%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 [MaziyarPanahi/WizardLM-2-7B-GGUF]
[MaziyarPanahi/WizardLM-2-7B-GGUF] 项目提供了 [microsoft/WizardLM-2-7B] 的 GGUF 格式模型文件,可用于文本生成任务,具有多语言支持和良好的性能表现。
🚀 快速开始
本项目包含了 [microsoft/WizardLM-2-7B] 的 GGUF 格式模型文件。以下是使用该模型的一些基本信息和步骤:
模型信息
| 属性 | 详情 |
|---|---|
| 模型名称 | WizardLM-2 7B |
| 开发者 | WizardLM@Microsoft AI |
| 基础模型 | mistralai/Mistral-7B-v0.1 |
| 参数数量 | 7B |
| 语言 | 多语言 |
| 博客 | Introducing WizardLM-2 |
| 仓库 | https://github.com/nlpxucan/WizardLM |
| 论文 | WizardLM-2 (即将发布) |
| 许可证 | Apache2.0 |
提示模板
{system_prompt}
USER: {prompt}
ASSISTANT: </s>
或者
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: {prompt} ASSISTANT: </s>......
以上模板取自原始 README。
推理示例脚本
我们在 GitHub 上提供了一个 WizardLM-2 推理演示 代码。
✨ 主要特性
模型能力
MT-Bench
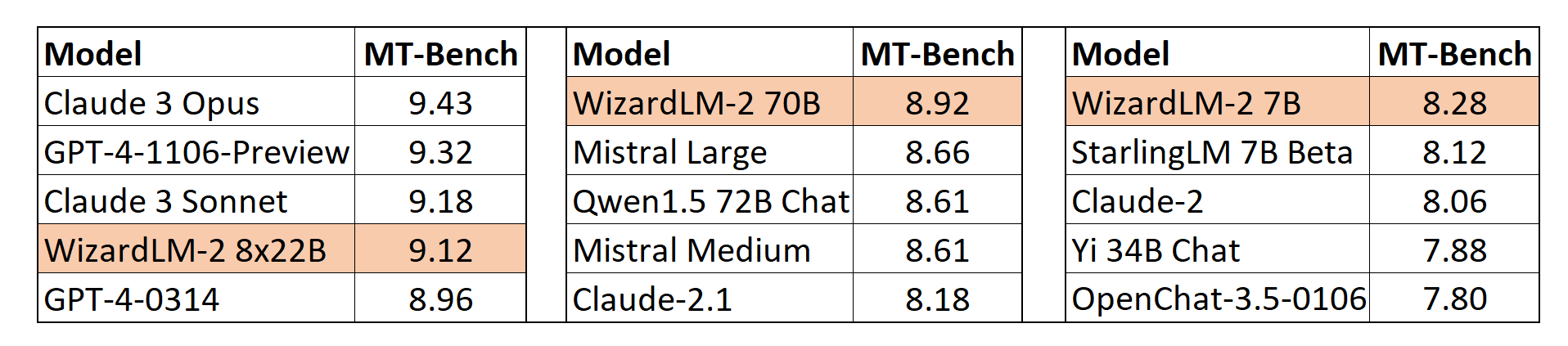
我们采用了 lmsys 提出的基于 GPT-4 的自动 MT-Bench 评估框架来评估模型性能。WizardLM-2 8x22B 与最先进的专有模型相比,表现出极具竞争力的性能。同时,WizardLM-2 7B 和 WizardLM-2 70B 在 7B 到 70B 模型规模的其他领先基线模型中,均为表现最佳的模型。
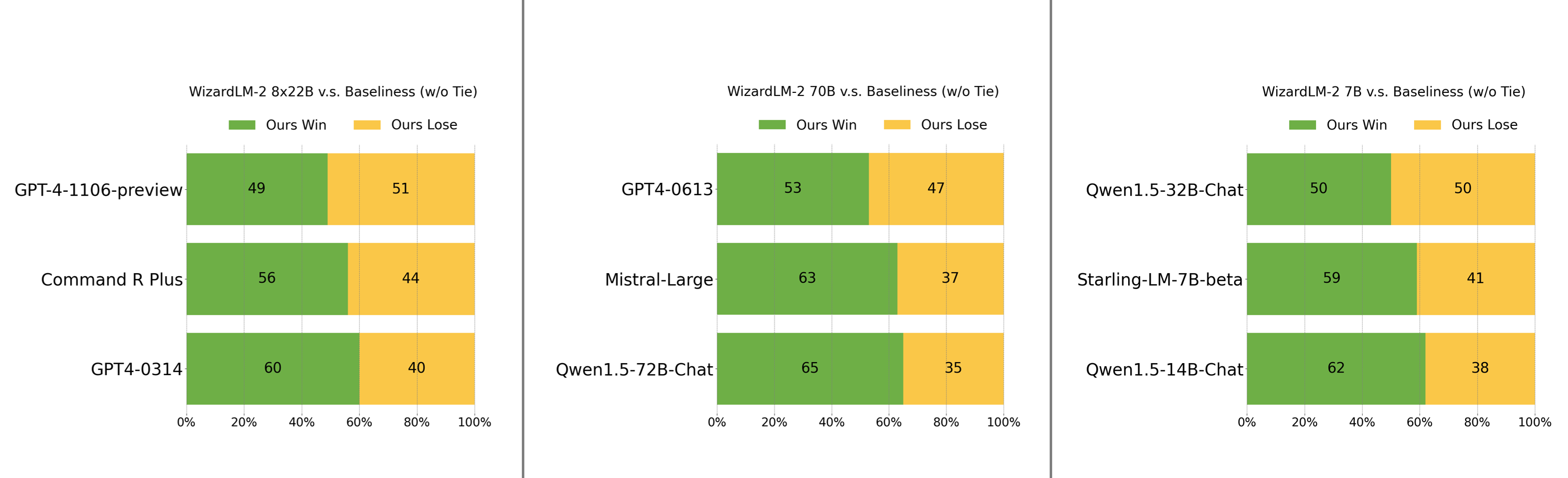
人工偏好评估
我们精心收集了一组复杂且具有挑战性的真实世界指令集,其中包括人类的主要需求,如写作、编码、数学、推理、代理和多语言。我们报告了无平局的胜负率:
- WizardLM-2 8x22B 仅略逊于 GPT-4-1106-preview,显著强于 Command R Plus 和 GPT4-0314。
- WizardLM-2 70B 优于 GPT4-0613、Mistral-Large 和 Qwen1.5-72B-Chat。
- WizardLM-2 7B 与 Qwen1.5-32B-Chat 性能相当,且超越了 Qwen1.5-14B-Chat 和 Starling-LM-7B-beta。
