%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Openchat 3.5 0106 - GGUF
Openchat 3.5 0106 - GGUF 是一个文本生成模型,以 Mistral 为基础,在文本生成任务中表现出色。本项目提供了该模型的 GGUF 量化格式文件,方便不同设备和场景下的使用。
🚀 快速开始
模型信息
| 属性 | 详情 |
|---|---|
| 模型创建者 | OpenChat |
| 模型名称 | Openchat 3.5 0106 |
| 模型类型 | mistral |
| 管道标签 | text-generation |
| 基础模型 | openchat/openchat-3.5-0106 |
| 量化者 | TheBloke |
| 许可证 | apache-2.0 |
模型展示

TheBloke's LLM work is generously supported by a grant from andreessen horowitz (a16z)
✨ 主要特性
模型格式
本仓库包含 OpenChat 的 Openchat 3.5 0106 的 GGUF 格式模型文件。这些文件使用了由 Massed Compute 提供的硬件进行量化。
GGUF 格式优势
GGUF 是 llama.cpp 团队在 2023 年 8 月 21 日引入的一种新格式,它取代了不再被 llama.cpp 支持的 GGML 格式。以下是一些已知支持 GGUF 的客户端和库:
- llama.cpp:GGUF 的源项目,提供 CLI 和服务器选项。
- text-generation-webui:最广泛使用的 Web UI,具有许多功能和强大的扩展,支持 GPU 加速。
- KoboldCpp:功能齐全的 Web UI,支持所有平台和 GPU 架构的 GPU 加速,尤其适合故事创作。
- GPT4All:免费开源的本地运行 GUI,支持 Windows、Linux 和 macOS,具有完整的 GPU 加速。
- LM Studio:适用于 Windows 和 macOS(Silicon)的易于使用且功能强大的本地 GUI,支持 GPU 加速,截至 2023 年 11 月 27 日,Linux 版本处于测试阶段。
- LoLLMS Web UI:一个很棒的 Web UI,具有许多有趣和独特的功能,包括一个完整的模型库,便于选择模型。
- Faraday.dev:一个有吸引力且易于使用的基于角色的聊天 GUI,适用于 Windows 和 macOS(Silicon 和 Intel),支持 GPU 加速。
- llama-cpp-python:一个支持 GPU 加速、LangChain 集成和 OpenAI 兼容 API 服务器的 Python 库。
- candle:一个专注于性能的 Rust ML 框架,包括 GPU 支持,易于使用。
- ctransformers:一个支持 GPU 加速、LangChain 集成和 OpenAI 兼容 AI 服务器的 Python 库。请注意,截至 2023 年 11 月 27 日,ctransformers 已经很长时间没有更新,不支持许多最新的模型。
可用仓库
- 用于 GPU 推理的 AWQ 模型
- 用于 GPU 推理的 GPTQ 模型,具有多种量化参数选项
- 用于 CPU+GPU 推理的 2、3、4、5、6 和 8 位 GGUF 模型
- OpenChat 原始未量化的 fp16 格式 PyTorch 模型,用于 GPU 推理和进一步转换
📦 安装指南
下载 GGUF 文件
手动下载注意事项:几乎不需要克隆整个仓库!提供了多种不同的量化格式,大多数用户只需要选择并下载单个文件。
以下客户端/库将自动为你下载模型,并提供可用模型列表供你选择:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
在 text-generation-webui 中下载
在“Download Model”下,输入模型仓库地址:TheBloke/openchat-3.5-0106-GGUF,然后在下方输入要下载的具体文件名,例如:openchat-3.5-0106.Q4_K_M.gguf,最后点击“Download”。
在命令行下载(包括同时下载多个文件)
推荐使用 huggingface-hub Python 库:
pip3 install huggingface-hub
然后可以使用以下命令将任何单个模型文件高速下载到当前目录:
huggingface-cli download TheBloke/openchat-3.5-0106-GGUF openchat-3.5-0106.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
更高级的 huggingface-cli 下载用法(点击查看)
你还可以使用通配符同时下载多个文件:
huggingface-cli download TheBloke/openchat-3.5-0106-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
有关使用 huggingface-cli 下载的更多文档,请参阅:HF -> Hub Python Library -> Download files -> Download from the CLI。
为了在高速连接(1Gbit/s 或更高)上加速下载,请安装 hf_transfer:
pip3 install hf_transfer
并将环境变量 HF_HUB_ENABLE_HF_TRANSFER 设置为 1:
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/openchat-3.5-0106-GGUF openchat-3.5-0106.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
Windows 命令行用户:可以在下载命令前运行 set HF_HUB_ENABLE_HF_TRANSFER=1 来设置环境变量。
💻 使用示例
llama.cpp 命令示例
确保使用的是 d0cee0d 或更高版本的 llama.cpp。
./main -ngl 35 -m openchat-3.5-0106.Q4_K_M.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:"
-ngl 32:将其更改为要卸载到 GPU 的层数。如果没有 GPU 加速,请删除该参数。-c 8192:将其更改为所需的序列长度。对于扩展序列模型(例如 8K、16K、32K),必要的 RoPE 缩放参数会从 GGUF 文件中读取并由 llama.cpp 自动设置。请注意,更长的序列长度需要更多的资源,因此可能需要减小此值。
如果想要进行聊天式对话,请将 -p <PROMPT> 参数替换为 -i -ins。
有关其他参数及其用法,请参考 llama.cpp 文档。
在 text-generation-webui 中运行
更多说明可以在 text-generation-webui 文档中找到,地址为:text-generation-webui/docs/04 ‐ Model Tab.md。
从 Python 代码运行
可以使用 llama-cpp-python 或 ctransformers 库从 Python 中使用 GGUF 模型。请注意,截至 2023 年 11 月 27 日,ctransformers 已经有一段时间没有更新,并且与一些最新的模型不兼容。因此,建议使用 llama-cpp-python。
使用 llama-cpp-python 在 Python 代码中加载此模型
完整文档请参阅:llama-cpp-python 文档。
首先安装包
根据你的系统运行以下命令之一:
# 无 GPU 加速的基础 ctransformers
pip install llama-cpp-python
# 带有 NVidia CUDA 加速
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# 或者带有 OpenBLAS 加速
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# 或者带有 CLBLast 加速
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# 或者带有 AMD ROCm GPU 加速(仅适用于 Linux)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# 或者带有 Metal GPU 加速(仅适用于 macOS 系统)
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# 在 Windows 中,在 PowerShell 中设置 CMAKE_ARGS 变量,例如对于 NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
