🚀 SAM (小型智能模型)
SAM(小型智能模型)是一个70亿参数的模型,尽管规模相对较小,但展现出了令人瞩目的推理能力。SAM - 7B在包括GSM8k和ARC - C等多个推理基准测试中,超越了现有的最优模型。
若需了解该模型的完整详情,请阅读我们的发布博客文章。
🚀 快速开始
你可以按照以下代码示例运行该模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "SuperAGI/SAM"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Can elephants fly?"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
✨ 主要特性
- SAM - 7B在包括ARC - C和GSM8k等多个推理基准测试中,超越了GPT 3.5、Orca和其他几个700亿参数的模型。
- 有趣的是,尽管训练数据集比Orca - 13B小97%,但SAM - 7B在GSM8k测试中仍超越了Orca - 13B。
- 我们微调数据集中的所有回复均由开源模型生成,未借助GPT - 3.5或GPT - 4等最先进模型的帮助。
📚 详细文档
训练信息
| 属性 |
详情 |
| 训练团队 |
SuperAGI团队 |
| 硬件 |
NVIDIA 6 x H100 SxM (80GB) |
| 基础模型 |
Mistral 7B |
| 微调时长 |
4小时 |
| 训练轮数 |
1 |
| 批次大小 |
16 |
| 学习率 |
2e - 5 |
| 预热比例 |
0.1 |
| 优化器 |
AdamW |
| 调度器 |
Cosine |
示例提示
用于为指令模型构建提示的模板定义如下:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow - up instruction [/INST]
请注意,<s>和</s>是字符串开始(BOS)和字符串结束(EOS)的特殊标记,而[INST]和[/INST]是常规字符串。
评估
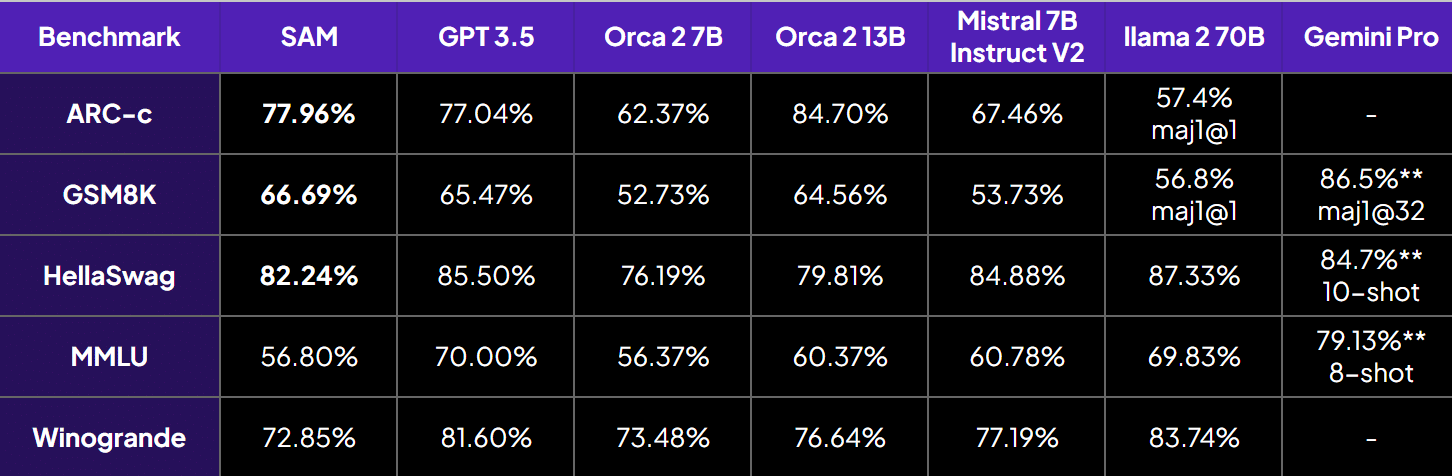
这些基准测试表明,与orca 2 - 7b、orca 2 - 13b和GPT - 3.5相比,我们的模型推理能力有所提升。尽管模型规模较小,但在多跳推理方面表现更优,如下图所示:
⚠️ 重要提示
建议将温度参数设置为0.3以获得最佳性能。
局限性
SAM证明了使用由开源大语言模型生成的少量但高质量的数据可以提升推理能力。该模型不适用于对话和简单问答,仅在任务分解和推理方面表现较好。它没有任何审核机制,因此由于缺乏对毒性、社会偏见和语言限制的防护措施,该模型不适合用于生产环境。我们希望与社区合作,共同构建更安全、更好的模型。
📄 许可证
本项目采用Apache - 2.0许可证。
👥 团队成员
Anmol Gautam、Arkajit Datta、Rajat Chawla、Ayush Vatsal、Sukrit Chatterjee、Adarsh Jha、Abhijeet Sinha、Rakesh Krishna、Adarsh Deep、Ishaan Bhola、Mukunda NS、Nishant Gaurav。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言