%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 歌词对齐框架
本项目是一个越南语歌曲歌词对齐框架,旨在构建一个模型,将歌词与音乐音频进行对齐,输出歌词中每个单词的开始时间和结束时间。
🚀 快速开始
加载模型
from transformers import AutoTokenizer, AutoFeatureExtractor
from model_handling import Wav2Vec2ForCTC
model_path = 'nguyenvulebinh/lyric-alignment'
model = Wav2Vec2ForCTC.from_pretrained(model_path).eval()
tokenizer = AutoTokenizer.from_pretrained(model_path)
feature_extractor = AutoFeatureExtractor.from_pretrained(model_path)
vocab = [tokenizer.convert_ids_to_tokens(i) for i in range(len(tokenizer.get_vocab()))]
进行歌词对齐
确保音频文件为 16kHz 单声道,可以使用 preprocessing.py 文件进行转换。
from predict import handle_sample
import torchaudio
import json
# wav_path: 音频文件路径,需为 16k 单声道
# path_lyric: 歌词数据的 json 文件路径,包含片段和单词列表
wav, _ = torchaudio.load(wav_path)
with open(path_lyric, 'r', encoding='utf-8') as file:
lyric_data = json.load(file)
lyric_alignment = handle_sample(wav, lyric_data)
示例输入与输出
示例输入文件 38303730395f313239.json
[{"s": 0, "e": 0, "l": [{"s": 0, "e": 0, "d": "Endgame"}, {"s": 0, "e": 0, "d": "chiến"}, {"s": 0, "e": 0, "d": "thắng"}]}, {"s": 0, "e": 0, "l": [{"s": 0, "e": 0, "d": "Chỉ"}, {"s": 0, "e": 0, "d": "lần"}, {"s": 0, "e": 0, "d": "duy"}, {"s": 0, "e": 0, "d": "nhất"}]}, {"s": 0, "e": 0, "l": [{"s": 0, "e": 0, "d": "Bởi"}, {"s": 0, "e": 0, "d": "IronMan"}, {"s": 0, "e": 0, "d": "và"}, {"s": 0, "e": 0, "d": "số"}, {"s": 0, "e": 0, "d": "3000"}]}]
示例输出
[{ "s": 0, "e": 661, "l": [ { "s": 0, "e": 240, "d": "Endgame" }, { "s": 200, "e": 420, "d": "chiến" }, { "s": 380, "e": 661, "d": "thắng" } ] }, { "s": 621, "e": 1543, "l": [ { "s": 621, "e": 861, "d": "Chỉ" }, { "s": 821, "e": 1082, "d": "lần" }, { "s": 1042, "e": 1302, "d": "duy" }, { "s": 1262, "e": 1543, "d": "nhất" } ] }, { "s": 1503, "e": 7274, "l": [ { "s": 1503, "e": 1703, "d": "Bởi" }, { "s": 1663, "e": 2404, "d": "IronMan" }, { "s": 2364, "e": 2605, "d": "và" }, { "s": 2565, "e": 2845, "d": "số" }, { "s": 2805, "e": 7274, "d": "3000" }]}]
