🚀 SAM (小型智能模型)
SAM(小型智能模型)是一個70億參數的模型,儘管規模相對較小,但展現出了令人矚目的推理能力。SAM - 7B在包括GSM8k和ARC - C等多個推理基準測試中,超越了現有的最優模型。
若需瞭解該模型的完整詳情,請閱讀我們的發佈博客文章。
🚀 快速開始
你可以按照以下代碼示例運行該模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "SuperAGI/SAM"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Can elephants fly?"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
✨ 主要特性
- SAM - 7B在包括ARC - C和GSM8k等多個推理基準測試中,超越了GPT 3.5、Orca和其他幾個700億參數的模型。
- 有趣的是,儘管訓練數據集比Orca - 13B小97%,但SAM - 7B在GSM8k測試中仍超越了Orca - 13B。
- 我們微調數據集中的所有回覆均由開源模型生成,未藉助GPT - 3.5或GPT - 4等最先進模型的幫助。
📚 詳細文檔
訓練信息
| 屬性 |
詳情 |
| 訓練團隊 |
SuperAGI團隊 |
| 硬件 |
NVIDIA 6 x H100 SxM (80GB) |
| 基礎模型 |
Mistral 7B |
| 微調時長 |
4小時 |
| 訓練輪數 |
1 |
| 批次大小 |
16 |
| 學習率 |
2e - 5 |
| 預熱比例 |
0.1 |
| 優化器 |
AdamW |
| 調度器 |
Cosine |
示例提示
用於為指令模型構建提示的模板定義如下:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow - up instruction [/INST]
請注意,<s>和</s>是字符串開始(BOS)和字符串結束(EOS)的特殊標記,而[INST]和[/INST]是常規字符串。
評估
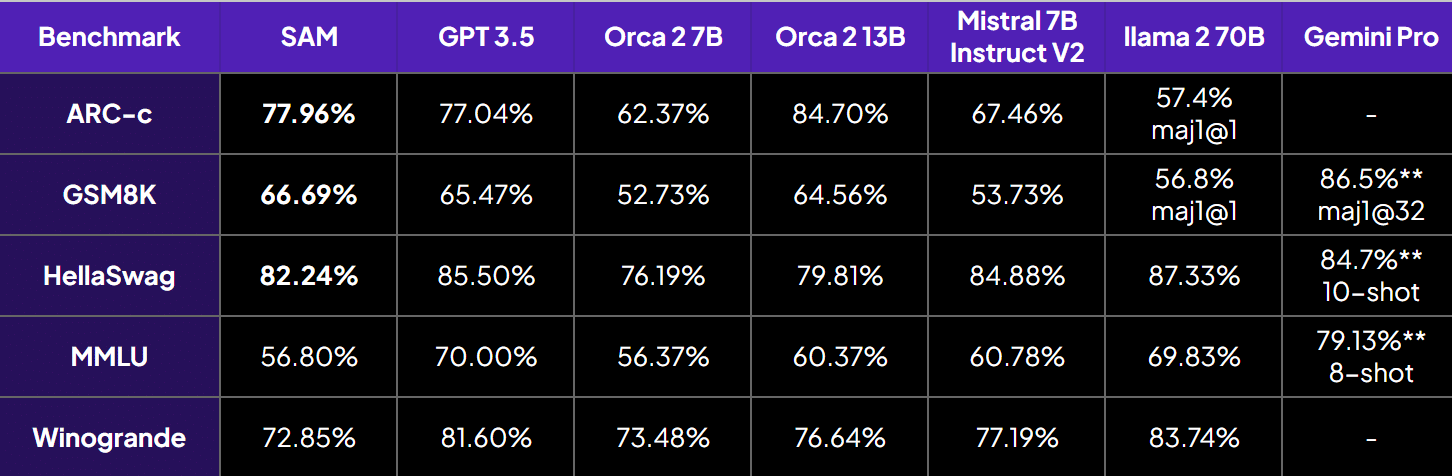
這些基準測試表明,與orca 2 - 7b、orca 2 - 13b和GPT - 3.5相比,我們的模型推理能力有所提升。儘管模型規模較小,但在多跳推理方面表現更優,如下圖所示:
⚠️ 重要提示
建議將溫度參數設置為0.3以獲得最佳性能。
侷限性
SAM證明了使用由開源大語言模型生成的少量但高質量的數據可以提升推理能力。該模型不適用於對話和簡單問答,僅在任務分解和推理方面表現較好。它沒有任何審核機制,因此由於缺乏對毒性、社會偏見和語言限制的防護措施,該模型不適合用於生產環境。我們希望與社區合作,共同構建更安全、更好的模型。
📄 許可證
本項目採用Apache - 2.0許可證。
👥 團隊成員
Anmol Gautam、Arkajit Datta、Rajat Chawla、Ayush Vatsal、Sukrit Chatterjee、Adarsh Jha、Abhijeet Sinha、Rakesh Krishna、Adarsh Deep、Ishaan Bhola、Mukunda NS、Nishant Gaurav。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言