🚀 こはくXL εpsilon
コンシューマーレベルのハードウェアで自宅でテキストから画像生成モデルを微調整する最高の例
私たちに参加しましょう: https://discord.gg/tPBsKDyRR5
🚀 クイックスタート
こはくXL εpsilonは、こはくXLシリーズの5番目の主要なバージョンで、520万枚の画像データセットを使用し、LyCORISで微調整され、コンシューマーレベルのハードウェアで学習され、完全にオープンソース化されています。
✨ 主な機能
ベンチマーク
3600文字でのCCIPスコア (0~1、高いほど良い)
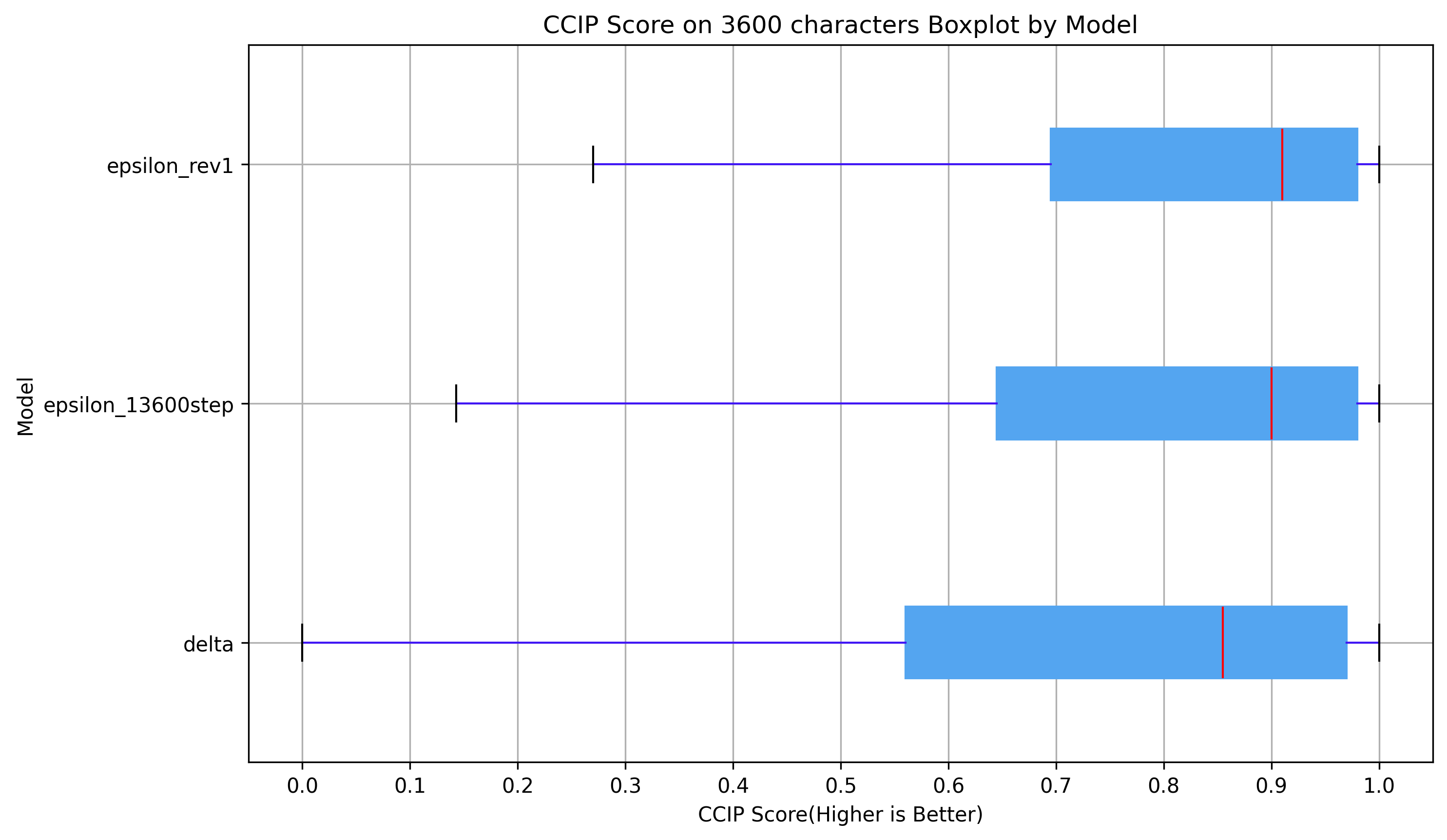 明らかに、こはくXL εpsilonはこはくXL Deltaよりもはるかに優れています。
明らかに、こはくXL εpsilonはこはくXL Deltaよりもはるかに優れています。
使い方
<1girl/1boy/1other/...>,
<character>, <series>, <artists>,
<general tags>,
<quality tags>, <year tags>, <meta tags>, <rating tags>
こはくXL εpsilonは、Deltaよりも多くのアーティストのスタイルを習得しています。また、複数のアーティストタグを組み合わせたときの安定性も向上しています。ユーザーは独自のスタイルプロンプトを作成することをお勧めします。
いくつかの良いスタイルプロンプト
ask \(askzy\), torino aqua, migolu, (jiu ye sang:1.1), (rumoon:0.9), (mizumi zumi:1.1)
ciloranko, maccha \(mochancc\), lobelia \(saclia\), migolu,
ask \(askzy\), wanke, (jiu ye sang:1.1), (rumoon:0.9), (mizumi zumi:1.1)
shiro9jira, ciloranko, ask \(askzy\), (tianliang duohe fangdongye:0.8)
(azuuru:1.1), (torino aqua:1.2), (azuuru:1.1), kedama milk,
fuzichoco, ask \(askzy\), chen bin, atdan, hito, mignon
ask \(askzy\), torino aqua, migolu
タグ
人気が少なくとも1000のすべてのdanbooruタグは機能するはずです。
