%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 歌詞アライメント
ベトナム語の歌詞アライメントフレームワークです。このプロジェクトは、音楽のオーディオと歌詞を正確にアライメントするモデルを構築することを目的としています。
🚀 クイックスタート
このセクションでは、この歌詞アライメントフレームワークの概要と、評価指標について説明します。
タスク説明 (Zalo AI challenge 2022)
多くの人が、アルバムの好きな歌手の歌に合わせて歌うことが好きです(カラオケスタイル)。このタスクの目標は、音楽のオーディオと歌詞をアライメントするモデルを構築することです。
- 入力: 音楽セグメント(ボーカルを含む)とその歌詞。
- 出力: 歌詞内の各単語の開始時間と終了時間。
評価には、IoU(Intersection over Union)を使用します。IoUの値が高いほど、予測の精度が高いことを示します。例えば:

音声セグメント $S_i$ の予測と正解のIoUは、以下の式で計算されます。
$IoU(S_i) = \frac{1}{m} \sum_{j=1}^{m}{\frac{G_j\cap P_j}{G_j\cup P_j}}$
ここで、$m$ は $S_i$ のトークン数です。そして、すべての $n$ 個の音声セグメントにわたる最終的なIoUは、それぞれのIoUの平均です。
$Final_IoU = \frac{1}{n} \sum_{i=1}^{n}{IoU(S_i)}$
✨ 主な機能
この歌詞アライメントフレームワークの主な機能は、音楽のオーディオと歌詞を正確にアライメントすることです。具体的には、以下のような機能があります。
- ベトナム語の歌詞に対応。
- 高精度のアライメントを実現するための手法を採用。
- データのクローリングと前処理機能を備える。
📦 インストール
このセクションでは、モデルのトレーニングに必要なコマンドと、モデルの読み込み方法について説明します。
音響モデルのトレーニング
最終的なモデルは、nguyenvulebinh/wav2vec2-large-vi-vlsp2020 モデルをベースにしています。以下のコマンドを実行することで、モデルをトレーニングできます。
CUDA_VISIBLE_DEVICES=0,1,2,3,4 python -m torch.distributed.launch --nproc_per_node 5 train.py
train.py スクリプトは、huggingfaceの nguyenvulebinh/song_dataset からデータセットを自動的にダウンロードし、nguyenvulebinh/wav2vec2-large-vi-vlsp2020 の事前学習モデルを使用してトレーニングを行います。
モデルの読み込み
音響モデルはすでにhuggingface hubにアップロードされています。以下のコードを使用して、モデルを読み込むことができます。
from transformers import AutoTokenizer, AutoFeatureExtractor
from model_handling import Wav2Vec2ForCTC
model_path = 'nguyenvulebinh/lyric-alignment'
model = Wav2Vec2ForCTC.from_pretrained(model_path).eval()
tokenizer = AutoTokenizer.from_pretrained(model_path)
feature_extractor = AutoFeatureExtractor.from_pretrained(model_path)
vocab = [tokenizer.convert_ids_to_tokens(i) for i in range(len(tokenizer.get_vocab()))]
💻 使用例
このセクションでは、歌詞アライメントを行うためのコード例を示します。
基本的な使用法
from predict import handle_sample
import torchaudio
import json
# wav_path: オーディオファイルのパス。16kで単一チャンネルである必要があります。
# path_lyric: json形式の歌詞データのパス。セグメントと単語のリストを含みます。
wav, _ = torchaudio.load(wav_path)