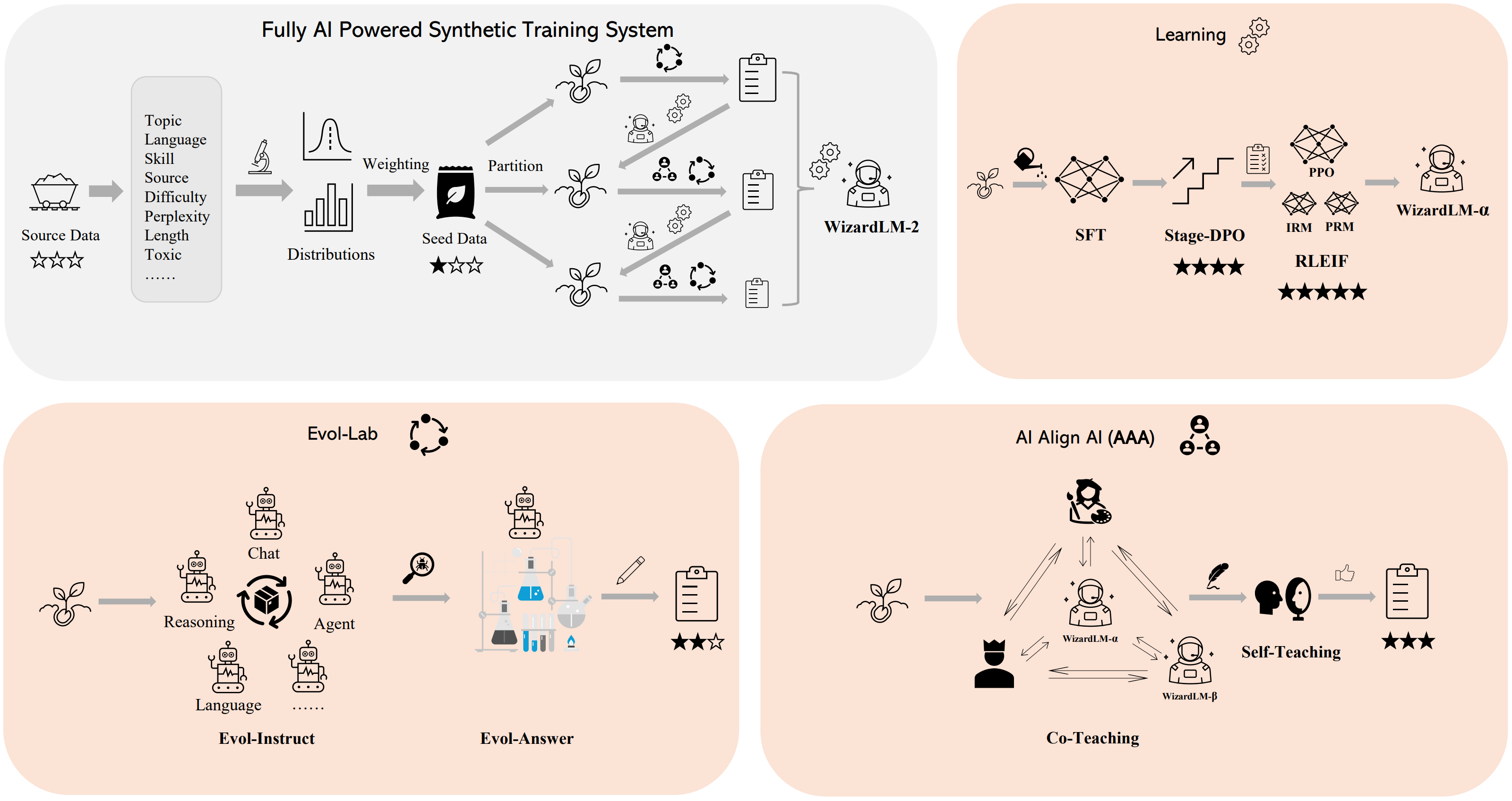
方法概述
我们构建了一个 完全由人工智能驱动的合成训练系统 来训练 WizardLM-2 模型。有关该系统的更多详细信息,请参阅我们的 博客。
📦 安装指南
关于 GGUF
GGUF 是 llama.cpp 团队在 2023 年 8 月 21 日推出的一种新格式,它取代了不再受 llama.cpp 支持的 GGML。
以下是已知支持 GGUF 的客户端和库的不完全列表:
- llama.cpp。GGUF 的源项目,提供 CLI 和服务器选项。
- text-generation-webui,最广泛使用的 Web UI,具有许多功能和强大的扩展,支持 GPU 加速。
- KoboldCpp,一个功能齐全的 Web UI,支持所有平台和 GPU 架构的 GPU 加速,特别适合讲故事。
- GPT4All,一个免费开源的本地运行 GUI,支持 Windows、Linux 和 macOS,具有全 GPU 加速。
- LM Studio,一个易于使用且功能强大的本地 GUI,适用于 Windows 和 macOS(Silicon),支持 GPU 加速,截至 2023 年 11 月 27 日,Linux 版本处于测试阶段。
- LoLLMS Web UI,一个很棒的 Web UI,具有许多有趣和独特的功能,包括一个完整的模型库,便于模型选择。
- Faraday.dev,一个有吸引力且易于使用的基于角色的聊天 GUI,适用于 Windows 和 macOS(Silicon 和 Intel),支持 GPU 加速。
- llama-cpp-python,一个支持 GPU 加速、LangChain 支持和 OpenAI 兼容 API 服务器的 Python 库。
- candle,一个专注于性能的 Rust ML 框架,包括 GPU 支持和易用性。
- ctransformers,一个支持 GPU 加速、LangChain 支持和 OpenAI 兼容 AI 服务器的 Python 库。请注意,截至 2023 年 11 月 27 日,ctransformers 已有很长时间未更新,不支持许多近期的模型。
量化方法说明
点击查看详情
可用的新方法如下:
- GGML_TYPE_Q2_K - “type-1” 2 位量化,超级块包含 16 个块,每个块有 16 个权重。块的缩放和最小值用 4 位量化,最终每个权重有效使用 2.5625 位(bpw)。
- GGML_TYPE_Q3_K - “type-0” 3 位量化,超级块包含 16 个块,每个块有 16 个权重。缩放用 6 位量化,最终使用 3.4375 bpw。
- GGML_TYPE_Q4_K - “type-1” 4 位量化,超级块包含 8 个块,每个块有 32 个权重。缩放和最小值用 6 位量化,最终使用 4.5 bpw。
- GGML_TYPE_Q5_K - “type-1” 5 位量化。与 GGML_TYPE_Q4_K 具有相同的超级块结构,最终使用 5.5 bpw。