简单的 llama-cpp-python 示例代码
from llama_cpp import Llama
# 将 gpu_layers 设置为要卸载到 GPU 的层数。如果系统上没有 GPU 加速,请将其设置为 0。
llm = Llama(
model_path="./openchat-3.5-0106.Q4_K_M.gguf", # 首先下载模型文件
n_ctx=8192, # 要使用的最大序列长度 - 请注意,更长的序列长度需要更多的资源
n_threads=8, # 要使用的 CPU 线程数,根据系统和性能进行调整
n_gpu_layers=35 # 如果有 GPU 加速,要卸载到 GPU 的层数
)
# 简单推理示例
output = llm(
"GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:", # 提示
max_tokens=512, # 生成最多 512 个令牌
stop=["</s>"], # 示例停止令牌 - 不一定适用于此特定模型!使用前请检查。
echo=True # 是否回显提示
)
# 聊天完成 API
llm = Llama(model_path="./openchat-3.5-0106.Q4_K_M.gguf", chat_format="llama-2") # 根据使用的模型设置 chat_format
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
与 LangChain 一起使用
以下是使用 llama-cpp-python 和 ctransformers 与 LangChain 的指南:
📚 详细文档
提示模板
GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:
兼容性
这些量化的 GGUFv2 文件与 2023 年 8 月 27 日之后的 llama.cpp 兼容,截至提交 d0cee0d。
它们还与许多第三方 UI 和库兼容,请参阅本 README 顶部的列表。
量化方法解释
点击查看详细信息
新的可用方法如下:
- GGML_TYPE_Q2_K:“type-1” 2 位量化,超级块包含 16 个块,每个块有 16 个权重。块尺度和最小值用 4 位量化。最终每个权重有效使用 2.5625 位(bpw)。
- GGML_TYPE_Q3_K:“type-0” 3 位量化,超级块包含 16 个块,每个块有 16 个权重。尺度用 6 位量化。最终使用 3.4375 bpw。
- GGML_TYPE_Q4_K:“type-1” 4 位量化,超级块包含 8 个块,每个块有 32 个权重。尺度和最小值用 6 位量化。最终使用 4.5 bpw。
- GGML_TYPE_Q5_K:“type-1” 5 位量化。与 GGML_TYPE_Q4_K 具有相同的超级块结构,最终使用 5.5 bpw。
- GGML_TYPE_Q6_K:“type-0” 6 位量化。超级块有 16 个块,每个块有 16 个权重。尺度用 8 位量化。最终使用 6.5625 bpw。
请参考下面的“提供的文件”表,查看哪些文件使用了哪些方法以及如何使用。
提供的文件
| 名称 | 量化方法 | 位数 | 大小 | 所需最大 RAM | 使用场景 |
|---|---|---|---|---|---|
| openchat-3.5-0106.Q2_K.gguf | Q2_K | 2 | 3.08 GB | 5.58 GB | 最小,但质量损失显著 - 不建议用于大多数用途 |
| openchat-3.5-0106.Q3_K_S.gguf | Q3_K_S | 3 | 3.16 GB | 5.66 GB | 非常小,但质量损失高 |
| openchat-3.5-0106.Q3_K_M.gguf | Q3_K_M | 3 | 3.52 GB | 6.02 GB | 非常小,但质量损失高 |
| openchat-3.5-0106.Q3_K_L.gguf | Q3_K_L | 3 | 3.82 GB | 6.32 GB | 小,但质量损失较大 |
| openchat-3.5-0106.Q4_0.gguf | Q4_0 | 4 | 4.11 GB | 6.61 GB | 旧版;小,但质量损失非常高 - 建议使用 Q3_K_M |
| openchat-3.5-0106.Q4_K_S.gguf | Q4_K_S | 4 | 4.14 GB | 6.64 GB | 小,但质量损失更大 |