with open(path_lyric, 'r', encoding='utf-8') as file:
lyric_data = json.load(file)
lyric_alignment = handle_sample(wav, lyric_data)
入力と出力の例
入力ファイル 38303730395f313239.json の例:
[{"s": 0, "e": 0, "l": [{"s": 0, "e": 0, "d": "Endgame"}, {"s": 0, "e": 0, "d": "chiến"}, {"s": 0, "e": 0, "d": "thắng"}]}, {"s": 0, "e": 0, "l": [{"s": 0, "e": 0, "d": "Chỉ"}, {"s": 0, "e": 0, "d": "lần"}, {"s": 0, "e": 0, "d": "duy"}, {"s": 0, "e": 0, "d": "nhất"}]}, {"s": 0, "e": 0, "l": [{"s": 0, "e": 0, "d": "Bởi"}, {"s": 0, "e": 0, "d": "IronMan"}, {"s": 0, "e": 0, "d": "và"}, {"s": 0, "e": 0, "d": "số"}, {"s": 0, "e": 0, "d": "3000"}]}]
歌詞アライメントの出力例:
[{ "s": 0, "e": 661, "l": [ { "s": 0, "e": 240, "d": "Endgame" }, { "s": 200, "e": 420, "d": "chiến" }, { "s": 380, "e": 661, "d": "thắng" } ] }, { "s": 621, "e": 1543, "l": [ { "s": 621, "e": 861, "d": "Chỉ" }, { "s": 821, "e": 1082, "d": "lần" }, { "s": 1042, "e": 1302, "d": "duy" }, { "s": 1262, "e": 1543, "d": "nhất" } ] }, { "s": 1503, "e": 7274, "l": [ { "s": 1503, "e": 1703, "d": "Bởi" }, { "s": 1663, "e": 2404, "d": "IronMan" }, { "s": 2364, "e": 2605, "d": "và" }, { "s": 2565, "e": 2845, "d": "số" }, { "s": 2805, "e": 7274, "d": "3000" }]}]
📚 ドキュメント
このセクションでは、データの説明、アプローチ、評価設定について詳しく説明します。
データ説明
Zalo公開データセット
- トレーニングデータ: 約480曲からの1057個の音楽セグメント。各セグメントには、WAV形式のオーディオファイルと、歌詞と各単語のアライメントされた時間フレーム(ミリ秒)を含む正解JSONファイルが提供されています。
- テストデータ:
- 公開テスト: 約120曲からの264個の音楽セグメント。
- 非公開テスト: 約200曲からの464個の音楽セグメント。
データの例:

クローリングした公開データセット
Zaloが提供するデータセットは小さく、ノイズが多いため、他の公開ソースからデータをクローリングすることにしました。幸いなことに、このタスクのアプローチ(Methodology セクションで詳細)では、各単語のアライメントされた時間フレームではなく、歌とその歌詞が必要なだけです。
データのクローリングと前処理の詳細は、data_preparation フォルダに記載されています。https://zingmp3.vn ウェブサイトから合計30,000曲をクローリングし、約1,500時間のオーディオを収集しました。
アプローチ
このアプローチは、Ludwig Kürzingerによる CTC-Segmentation の研究と、Pytorchの Forced Alignment with Wav2Vec2 のチュートリアルに大きく基づいています。Ludwig Kürzingerの研究から引用:
CTC-segmentationは、音声録音の開始または終了時に追加の未知の音声セクションが存在する場合に、適切な音声テキストアライメントを抽出するアルゴリズムです。これは、事前にアライメントされたデータでトレーニングされたCTCベースのエンドツーエンドネットワークを使用します。
Pytorchの Forced Alignment with Wav2Vec2 のチュートリアルに基づいて、アライメントのプロセスは以下のようになります。
- 音声波形からフレームごとのラベル確率を推定します。
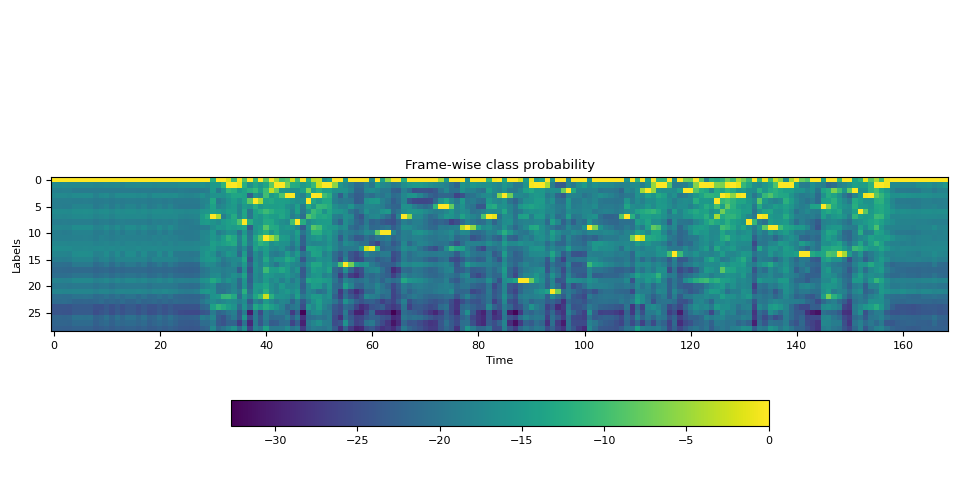
- タイムステップでラベルがアライメントされる確率を表すトレリス行列を生成します。
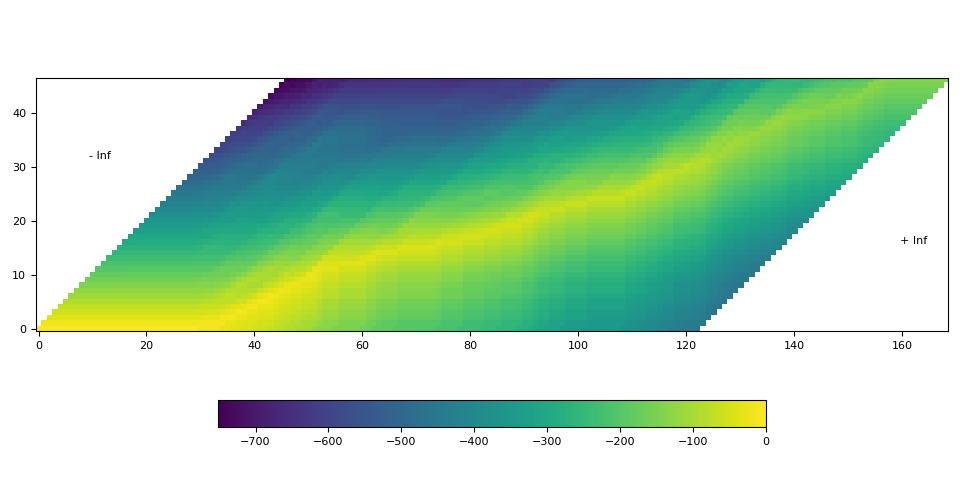
- トレリス行列から最も可能性の高いパスを見つけます。
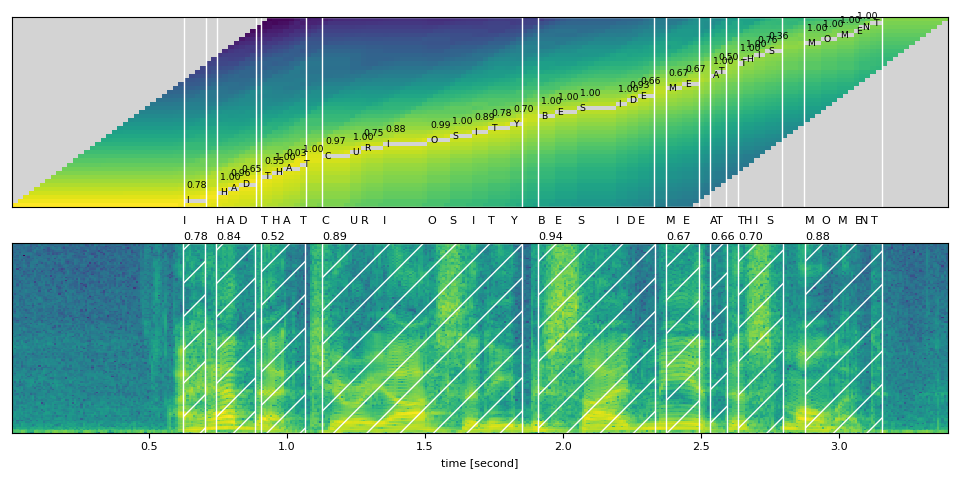
アライメントは、良好なフレームごとの確率と正しいラベルがある場合にのみうまく機能します。
- 良好なフレームごとの確率は、堅牢な音響モデルから得ることができます。このセットアップの音響モデルは、CTC損失を使用してトレーニングされたwav2vec2アーキテクチャに基づいています。
- 正しいラベルとは、発音形式のラベルを意味します。歌詞は様々なソースから得られるため、特殊文字、英語とベトナム語の単語の混合、数値形式(日付、時間、通貨など)、ニックネームなどが含まれる場合があります。このようなデータは、音声信号と歌詞テキストの間のマッピングをモデルが行うのを困難にします。解決策は、歌詞のすべての単語を書き形式から発音形式にマッピングすることです。例えば:
| 書き形式 | 発音形式 |
|---|---|
| joker | giốc cơ |
| running | răn ninh |
| 0h | không giờ |
英語の単語をベトナム語の発音方式に変換するために、nguyenvulebinh/spelling-oov モデルを使用します。数値形式を処理するために、Vinorm を使用します。その他の特殊文字 .,?... は削除します。
書き形式の単語(例:0h)の最終的な時間アライメントは、その発音単語(例:không giờ)の時間アライメントを連結したものになります。
評価設定
音響モデル
最終的なモデルは、nguyenvulebinh/wav2vec2-large-vi-vlsp2020 モデルに基づいています。このモデルは、13,000時間のベトナム語のYouTubeオーディオ(ラベルなしデータ)で事前学習され、16kHzのサンプリング音声オーディオの250時間のVLSP ASRデータセットで微調整されています。このチェックポイントを使用して、1,500時間(前のステップで準備された)のデータで新しいASRモデルをトレーニングしました。
トレーニング後のモデルの性能WERは以下の通りです。
- Zalo公開データセット - テストセット: 0.2267
- クローリングした公開データセット - テストセット: 0.1427
アライメントプロセス
アライメントプロセスは、Methodology セクションで説明されています。ただし、公開リーダーボードで $IoU = 0.632$ の結果を達成するために、いくつかの追加ステップが必要です。詳細は以下の通りです。
- 入力を整形し、発音形式に変換します。例えば、生の入力:
['Endgame', 'chiến', 'thắng', 'Chỉ', 'lần', 'duy', 'nhất', 'Bởi', 'IronMan', 'và', 'số', '3000']
発音形式の出力は次のようになります。
['en gêm', 'chiến', 'thắng', 'chỉ', 'lần', 'duy', 'nhất', 'bởi', 'ai ron men', 'và', 'số', 'ba nghìn']
- 発音形式のテキストとオーディオを、CTC-Segmentationアルゴリズムを使用して強制的にアライメントします。詳細(3ステップ)は Methodology セクションにあります。
出力の単語セグメント:
en: 0 -> 140
gêm: 200 -> 280
chiến: 340 -> 440
thắng: 521 -> 641
chỉ: 761 -> 861
lần: 961 -> 1042
duy: 1182 -> 1262