✨ 主要特性
- 精准对齐:通过先进的算法和模型,实现歌词与音乐音频的精准对齐。
- 多数据源支持:既可以使用 Zalo 提供的公共数据集,也可以使用自行爬取的公共数据集。
- 灵活处理:对歌词中的特殊字符、英文单词、数字格式等进行灵活处理,提高模型的适应性。
📦 安装指南
若要从头开始复现模型,可运行以下命令:
CUDA_VISIBLE_DEVICES=0,1,2,3,4 python -m torch.distributed.launch --nproc_per_node 5 train.py
train.py 脚本会自动从 Hugging Face 下载数据集 nguyenvulebinh/song_dataset 和预训练模型 nguyenvulebinh/wav2vec2-large-vi-vlsp2020,并进行训练。
💻 使用示例
基础用法
from transformers import AutoTokenizer, AutoFeatureExtractor
from model_handling import Wav2Vec2ForCTC
model_path = 'nguyenvulebinh/lyric-alignment'
model = Wav2Vec2ForCTC.from_pretrained(model_path).eval()
tokenizer = AutoTokenizer.from_pretrained(model_path)
feature_extractor = AutoFeatureExtractor.from_pretrained(model_path)
vocab = [tokenizer.convert_ids_to_tokens(i) for i in range(len(tokenizer.get_vocab()))]
高级用法
from predict import handle_sample
import torchaudio
import json
# wav_path: 音频文件路径,需为 16k 单声道
# path_lyric: 歌词数据的 json 文件路径,包含片段和单词列表
wav, _ = torchaudio.load(wav_path)
with open(path_lyric, 'r', encoding='utf-8') as file:
lyric_data = json.load(file)
lyric_alignment = handle_sample(wav, lyric_data)
📚 详细文档
任务描述(Zalo AI 挑战赛 2022)
很多人喜欢跟着专辑中喜欢的歌手一起唱歌(卡拉 OK 风格),本项目的目标是构建一个模型,将歌词与音乐音频进行对齐。
- 输入:一段音乐(包含人声)及其歌词。
- 输出:歌词中每个单词的开始时间和结束时间。
评估时,将使用交并比($IoU$)来评估预测的准确性,$IoU$ 值越高越好。例如:

音频片段 $S_i$ 的预测结果与真实标签的 $IoU$ 计算公式如下:
$IoU(S_i) = \frac{1}{m} \sum_{j=1}^{m}{\frac{G_j\cap P_j}{G_j\cup P_j}}$ 其中,$m$ 是 $S_i$ 的标记数量。所有 $n$ 个音频片段的最终 $IoU$ 是它们对应 $IoU$ 的平均值: $Final_IoU = \frac{1}{n} \sum_{i=1}^{n}{IoU(S_i)}$
数据描述
Zalo 公共数据集
- 训练数据:来自约 480 首歌曲的 1057 个音乐片段。每个片段都提供了 WAV 格式的音频文件和一个真实标签的 JSON 文件,其中包含歌词和每个单词的对齐时间帧(以毫秒为单位)。
- 测试数据:
- 公共测试:来自约 120 首歌曲的 264 个音乐片段。