人気が少なくとも100のすべてのdanbooruタグは、高い強調で機能する可能性があります。
タグ内のすべてのアンダースコアを削除することを忘れないでください。(短いタグ内のアンダースコアは削除されません。これらは非常に可能性が高いエモジータグの一部です。)
タグに括弧があり、sd - webuiを使用している場合は、xxx\(yyy\)を使用することを忘れないでください。
特殊タグ
- 品質タグ: masterpiece, best quality, great quality, good quality, normal quality, low quality, worst quality
- レーティングタグ: safe, sensitive, nsfw, explicit
- 日付タグ: newest, recent, mid, early, old
品質タグ
品質タグは、各レーティングカテゴリ内のお気に入りカウント (fav_count) のパーセンタイルランキングに基づいて割り当てられ、nsfwコンテンツに対するバイアスを避けるために (Animagine XL v3はこの問題に直面しています)、高から低の順に 90パーセンタイル、75パーセンタイル、60パーセンタイル、45パーセンタイル、30パーセンタイル、および10パーセンタイル となっています。これにより、6つのしきい値で区切られた7つの異なる品質レベルが作成されます。
Danbooru内の画像の平均品質が予想よりも高いことがわかったため、しきい値を下げました。
レーティングタグ
- 一般: safe
- センシティブ: sensitive
- 問題あり: nsfw
- 露骨: nsfw, explicit
注: 学習中は、「explicit」とタグ付けされたコンテンツも「nsfw」と見なされ、包括的な理解を確保します。
日付タグ
日付タグは、画像のアップロード日付に基づいています。メタデータには実際の作成日が含まれていないためです。
期間は以下のように分類されます:
- 2005~2010: old
- 2011~2014: early
- 2015~2017: mid
- 2018~2020: recent
- 2021~2024: newest
解像度
このモデルは、最低解像度256、最高解像度4096のARB 1024x1024の解像度で学習されています。これは、標準のSDXL解像度を使用できることを意味します。ただし、1024x1024よりも少し高い解像度を選択することをお勧めします。より良い結果を得るために、hires - fixを適用することもおすすめです。
詳細については、提供されているサンプル画像を確認してください。
🔧 技術詳細
なぜεpsilon?