nhất: 1402 -> 1483
bởi: 1643 -> 1703
ai: 1803 -> 1863
ron: 2064 -> 2144
men: 2284 -> 2344
và: 2505 -> 2565
số: 2705 -> 2765
ba: 2946 -> 2986
nghìn: 3166 -> 3266
- Zaloが提供するラベル付きデータの特性に基づいて、連続する単語の時間フレームは連続していることが観察されます。したがって、前のステップからの単語セグメント出力から、各単語の時間フレームを以下のようにアライメントします。
for i in range(len(word_segments) - 1):
word = word_segments[i]
next_word = word_segments[i + 1]
word.end = next_word.start
ただし、出力をより正確にするために、いくつかのヒューリスティックルールを適用します。
- 単語の長さは3秒を超えない。
- 単語が1.4秒 / 140ミリ秒より短い場合、その単語の開始と終了に20ミリ秒 / 40ミリ秒を追加します。これは、データが手動でラベル付けされているため、人が小さなセグメントでエラーを犯しやすいためです。
- 各単語のすべてのタイムスタンプを120ミリ秒左にシフトします。このルールは、IoUの結果を大幅に改善します。時には、IoUの絶対値が10%改善することもあります。この特性はデータからも観察されており、カラオケをするときに歌詞が少し早く表示されるのと同じようなものです。ラベル付けを行う人がそのように考えていたと推測されます。実際には、このルールの使用はお勧めしません。
これらのヒューリスティックルールは、utils.py ファイルの add_pad 関数で実装されています。
ルール適用後の出力:
en: 0 -> 100
gêm: 60 -> 240
chiến: 200 -> 420
thắng: 380 -> 661
chỉ: 621 -> 861
lần: 821 -> 1082
duy: 1042 -> 1302
nhất: 1262 -> 1543
bởi: 1503 -> 1703
ai: 1663 -> 1964
rừn: 1923 -> 2184
mừn: 2144 -> 2404
và: 2364 -> 2605
số: 2565 -> 2845
ba: 2805 -> 3066
nghìn: 3046 -> 7274
- 発音形式を元の単語に再アライメントします。
Endgame ['en: 0 -> 100', 'gêm: 60 -> 240']
chiến ['chiến: 200 -> 420']
thắng ['thắng: 380 -> 661']
Chỉ ['chỉ: 621 -> 861']
lần ['lần: 821 -> 1082']
duy ['duy: 1042 -> 1302']
nhất ['nhất: 1262 -> 1543']
Bởi ['bởi: 1503 -> 1703']
IronMan ['ai: 1663 -> 1964', 'ron: 1923 -> 2184', 'men: 2144 -> 2404']
và ['và: 2364 -> 2605']
số ['số: 2565 -> 2845']
3000 ['ba: 2805 -> 3066', 'nghìn: 3046 -> 7274']
最終的なアライメント結果を波形と一緒に描画すると、以下のようになります。

🔧 技術詳細
この歌詞アライメントフレームワークは、音響モデルとアライメントアルゴリズムを組み合わせることで、高精度の歌詞アライメントを実現しています。具体的には、以下の技術が使用されています。
- 音響モデル: wav2vec2アーキテクチャをベースに、CTC損失を使用してトレーニングされています。
- アライメントアルゴリズム: CTC-Segmentationアルゴリズムを使用して、音声と歌詞をアライメントします。
- データ前処理: 歌詞の書き形式を発音形式に変換し、特殊文字や数値形式を適切に処理します。
📄 ライセンス
このプロジェクトは、CC BY-NC 4.0ライセンスの下で公開されています。
謝辞
Zalo AI Challenge 2022の主催者の皆様に、この面白いチャレンジを提供していただき、感謝いたします。
連絡先
nguyenvulebinh@gmail.com