| openchat-3.5-0106.Q4_K_M.gguf | Q4_K_M | 4 | 4.37 GB | 6.87 GB | 中等,质量平衡 - 推荐 |
| openchat-3.5-0106.Q5_0.gguf | Q5_0 | 5 | 5.00 GB | 7.50 GB | 旧版;中等,质量平衡 - 建议使用 Q4_K_M |
| openchat-3.5-0106.Q5_K_S.gguf | Q5_K_S | 5 | 5.00 GB | 7.50 GB | 大,质量损失低 - 推荐 |
| openchat-3.5-0106.Q5_K_M.gguf | Q5_K_M | 5 | 5.13 GB | 7.63 GB | 大,质量损失非常低 - 推荐 |
| openchat-3.5-0106.Q6_K.gguf | Q6_K | 6 | 5.94 GB | 8.44 GB | 非常大,质量损失极低 |
| openchat-3.5-0106.Q8_0.gguf | Q8_0 | 8 | 7.70 GB | 10.20 GB | 非常大,质量损失极低 - 不建议 |
注意:上述 RAM 数字假设没有 GPU 卸载。如果将层卸载到 GPU,这将减少 RAM 使用并使用 VRAM 代替。
🔧 技术细节
原始模型卡片:OpenChat 的 Openchat 3.5 0106
Advancing Open-source Language Models with Mixed-Quality Data
![]() Online Demo
|
Online Demo
|
 GitHub
|
GitHub
|
 Paper
|
Paper
|
 Discord
Discord
Sponsored by RunPod

目录
用法
要使用此模型,强烈建议按照我们仓库中的 安装指南 安装 OpenChat 包,并通过运行下表中的服务命令使用 OpenChat 兼容 OpenAI 的 API 服务器。该服务器使用 vLLM 进行了高吞吐量部署优化,可以在具有 24GB RAM 的消费级 GPU 上运行。要启用张量并行,请在服务命令后附加 --tensor-parallel-size N。
一旦启动,服务器将在 localhost:18888 监听请求,并与 OpenAI ChatCompletion API 规范 兼容。请参考以下示例请求作为参考。此外,你可以使用 OpenChat Web UI 获得更友好的用户体验。
如果你想将服务器部署为在线服务,可以使用 --api-keys sk-KEY1 sk-KEY2 ... 指定允许的 API 密钥,并使用 --disable-log-requests --disable-log-stats --log-file openchat.log 仅将日志记录到文件中。出于安全考虑,建议在服务器前使用 HTTPS 网关。
| 模型 | 大小 | 上下文 | 权重 | 服务命令 |
|---|---|---|---|---|
| OpenChat-3.5-0106 | 7B | 8192 | Huggingface | python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-0106 --engine-use-ray --worker-use-ray |
示例请求(点击展开)
💡 默认模式(GPT4 Correct):最适合编码、聊天和常规任务
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'
🧮 数学推理模式:专为解决数学问题而设计
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"condition": "Math Correct",
"messages": [{"role": "user", "content": "10.3 − 7988.8133 = "}]
}'
对话模板
💡 默认模式(GPT4 Correct):最适合编码、聊天和常规任务
GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant: Hi<|end_of_turn|>GPT4 Correct User: How are you today?<|end_of_turn|>GPT4 Correct Assistant:
🧮 数学推理模式:专为解决数学问题而设计
Math Correct User: 10.3 − 7988.8133=<|end_of_turn|>Math Correct Assistant:
⚠️ 注意:记得将 <|end_of_turn|> 设置为生成结束令牌。
默认(GPT4 Correct)模板也可以作为集成的 tokenizer.chat_template 使用,而不是手动指定模板:
messages = [
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hi"},
{"role": "user", "content": "How are you today?"}
]
tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
assert tokens == [1, 420, 6316, 28781, 3198, 3123, 1247, 28747, 22557, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747, 15359, 32000, 420, 6316, 28781, 3198, 3123, 1247, 28747, 1602, 460, 368, 3154, 28804, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747]
(实验性)评估器/反馈功能
在本次发布中,我们加入了评估器功能,以推动开源模型作为评估器的发展。你可以使用 默认模式(GPT4 Correct) 和以下提示(与 Prometheus 相同)来评估响应。
###任务描述:
给定一个指令(可能包含输入)、一个要评估的响应、一个得分为 5 的参考答案以及一个代表评估标准的评分规则。
1. 严格根据给定的评分规则,撰写一份详细的反馈,评估响应的质量,而不是进行一般性评估。
2. 撰写反馈后,给出一个 1 到 5 之间的整数分数。你应该参考评分规则。
3. 输出格式应如下所示:"反馈:(针对标准撰写的反馈)[结果](1 到 5 之间的整数)"
4. 请不要生成任何其他开头、结尾和解释。
###要评估的指令:
{orig_instruction}
###要评估的响应:
{orig_response}
###参考答案(得分 5):
{orig_reference_answer}
###评分规则:
[{orig_criteria}]
得分 1:{orig_score1_description}
得分 2:{orig_score2_description}
得分 3:{orig_score3_description}
得分 4:{orig_score4_description}
得分 5:{orig_score5_description}
###反馈:
基准测试
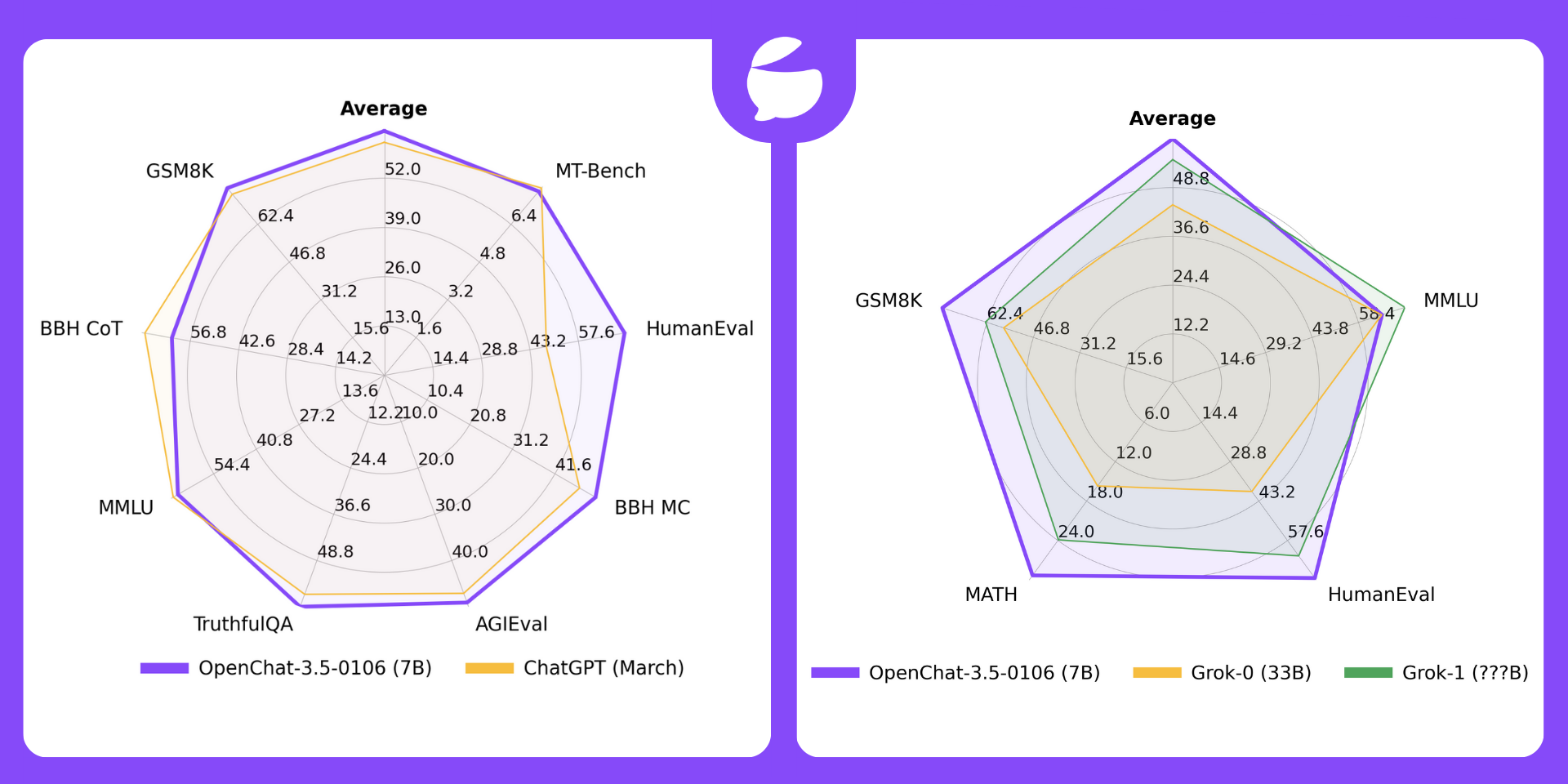
| 模型 | # 参数 | 平均分 | MT-Bench | HumanEval | BBH MC | AGIEval | TruthfulQA | MMLU | GSM8K | BBH CoT |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenChat-3.5-0106 | 7B | 64.5 | 7.8 | 71.3 | 51.5 | 49.1 | 61.0 | 65.8 | 77.4 | 62.2 |
| OpenChat-3.5-1210 | 7B | 63.8 | 7.76 | 68.9 | 49.5 | 48.0 | 61.8 | 65.3 | 77.3 | 61.8 |
| OpenChat-3.5 | 7B | 61.6 | 7.81 | 55.5 | 47.6 | 47.4 | 59.1 | 64.3 | 77.3 | 63.5 |
| ChatGPT(3 月版)* | ???B | 61.5 | 7.94 | 48.1 | 47.6 | 47.1 | 57.7 | 67.3 | 74.9 | 70.1 |
| OpenHermes 2.5 | 7B | 59.3 | 7.54 | 48.2 | 49.4 | 46.5 | 57.5 | 63.8 | 73.5 | 59.9 |
| OpenOrca Mistral | 7B | 52.7 | 6.86 | 38.4 | 49.4 | 42.9 | 45.9 | 59.3 | 59.1 | 58.1 |
| Zephyr-β^ | 7B | 34.6 | 7.34 | 22.0 | 40.6 | 39.0 | 40.8 | 39.8 | 5.1 | 16.0 |