- GGML_TYPE_Q6_K - “type-0” 6 位量化。超级块有 16 个块,每个块有 16 个权重。缩放用 8 位量化,最终使用 6.5625 bpw。
如何下载 GGUF 文件
手动下载注意事项:你几乎不需要克隆整个仓库!我们提供了多种不同的量化格式,大多数用户只需要选择并下载单个文件。
以下客户端/库将自动为你下载模型,并提供可用模型列表供你选择:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
在 text-generation-webui 中
在“下载模型”下,你可以输入模型仓库地址:MaziyarPanahi/WizardLM-2-7B-GGUF,并在其下方输入要下载的具体文件名,例如:WizardLM-2-7B-GGUF.Q4_K_M.gguf,然后点击“下载”。
在命令行中,同时下载多个文件
我建议使用 huggingface-hub Python 库:
pip3 install huggingface-hub
然后,你可以使用以下命令将任何单个模型文件高速下载到当前目录:
huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF WizardLM-2-7B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
更高级的 huggingface-cli 下载用法(点击查看)
你还可以使用模式同时下载多个文件:
huggingface-cli download [MaziyarPanahi/WizardLM-2-7B-GGUF](https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF) --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
有关使用 huggingface-cli 下载的更多文档,请参阅:HF -> Hub Python Library -> Download files -> Download from the CLI。
为了在高速连接(1Gbit/s 或更高)上加速下载,请安装 hf_transfer:
pip3 install hf_transfer
并将环境变量 HF_HUB_ENABLE_HF_TRANSFER 设置为 1:
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF WizardLM-2-7B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
Windows 命令行用户:你可以在下载命令前运行 set HF_HUB_ENABLE_HF_TRANSFER=1 来设置环境变量。
💻 使用示例
基础用法
./main -ngl 35 -m WizardLM-2-7B.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"