- 私有测试:来自约 200 首歌曲的 464 个音乐片段。
数据示例:

爬取的公共数据集
由于 Zalo 提供的数据集较小且有噪声,我们决定从其他公共来源爬取数据。幸运的是,我们的策略(详见 方法 部分)不需要每个单词的对齐时间帧,只需要歌曲及其歌词,就像典型的自动语音识别(ASR)数据集一样。
我们在 data_preparation 文件夹中详细介绍了数据爬取和处理过程。我们从 https://zingmp3.vn 网站共爬取了 30,000 首歌曲,约 1500 小时的音频。
方法
我们的策略主要基于 Ludwig Kürzinger 的 CTC-Segmentation 研究和 PyTorch 的 Wav2Vec2 强制对齐教程。引用 Ludwig Kürzinger 的研究:
CTC 分割是一种在音频记录开头或结尾存在额外未知语音部分的情况下提取正确音频 - 文本对齐的算法。它使用基于 CTC 的端到端网络,该网络事先在已对齐的数据上进行了训练,例如由 CTC/注意力 ASR 系统提供的数据。
基于 PyTorch 的 Wav2Vec2 强制对齐教程,对齐过程如下:
- 从音频波形估计逐帧标签概率。
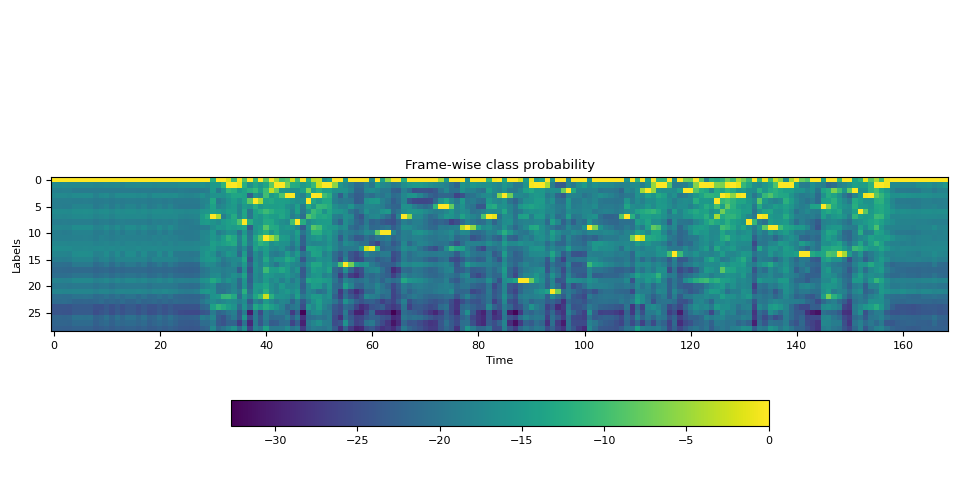
- 生成表示时间步上标签对齐概率的网格矩阵。
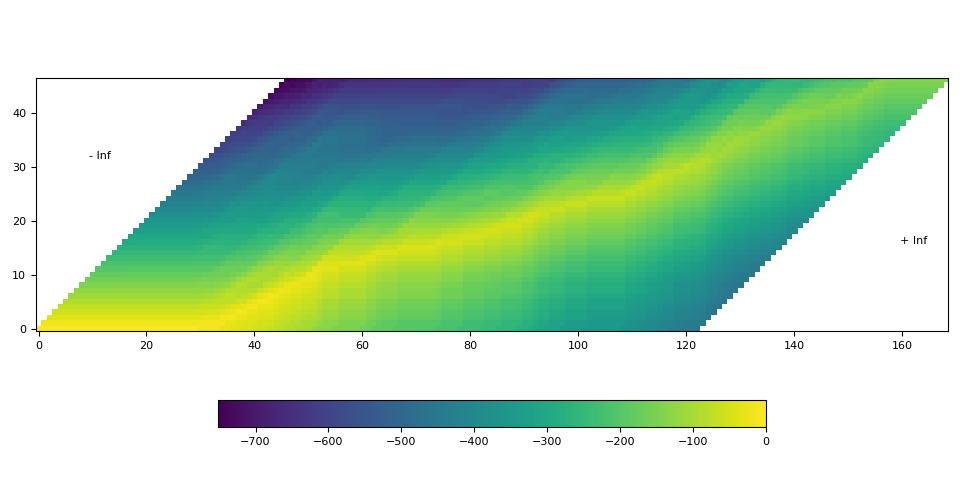
- 从网格矩阵中找到最可能的路径。
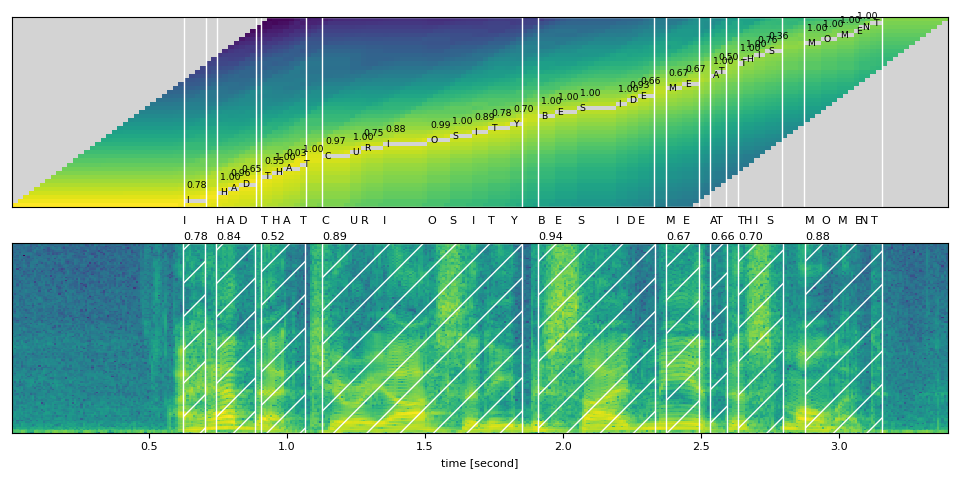
只有当具有良好的逐帧概率和正确的标签时,对齐效果才会良好。
- 良好的逐帧概率:可以通过强大的声学模型实现。我们的设置中,声学模型基于使用 CTC 损失训练的 wav2vec2 架构。
- 正确的标签:指口语形式的标签。由于歌词来源多样,可能包含特殊字符、混合英文和越南语单词、数字格式(日期、时间、货币等)、昵称等,这类数据会使模型难以将音频信号与文本歌词进行映射。我们的解决方案是将歌词中的所有单词从书面形式映射到口语形式。例如: | 书面形式 | 口语形式 | |----------|----------| | joker | giốc cơ | | running | răn ninh | | 0h | không giờ |
为了将英文单词转换为越南语发音,我们使用了 nguyenvulebinh/spelling-oov 模型。对于处理数字格式,我们使用了 Vinorm。对于其他特殊字符 ".,?... ",我们将其删除。
书面单词(例如 0h)的最终时间对齐是其口语单词(例如 không giờ)的时间对齐的拼接。
评估设置
声学模型
我们的最终模型基于 nguyenvulebinh/wav2vec2-large-vi-vlsp2020 模型。该模型在 13k 小时的越南语 YouTube 音频(无标签数据)上进行了预训练,并在 250 小时标记的 VLSP ASR 数据集上进行了微调,采样语音音频为 16kHz。我们使用该检查点,利用之前准备的 1500 小时数据训练了一个新的 ASR 模型。
在我们的实验中,使用了 5 块 RTX A6000 GPU(约 250GB),批量大小为 160,相当于每步 40 分钟。我们训练了约 50 个 epoch,耗时 78 小时。下图展示了训练过程前 35k 步的日志,最终训练损失约为 0.27。



训练后模型的字错误率(WER)性能如下:
- Zalo 公共数据集 - 测试集:0.2267
- 爬取的公共数据集 - 测试集:0.1427
对齐过程
对齐过程在方法部分已有描述。然而,为了在公共排行榜上达到 $IoU = 0.632$ 的结果,我们需要一些额外的步骤,详细如下:
- 输入格式化和转换为口语形式:例如,原始输入:
['Endgame', 'chiến', 'thắng', 'Chỉ', 'lần', 'duy', 'nhất', 'Bởi', 'IronMan', 'và', 'số', '3000']
口语形式输出将是:
['en gêm', 'chiến', 'thắng', 'chỉ', 'lần', 'duy', 'nhất', 'bởi', 'ai ron men', 'và', 'số', 'ba nghìn']