Deltaと同じく、新しいデータセットのテストであり、良好な結果が得られました。
出力も (Deltaと比較して) 非常に異なっています。
データセット
このモデルの学習に使用されたデータセットは、HakuBooru から取得され、danbooru2023 データセットから選択された520万枚の画像で構成されています。[2][3]
選択プロセスでは、ID 0から2,000,000までの100万件の投稿、ID 2,000,000から4,999,999までの200万件の投稿、および ID 5,000,000以降のすべての投稿 が選択され、合計535万件の投稿となりました。削除された投稿、ゴールドアカウントの投稿、および画像のない投稿 (GIFまたはMP4の可能性があります) をフィルタリングした後、最終的なデータセットは520万枚の画像で構成されました。
選択は基本的にランダムでしたが、再現性を確保するために固定シードが使用されました。
さらなる処理
- タグのシャッフル: 各ステップで一般タグの順序がシャッフルされました。
- タグのドロップアウト: 各ステップでランダムに 15% の一般タグが削除されました。
学習
こはくXL εpsilonの学習は、LyCORIS プロジェクトと kohya - ss/sd - scripts のトレーナーによって行われました。[1][4]
アルゴリズム: LoKr[5]
モデルは、完全行列がトリガーされ、異なるモジュールに対して2~8の係数を持つLoKrアルゴリズムを使用して学習されました。目的は、LoRA/LyCORISがベースモデルの学習に適用可能であることを示すことでした。
元のLoKrファイルサイズは800MB未満で、TEは凍結されていません。元のLoKrファイルも「delta - lokr」バージョンとして提供されます。
詳細な設定については、こはくXL DeltaのLyCORIS設定ファイルを参照してください。
その他の学習詳細
- ハードウェア: Quad RTX 3090s
- 学習画像数: 5,210,319
- バッチサイズ: 4
- 勾配累積ステップ: 16
- 相当バッチサイズ: 256
- 総エポック数: 1
- 総ステップ数: 20354
- オプティマイザー: Lion8bit
- 学習率: UNetには2e - 5 / TEには5e - 6
- 学習率スケジューラー: 一定 (ウォームアップ付き)
- ウォームアップステップ: 1000
- 重み減衰: 0.1
- ベータ: 0.9, 0.95
- 最小SNRガンマ: 5
- ノイズオフセット: 0.0357
- 解像度: 1024x1024
- 最小バケット解像度: 256
- 最大バケット解像度: 4096
- 混合精度: FP16
警告: bitsandbytesのバージョン0.36.0~0.41.0には、8ビットオプティマイザーに重大な バグ があり、学習に影響を与える可能性があるため、更新することが不可欠です。[6]
学習コスト
4台のRTX 3090を使用したDDPを利用して、520万枚の画像データセット全体で1エポックを完了するのに約12 ~ 13日かかりました。相当バッチサイズ256の各ステップには、約49 ~ 50秒かかりました。
なぜ13600ステップの中間ckptを公開するのか
学習の進行が13600ステップ~15300ステップの間でクラッシュしました。そして、kohya - ssトレーナーは以前は再開+ステップスキップを実装していませんでした。
こはくと私は正しく行う方法を見つけ、いくつかの健全性チェックを行いましたが、最終結果が正しいことを完全に保証することはできません。そのため、誰かが学習を再現したい場合に、最終結果の問題を見つける機会があるように、最終的な中間ckptを公開しています。
これからの予定
私は現在、新しいデータセット (目標は1000万~1500万枚の画像) の作成に注力しており、SD3が登場したら試す価値があるかどうかを見ています。
また、εpsilonに小規模な微調整を行い、rev2/3/4...として公開するかもしれませんが、現在はデータセットが主な焦点です。
特別な感謝
AngelBottomless & Nyanko7: danbooru2023データセット[3]
kohya - ss: トレーナー[4]
AIアートはAIらしく、人間らしくないべきです。
(面白い事実: このスローガンは私の個人ホームページから来ています。多くの人がこのスローガンを気に入り、自分たちのモデルページに載せています。)
📚 ドキュメント
参考文献
[1] SHIH - YING YEH, Yu - Guan Hsieh, Zhidong Gao, Bernard B W Yang, Giyeong Oh, & Yanmin Gong (2024). Navigating Text - To - Image Customization: From LyCORIS Fine - Tuning to Model Evaluation. In The Twelfth International Conference on Learning Representations.
[2] HakuBooru - booruスタイルの画像プラットフォーム用のテキスト - 画像データセットメーカー。https://github.com/KohakuBlueleaf/HakuBooru
[3] Danbooru2023: A Large - Scale Crowdsourced and Tagged Anime Illustration Dataset. https://huggingface.co/datasets/nyanko7/danbooru2023
[4] kohya - ss/sd - scripts. https://github.com/kohya-ss/sd-scripts
[5] LyCORIS - Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion. https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo - Details.md#lokr
[6] TimDettmers/bitsandbytes - issue 659/152/227/262 - Wrong indented lines cause bugs for a long time. https://github.com/TimDettmers/bitsandbytes/issues/659
リソース
- こはくXLベータ。https://civitai.com/models/162577/kohaku-xl-beta
- こはくXLガンマ。https://civitai.com/models/270291/kohaku-xl-gamma
- こはくXLデルタ。https://civitai.com/models/332076/kohaku-xl-delta
📄 ライセンス
このモデルは「Fair - AI public license 1.0 - SD」の下でライセンスされています。詳細については、元のライセンスを参照してください: https://freedevproject.org/faipl-1.0-sd/
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応