说明:
- 将
-ngl 32更改为要卸载到 GPU 的层数。如果你没有 GPU 加速,请删除该参数。 - 将
-c 32768更改为所需的序列长度。对于扩展序列模型(如 8K、16K、32K),必要的 RoPE 缩放参数将从 GGUF 文件中读取,并由 llama.cpp 自动设置。请注意,更长的序列长度需要更多的资源,因此你可能需要减小该值。 - 如果你想进行聊天式对话,请将
-p <PROMPT>参数替换为-i -ins。 - 有关其他参数及其用法,请参阅 llama.cpp 文档。
高级用法
在 text-generation-webui 中运行
更多说明可在 text-generation-webui 文档中找到,地址为:text-generation-webui/docs/04 ‐ Model Tab.md。
从 Python 代码运行
你可以使用 llama-cpp-python 或 ctransformers 库从 Python 中使用 GGUF 模型。请注意,截至 2023 年 11 月 27 日,ctransformers 已有很长时间未更新,不兼容一些近期的模型。因此,我建议你使用 llama-cpp-python。
如何在 Python 代码中加载此模型,使用 llama-cpp-python
首先安装包:
# 无 GPU 加速的基础 ctransformers
pip install llama-cpp-python
# 支持 NVidia CUDA 加速
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# 支持 OpenBLAS 加速
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# 支持 CLBLast 加速
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# 支持 AMD ROCm GPU 加速(仅适用于 Linux)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# 支持 macOS 系统的 Metal GPU 加速
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# 在 Windows 中,在 PowerShell 中设置变量 CMAKE_ARGS,例如对于 NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
简单的 llama-cpp-python 示例代码
from llama_cpp import Llama
# 将 gpu_layers 设置为要卸载到 GPU 的层数。如果你的系统没有 GPU 加速,请将其设置为 0。
llm = Llama(
model_path="./WizardLM-2-7B.Q4_K_M.gguf", # 首先下载模型文件
