%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 小夜曲XL εpsilon
小夜曲XL εpsilon是小夜曲XL系列的第五次重大迭代,使用520万张图像的数据集,通过LyCORIS进行微调,在消费级硬件上完成训练,并且完全开源。该模型在文本到图像转换方面表现出色,能生成高质量且风格多样的图像。
🚀 快速开始
Kohaku XL Epsilon是小夜曲XL系列的第五次重大迭代版本,它使用了包含520万张图像的数据集,并采用LyCORIS进行微调。该模型在消费级硬件上完成训练,并且完全开源。
模型效果展示
通过以下图像查看器,你可以直观地看到Kohaku XL Epsilon生成的部分图像效果:












加入我们
欢迎加入我们的社区交流:Discord
✨ 主要特性
- 数据集丰富:使用了包含520万张图像的数据集进行训练,能生成更丰富多样的图像。
- 微调技术:采用LyCORIS进行微调,提升了模型的性能和稳定性。
- 开源免费:模型完全开源,方便开发者进行二次开发和研究。
- 风格多样:掌握了更多艺术家的风格,并且在组合多个艺术家标签时稳定性更高。
💻 使用示例
基础用法
<1girl/1boy/1other/...>,
<character>, <series>, <artists>,
<general tags>,
<quality tags>, <year tags>, <meta tags>, <rating tags>
高级用法
Kohaku XL Epsilon掌握了比Delta更多艺术家的风格,并且在组合多个艺术家标签时稳定性更高。建议用户创建自己的风格提示。以下是一些不错的风格提示示例:
ask \(askzy\), torino aqua, migolu, (jiu ye sang:1.1), (rumoon:0.9), (mizumi zumi:1.1)
ciloranko, maccha \(mochancc\), lobelia \(saclia\), migolu,
ask \(askzy\), wanke, (jiu ye sang:1.1), (rumoon:0.9), (mizumi zumi:1.1)
shiro9jira, ciloranko, ask \(askzy\), (tianliang duohe fangdongye:0.8)
(azuuru:1.1), (torino aqua:1.2), (azuuru:1.1), kedama milk,
fuzichoco, ask \(askzy\), chen bin, atdan, hito, mignon
ask \(askzy\), torino aqua, migolu
标签使用说明
- 通用标签:所有在danbooru上受欢迎度至少为1000的标签都应该可以正常使用;受欢迎度至少为100的标签在高权重强调下可能会起作用。
- 去除下划线:记得去除标签中的所有下划线(短标签中的下划线可能是表情符号标签的一部分,无需去除)。
- 特殊标签处理:当标签中有括号且使用sd-webui时,记得使用
xxx\(yyy\)格式。
特殊标签
- 质量标签:masterpiece(杰作), best quality(最佳质量), great quality(高质量), good quality(良好质量), normal quality(普通质量), low quality(低质量), worst quality(最差质量)
- 评级标签:safe(安全), sensitive(敏感), nsfw(不适宜公开), explicit(明确限制)
- 日期标签:newest(最新), recent(近期), mid(中期), early(早期), old(旧的)
分辨率说明
该模型针对ARB 1024x1024的分辨率进行训练,最小分辨率为256,最大分辨率为4096。这意味着你可以使用标准的SDXL分辨率。不过,建议选择略高于1024x1024的分辨率,并应用hires-fix以获得更好的效果。更多信息请查看提供的示例图像。
📚 详细文档
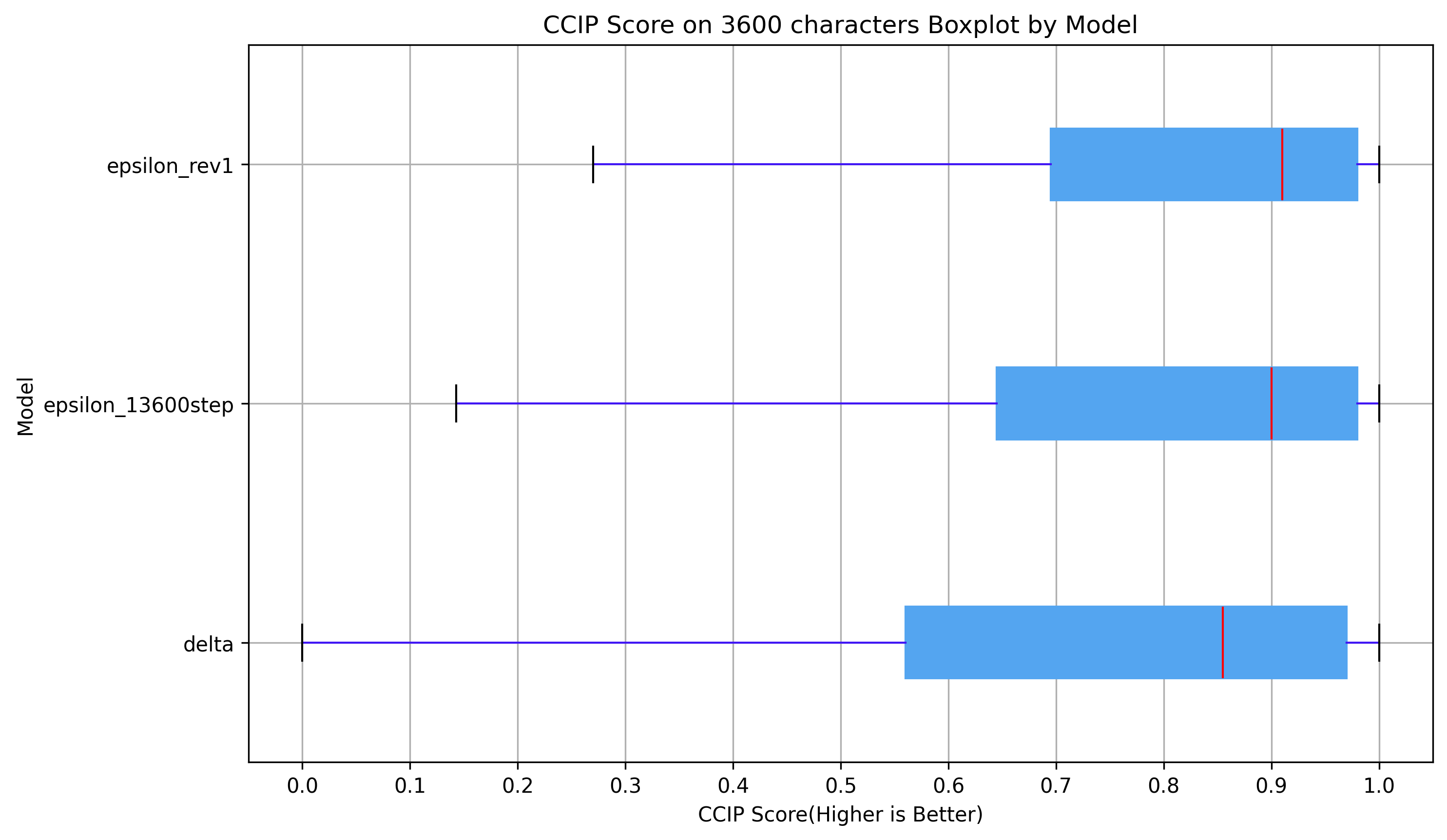
模型基准测试
在3600字符的CCIP评分中(0~1,分数越高越好),Kohaku XL Epsilon明显优于Kohaku XL Delta。
模型诞生过程
为什么是Epsilon
和Delta一样,这是对新数据集的一次测试,并且效果良好。与Delta相比,其输出结果也有很大不同。
数据集
该模型的训练数据集来自HakuBooru,从danbooru2023数据集中挑选了520万张图像。具体挑选过程如下:从ID 0到200万中挑选了100万个帖子,从ID 200万到499.9999万中挑选了200万个帖子,以及挑选了ID 500万之后的所有帖子,总计535万个帖子。经过过滤删除的帖子、黄金账户帖子和没有图像(可能是GIF或MP4)的帖子后,最终数据集包含520万张图像。挑选过程基本是随机的,但使用了固定种子以确保可重复性。
进一步处理
- 标签洗牌:在每个步骤中打乱通用标签的顺序。
- 标签丢弃:在每个步骤中随机丢弃15%的通用标签。
训练
Kohaku XL Epsilon的训练借助了LyCORIS项目和kohya-ss/sd-scripts的训练器。
算法:LoKr 该模型使用LoKr算法进行训练,触发全矩阵,不同模块的因子为2~8。目的是证明LoRA/LyCORIS在训练基础模型中的适用性。原始LoKr文件大小小于800MB,并且TE未冻结。原始LoKr文件也以“delta-lokr”版本提供。详细设置请参考Kohaku XL Delta的LyCORIS配置文件。
其他训练细节
| 属性 | 详情 |
|---|---|
| 硬件 | 四块RTX 3090显卡 |
| 训练图像数量 | 5,210,319 |
| 批次大小 | 4 |
| 梯度累积步数 | 16 |
| 等效批次大小 | 256 |
| 总训练轮数 | 1 |
| 总步数 | 20354 |
| 优化器 | Lion8bit |
| 学习率 | UNet为2e-5 / TE为5e-6 |
| 学习率调度器 | 常数(带热身) |
| 热身步数 | 1000 |
| 权重衰减 | 0.1 |
| 贝塔值 | 0.9, 0.95 |
| 最小SNR伽马值 | 5 |
| 噪声偏移 | 0.0357 |
| 分辨率 | 1024x1024 |
| 最小桶分辨率 | 256 |
| 最大桶分辨率 | 4096 |
| 混合精度 | FP16 |
警告:bitsandbytes的0.36.0~0.41.0版本在8位优化器中存在严重漏洞,可能会影响训练,因此必须进行更新。
训练成本 使用四块RTX 3090显卡进行DDP训练,在520万张图像的数据集上完成1轮训练大约需要12到13天。等效批次大小为256时,每个步骤大约需要49到50秒完成。
为什么发布13600步的中间检查点
训练进度在13600步到15300步之间崩溃,并且kohya-ss训练器之前没有实现恢复和跳过步骤的功能。尽管Kohya和我已经弄清楚了如何正确处理并进行了一些合理性检查,但我仍然不能完全确保最终结果的正确性。因此,我发布了最终的中间检查点,以便任何想要复现训练的人有机会找出最终结果的问题。
未来计划
目前我专注于制作新的数据集(目标是1000万到1500万张图像),并等待SD3的发布,看看是否值得尝试。我也可能会对Epsilon进行一些小的微调,并以rev2/3/4等版本发布,但目前数据集仍然是我的主要关注点。
🔧 技术细节
算法原理
模型使用LoKr算法进行训练,触发全矩阵,不同模块的因子为2~8,目的是证明LoRA/LyCORIS在训练基础模型中的适用性。
训练优化
在训练过程中,采用了梯度累积、学习率调度等优化策略,以提高模型的训练效果和稳定性。
数据处理
对数据集进行了标签洗牌和标签丢弃等处理,以增加数据的多样性和模型的泛化能力。
📄 许可证
本模型遵循“Fair-AI public license 1.0-SD”许可协议,更多信息请参考原始许可证:https://freedevproject.org/faipl-1.0-sd/
参考与资源
参考文献
[1] SHIH-YING YEH, Yu-Guan Hsieh, Zhidong Gao, Bernard B W Yang, Giyeong Oh, & Yanmin Gong (2024). Navigating Text-To-Image Customization: From LyCORIS Fine-Tuning to Model Evaluation. In The Twelfth International Conference on Learning Representations. [2] HakuBooru - text-image dataset maker for booru style image platform. https://github.com/KohakuBlueleaf/HakuBooru [3] Danbooru2023: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. https://huggingface.co/datasets/nyanko7/danbooru2023 [4] kohya-ss/sd-scripts. https://github.com/kohya-ss/sd-scripts [5] LyCORIS - Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion. https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo-Details.md#lokr [6] TimDettmers/bitsandbytes - issue 659/152/227/262 - Wrong indented lines cause bugs for a long time. https://github.com/TimDettmers/bitsandbytes/issues/659
相关资源
- Kohaku XL beta: https://civitai.com/models/162577/kohaku-xl-beta
- Kohaku XL gamma: https://civitai.com/models/270291/kohaku-xl-gamma
- Kohaku XL delta: https://civitai.com/models/332076/kohaku-xl-delta
⚠️ 重要提示 bitsandbytes的0.36.0~0.41.0版本在8位优化器中存在严重漏洞,可能会影响训练,因此必须进行更新。
💡 使用建议 建议选择略高于1024x1024的分辨率,并应用hires-fix以获得更好的图像效果。同时,用户可以根据自己的需求创建独特的风格提示,以发挥模型的最大潜力。
AI艺术应该展现出AI的特色,而不是模仿人类。
(有趣的事实:这句口号来自我的个人主页,很多人喜欢并将其放在他们的模型页面上。)