- 使用 CTC 分割算法对口语形式文本和音频进行强制对齐:方法部分详细介绍了 3 个步骤。
输出单词片段:
en: 0 -> 140
gêm: 200 -> 280
chiến: 340 -> 440
thắng: 521 -> 641
chỉ: 761 -> 861
lần: 961 -> 1042
duy: 1182 -> 1262
nhất: 1402 -> 1483
bởi: 1643 -> 1703
ai: 1803 -> 1863
ron: 2064 -> 2144
men: 2284 -> 2344
và: 2505 -> 2565
số: 2705 -> 2765
ba: 2946 -> 2986
nghìn: 3166 -> 3266
- 根据 Zalo 提供的标记数据的行为进行时间帧对齐:我们观察到连续单词的时间帧是连续的。因此,根据上一步的单词片段输出,我们按如下方式对齐每个单词的时间帧:
for i in range(len(word_segments) - 1):
word = word_segments[i]
next_word = word_segments[i + 1]
word.end = next_word.start
然而,我们制定了一些启发式规则,使输出更加准确:
- 一个单词的时长不超过 3 秒。
- 如果单词时长小于 1.4 秒 / 140 毫秒,我们将在该单词的开始和结束时间分别增加 20 毫秒 / 40 毫秒。这是因为数据是手动标记的,人类在处理小片段时容易出错。
- 每个单词的所有时间戳向左移动 120 毫秒。这条规则显著提高了 $IoU$ 结果,有时绝对 $IoU$ 值可提高 10%。我们也从数据中观察到了这种行为,就像我们唱卡拉 OK 时,希望歌词能稍微提前出现一样。在实践中,我们不建议使用这条规则。
所有这些启发式规则都在 utils.py 文件的 add_pad 函数中实现。
应用规则后的输出:
en: 0 -> 100
gêm: 60 -> 240
chiến: 200 -> 420
thắng: 380 -> 661
chỉ: 621 -> 861
lần: 821 -> 1082
duy: 1042 -> 1302
nhất: 1262 -> 1543
bởi: 1503 -> 1703
ai: 1663 -> 1964
rừn: 1923 -> 2184
mừn: 2144 -> 2404
và: 2364 -> 2605
số: 2565 -> 2845
ba: 2805 -> 3066
nghìn: 3046 -> 7274
- 将口语形式重新对齐到原始单词:
Endgame ['en: 0 -> 100', 'gêm: 60 -> 240']
chiến ['chiến: 200 -> 420']
thắng ['thắng: 380 -> 661']
Chỉ ['chỉ: 621 -> 861']
lần ['lần: 821 -> 1082']
duy ['duy: 1042 -> 1302']
nhất ['nhất: 1262 -> 1543']
Bởi ['bởi: 1503 -> 1703']
IronMan ['ai: 1663 -> 1964', 'ron: 1923 -> 2184', 'men: 2144 -> 2404']
và ['và: 2364 -> 2605']
số ['số: 2565 -> 2845']
3000 ['ba: 2805 -> 3066', 'nghìn: 3046 -> 7274']
最终的对齐结果与波形图一起绘制如下:

🔧 技术细节
- 声学模型:基于 wav2vec2 架构,使用 CTC 损失进行训练,在大量越南语音频数据上进行了预训练和微调。
- 对齐算法:采用 CTC 分割算法,结合启发式规则对时间帧进行调整,提高对齐的准确性。
📄 许可证
本项目采用 CC BY-NC 4.0 许可证。
致谢
感谢 Zalo AI 挑战赛 2022 的组织者提供了这个有趣的挑战。
联系信息
- 邮箱:nguyenvulebinh@gmail.com
- Twitter:
