-Omni-7B |
FP32 |
93.56 GB |
推奨しません |
推奨しません |
| Qwen-Omni-7B |
BF16 |
31.11 GB |
41.85 GB |
60.19 GB |
| Qwen-Omni-7B |
GPTQ-Int4 |
11.64 GB |
17.43 GB |
29.51 GB |
✨ 主な機能
概要
紹介
Qwen2.5-Omniは、テキスト、画像、音声、ビデオなどの多様なモダリティを感知し、同時にテキストと自然な音声応答をストリーミング方式で生成するエンドツーエンドのマルチモーダルモデルです。
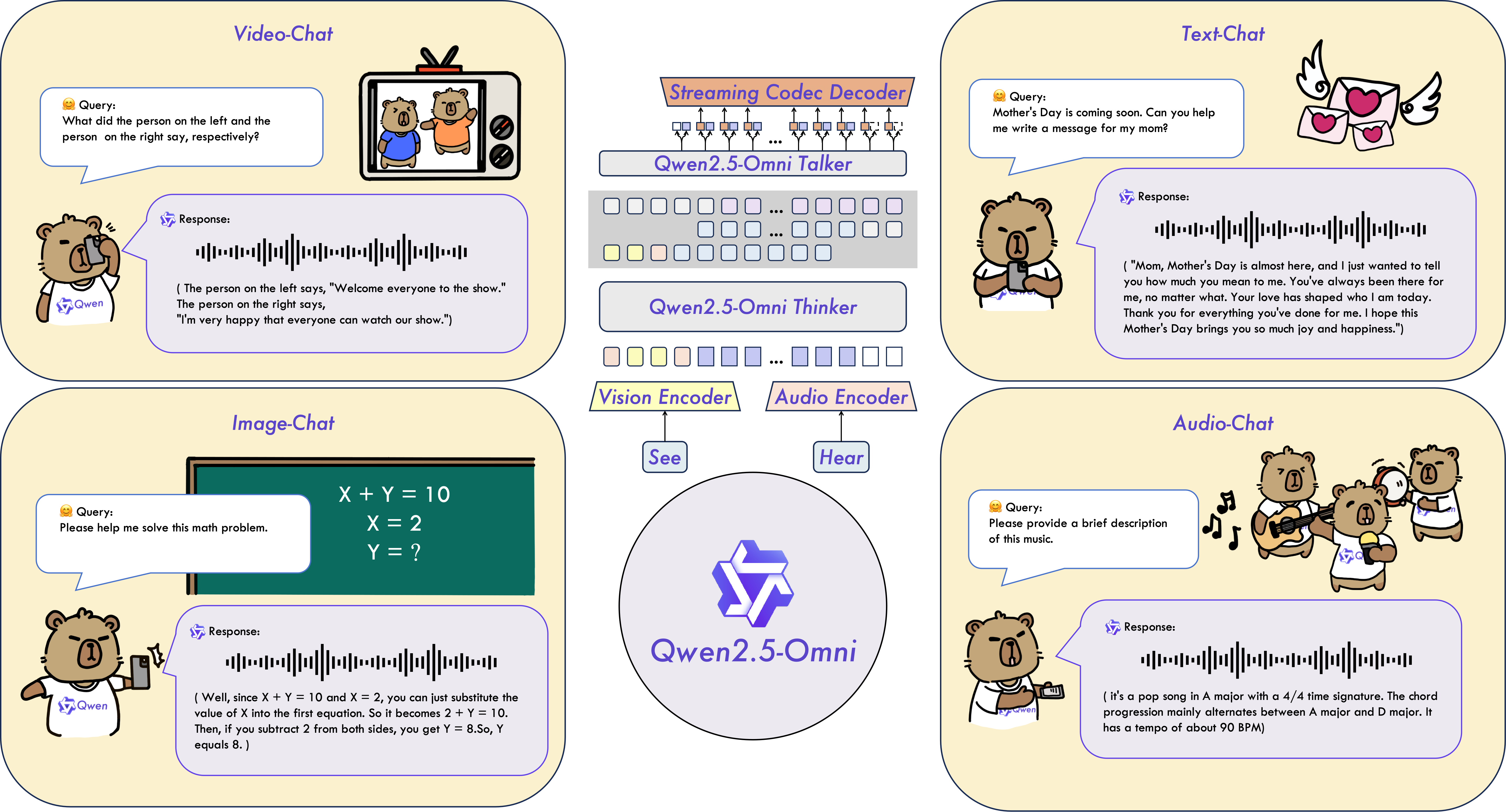
主要な特徴
- オムニモーダルで革新的なアーキテクチャ:Thinker-Talkerアーキテクチャを提案しました。これは、テキスト、画像、音声、ビデオなどの多様なモダリティを感知し、同時にテキストと自然な音声応答をストリーミング方式で生成するエンドツーエンドのマルチモーダルモデルです。また、新しい位置埋め込みであるTMRoPE(Time-aligned Multimodal RoPE)を提案し、ビデオ入力のタイムスタンプを音声と同期させます。