| Mistral | 7B | - | 6.84 | 30.5 | 39.0 | 38.0 | - | 60.1 | 52.2 | - |
评估详情(点击展开)
*:ChatGPT(3 月版)的结果来自 GPT-4 技术报告、Chain-of-Thought Hub 和我们的评估。请注意,ChatGPT 不是一个固定的基线,会随着时间快速发展。
^:Zephyr-β 经常无法遵循少样本 CoT 指令,可能是因为它只与聊天数据对齐,而没有在少样本数据上进行训练。
**: Mistral 和开源 SOTA 结果取自指令调优模型论文和官方仓库中报告的结果。
所有模型都在聊天模式下进行评估(例如,应用相应的对话模板)。所有零样本基准测试遵循与 AGIEval 论文和 Orca 论文相同的设置。CoT 任务使用与 Chain-of-Thought Hub 相同的配置,HumanEval 使用 EvalPlus 进行评估,MT-bench 使用 FastChat 运行。要重现我们的结果,请遵循 我们的仓库 中的说明。
HumanEval+
| 模型 | 大小 | HumanEval+ pass@1 |
|---|---|---|
| OpenChat-3.5-0106 | 7B | 65.9 |
| ChatGPT(2023 年 12 月 12 日) | ???B | 64.6 |
| WizardCoder-Python-34B-V1.0 | 34B | 64.6 |
| OpenChat 3.5 1210 | 7B | 63.4 |
| OpenHermes 2.5 | 7B | 41.5 |
OpenChat-3.5 与 Grok 对比
🔥 OpenChat-3.5-0106(7B)现在在 所有 4 项基准测试 中都优于 Grok-0(33B),在平均表现和 3/4 项基准测试 中优于 Grok-1(???B)。
| 许可证 | # 参数 | 平均分 | MMLU | HumanEval | MATH | GSM8k | |
|---|---|---|---|---|---|---|---|
| OpenChat-3.5-0106 | Apache-2.0 | 7B | 61.0 | 65.8 | 71.3 | 29.3 | 77.4 |
| OpenChat-3.5-1210 | Apache-2.0 | 7B | 60.1 | 65.3 | 68.9 | 28.9 | 77.3 |
| OpenChat-3.5 | Apache-2.0 | 7B | 56.4 | 64.3 | 55.5 | 28.6 | 77.3 |
| Grok-0 | 专有许可证 | 33B | 44.5 | 65.7 | 39.7 | 15.7 | 56.8 |
| Grok-1 | 专有许可证 | ???B | 55.8 | 73 | 63.2 | 23.9 | 62.9 |
*:Grok 的结果由 X.AI 报告。
局限性
基础模型局限性 尽管 OpenChat 具有先进的能力,但它仍然受到其基础模型固有局限性的约束。这些局限性可能会影响模型在以下领域的性能:
- 复杂推理
- 数学和算术任务
- 编程和编码挑战
虚构不存在的信息 OpenChat 有时可能会生成不存在或不准确的信息,即所谓的“幻觉”。用户应该意识到这种可能性,并验证从模型获得的任何关键信息。
安全性 OpenChat 有时可能会生成有害、仇恨言论、有偏见的响应,或回答不安全的问题。在需要安全和经过审核的响应的用例中,应用额外的 AI 安全措施至关重要。
📄 许可证
我们的 OpenChat 3.5 代码和模型根据 Apache 许可证 2.0 分发。
引用
@article{wang2023openchat,
title={OpenChat: Advancing Open-source Language Models with Mixed-Quality Data},
author={Wang, Guan and Cheng, Sijie and Zhan, Xianyuan and Li, Xiangang and Song, Sen and Liu, Yang},
journal={arXiv preprint arXiv:2309.11235},
year={2023}
}
主要贡献者
- Wang Guan [imonenext@gmail.com],Cheng Sijie [csj23@mails.tsinghua.edu.cn],Alpay Ariyak [aariyak@wpi.edu]
- 我们期待听取你的意见,并在这个令人兴奋的项目上进行合作!