n_ctx=32768, # 要使用的最大序列长度 - 请注意,更长的序列长度需要更多的资源
n_threads=8, # 要使用的 CPU 线程数,根据你的系统和性能进行调整
n_gpu_layers=35 # 要卸载到 GPU 的层数,如果你有 GPU 加速可用
)
# 简单推理示例
output = llm(
"<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # 提示
max_tokens=512, # 生成最多 512 个令牌
stop=["</s>"], # 示例停止令牌 - 不一定适用于此特定模型!请在使用前检查。
echo=True # 是否回显提示
)
# 聊天完成 API
llm = Llama(model_path="./WizardLM-2-7B.Q4_K_M.gguf", chat_format="llama-2") # 根据你使用的模型设置 chat_format
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
如何与 LangChain 一起使用
以下是使用 llama-cpp-python 和 ctransformers 与 LangChain 的指南:
📚 详细文档
模型系统提示使用说明
❗重要提示
WizardLM-2 采用了 Vicuna 的提示格式,并支持 多轮 对话。提示应如下所示:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
新闻 🔥🔥🔥 [2024/04/15]
我们推出并开源了 WizardLM-2,这是我们的下一代先进大语言模型,在复杂聊天、多语言、推理和代理方面都有改进。新系列包括三个前沿模型:WizardLM-2 8x22B、WizardLM-2 70B 和 WizardLM-2 7B。
- WizardLM-2 8x22B 是我们最先进的模型,与那些领先的专有模型相比,表现出极具竞争力的性能,并且始终优于所有现有的先进开源模型。
- WizardLM-2 70B 达到了顶级推理能力,是相同规模下的首选。
- WizardLM-2 7B 是最快的模型,并且与现有的 10 倍大的开源领先模型相比,性能相当。
有关 WizardLM-2 的更多详细信息,请阅读我们的 发布博客文章 和即将发布的论文。
🔧 技术细节
本项目构建了一个 完全由人工智能驱动的合成训练系统 来训练 WizardLM-2 模型,采用了特定的量化方法(如 GGML_TYPE_Q2_K、GGML_TYPE_Q3_K 等)对模型进行处理,以提高模型的性能和效率。同时,在推理过程中,根据不同的硬件环境(如是否有 GPU 加速)和任务需求(如序列长度、对话模式等),可以调整相应的参数。
📄 许可证
本项目采用 Apache2.0 许可证。
🤗 HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 加入我们的 Discord