- リアルタイムの音声とビデオチャット:完全なリアルタイムインタラクションを目的としたアーキテクチャで、チャンク入力と即時出力をサポートします。
- 自然で堅牢な音声生成:多くの既存のストリーミングおよび非ストリーミングの代替手段を上回り、音声生成において卓越した堅牢性と自然性を示します。
- 全モダリティにわたる高いパフォーマンス:同規模の単一モダリティモデルと比較して、すべてのモダリティで卓越したパフォーマンスを発揮します。Qwen2.5-Omniは、同規模のQwen2-Audioよりも音声能力が優れており、Qwen2.5-VL-7Bと同等のパフォーマンスを達成します。
- 優れたエンドツーエンドの音声命令追従:Qwen2.5-Omniは、エンドツーエンドの音声命令追従において、テキスト入力と同等の有効性を示し、MMLUやGSM8Kなどのベンチマークで証明されています。
モデルアーキテクチャ
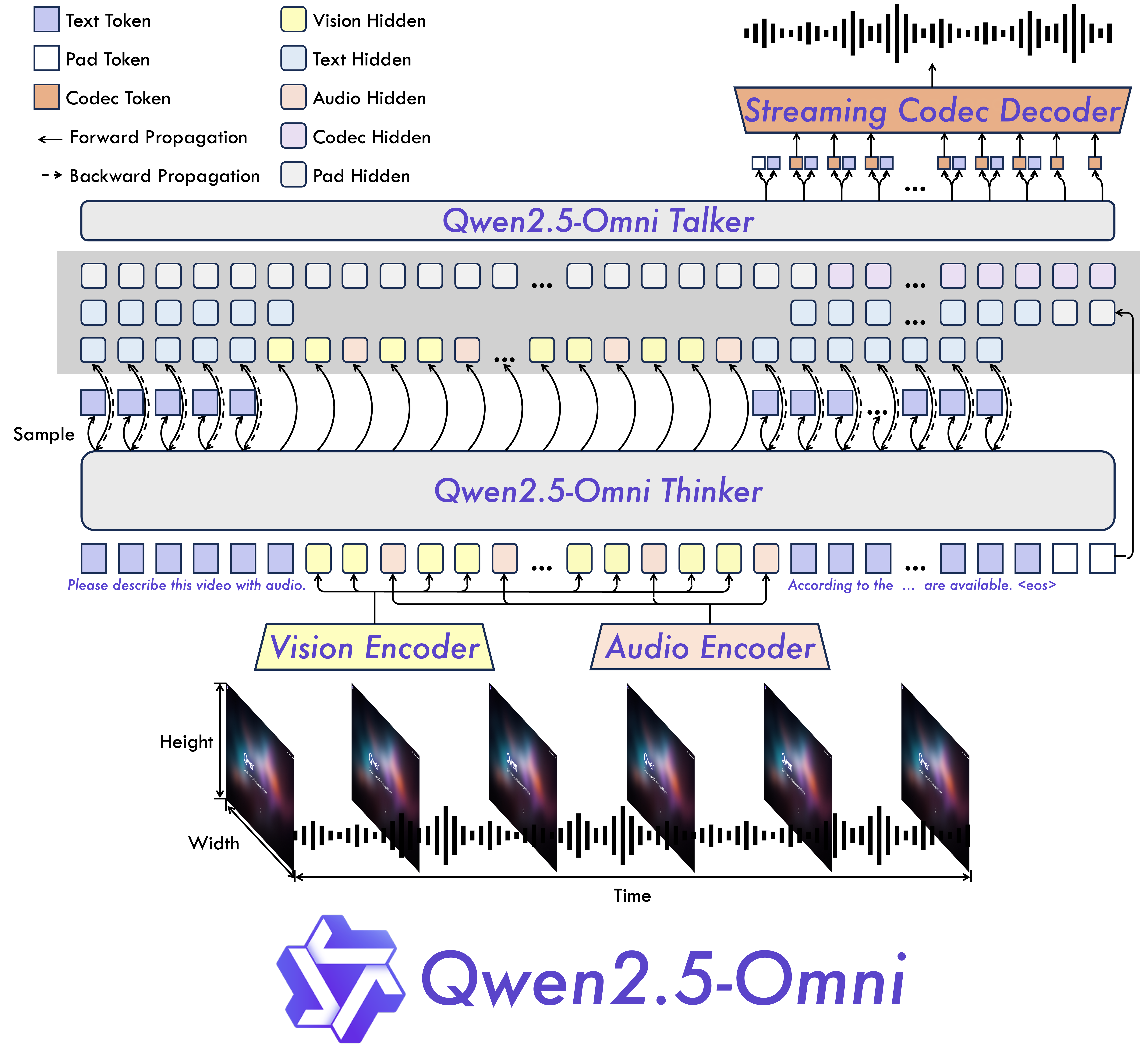
📄 ライセンス
このモデルはApache 2.0ライセンスの下で提供されています。
📚 引用
もしあなたの研究で当社の論文やコードが役立った場合は、スター⭐を付けて引用✍️していただけると幸いです。
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応