Discord
如需进一步的支持,以及关于这些模型和人工智能的讨论,请加入我们的: TheBloke AI 的 Discord 服务器
感谢与贡献方式
感谢 chirper.ai 团队! 感谢来自 gpus.llm-utils.org 的 Clay!
很多人问是否可以进行贡献。我喜欢提供模型并帮助他人,也希望能够花更多时间做这些事情,以及拓展到新的项目,如微调/训练。
如果你有能力且愿意贡献,我将不胜感激,这将帮助我继续提供更多模型,并开始新的人工智能项目。
捐赠者将在任何 AI/LLM/模型问题和请求上获得优先支持,访问私人 Discord 房间,以及其他福利。
- Patreon:https://patreon.com/TheBlokeAI
- Ko-Fi:https://ko-fi.com/TheBlokeAI
特别感谢:Aemon Algiz。
Patreon 特别提及:Michael Levine,阿明,Trailburnt,Nikolai Manek,John Detwiler,Randy H,Will Dee,Sebastain Graf,NimbleBox.ai,Eugene Pentland,Emad Mostaque,Ai Maven,Jim Angel,Jeff Scroggin,Michael Davis,Manuel Alberto Morcote,Stephen Murray,Robert,Justin Joy,Luke @flexchar,Brandon Frisco,Elijah Stavena,S_X,Dan Guido,Undi.,Komninos Chatzipapas,Shadi,theTransient,Lone Striker,Raven Klaugh,jjj,Cap'n Zoog,Michel-Marie MAUDET(LINAGORA),Matthew Berman,David,Fen Risland,Omer Bin Jawed,Luke Pendergrass,Kalila,OG,Erik Bjäreholt,Rooh Singh,Joseph William Delisle,Dan Lewis,TL,John Villwock,AzureBlack,Brad,Pedro Madruga,Caitlyn Gatomon,K,jinyuan sun,Mano Prime,Alex,Jeffrey Morgan,Alicia Loh,Illia Dulskyi,Chadd,transmissions 11,fincy,Rainer Wilmers,ReadyPlayerEmma,knownsqashed,Mandus,biorpg,Deo Leter,Brandon Phillips,SuperWojo,Sean Connelly,Iucharbius,Jack West,Harry Royden McLaughlin,Nicholas,terasurfer,Vitor Caleffi,Duane Dunston,Johann-Peter Hartmann,David Ziegler,Olakabola,Ken Nordquist,Trenton Dambrowitz,Tom X Nguyen,Vadim,Ajan Kanaga,Leonard Tan,Clay Pascal,Alexandros Triantafyllidis,JM33133,Xule,vamX,ya boyyy,subjectnull,Talal Aujan,Alps Aficionado,wassieverse,Ari Malik,James Bentley,Woland,Spencer Kim,Michael Dempsey,Fred von Graf,Elle,zynix,William Richards,Stanislav Ovsiannikov,Edmond Seymore,Jonathan Leane,Martin Kemka,usrbinkat,Enrico Ros
感谢所有慷慨的赞助者和捐赠者! 再次感谢 a16z 的慷慨资助。