%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Distil-Whisper: distil-small.en
Distil-Whisper是一种经过蒸馏的语音识别模型,它基于论文 Robust Knowledge Distillation via Large-Scale Pseudo Labelling 提出。相比原始的Whisper模型,Distil-Whisper 推理速度快6倍,模型大小缩小49%,并且在分布外评估集上的字错率(WER)误差 控制在1%以内。
本仓库是distil-small.en的存储库,它是 Whisper small.en 的蒸馏变体。distil-small.en是 最小的Distil-Whisper检查点,仅包含1.66亿个参数,非常适合内存受限的应用场景(如设备端应用)。
对于大多数其他应用场景,建议使用 distil-medium.en 或 distil-large-v2 检查点,因为它们不仅推理速度更快,而且字错率(WER)表现更好:
| 模型 | 参数数量 / M | 相对延迟 ↑ | 短文本WER ↓ | 长文本WER ↓ |
|---|---|---|---|---|
| large-v3 | 1550 | 1.0 | 8.4 | 11.0 |
| large-v2 | 1550 | 1.0 | 9.1 | 11.7 |
| distil-large-v3 | 756 | 6.3 | 9.7 | 10.8 |
| distil-large-v2 | 756 | 5.8 | 10.1 | 11.6 |
| distil-medium.en | 394 | 6.8 | 11.1 | 12.4 |
| distil-small.en | 166 | 5.6 | 12.1 | 12.8 |
⚠️ 重要提示
Distil-Whisper目前仅支持英语语音识别。我们正在与社区合作,对其他语言的Whisper模型进行蒸馏。如果您有兴趣参与特定语言的蒸馏工作,请查看 训练代码。待多语言检查点准备好后,我们会在 Distil-Whisper仓库 中更新。
为什么distil-small.en比distil-large-v2慢?
distil-medium.en 和 distil-large-v2 均使用两层解码器,而distil-small.en使用四层解码器。增加解码器层数可以提高模型的字错率(WER)表现,但会降低推理速度。我们发现,对于 distil-small.en,四层解码器是获得合理WER性能的最低要求,它在推理速度比Whisper large-v2 快5.6倍的同时,WER误差控制在3%以内。当我们尝试使用两层解码器进行蒸馏时,模型的WER比large-v2差5%以上,尽管推理速度快7.8倍。我们将蒸馏两层的small.en模型作为未来的工作方向。
🚀 快速开始
Distil-Whisper从Hugging Face 🤗 Transformers 4.35版本开始得到支持。要运行该模型,首先需要安装最新版本的Transformers库。在本示例中,我们还将安装 🤗 Datasets 库,以便从Hugging Face Hub加载示例音频数据集:
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
✨ 主要特性
- 速度快:相比原始的Whisper模型,Distil-Whisper推理速度快6倍。
- 模型小:模型大小缩小49%,适合内存受限的应用场景。
- 准确率高:在分布外评估集上的字错率(WER)误差控制在1%以内。
- 支持多种解码方式:支持短文本转录、长文本转录和推测解码等多种解码方式。
- 支持多种加速方法:支持Flash Attention、Torch Scale-Product-Attention (SDPA) 等加速方法。
- 支持多种框架:支持Hugging Face 🤗 Transformers、openai-whisper、Transformers.js等多种框架。
📦 安装指南
安装依赖库
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
安装其他可选依赖库
- Flash Attention:
pip install flash-attn --no-build-isolation
- optimum:
pip install --upgrade optimum
- openai-whisper:
pip install --upgrade openai-whisper
- Transformers.js:
npm i @xenova/transformers
💻 使用示例
基础用法
短文本转录
模型可以使用 pipeline 类对短文本音频文件(< 30秒)进行转录,示例代码如下:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-small.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
如果要转录本地音频文件,只需在调用pipeline时传入音频文件的路径:
- result = pipe(sample)
+ result = pipe("audio.mp3")
长文本转录
Distil-Whisper使用分块算法对长文本音频文件(> 30秒)进行转录。实际上,这种分块长文本算法比OpenAI在Whisper论文中提出的顺序算法快9倍(详见 Distil-Whisper论文 的表7)。
要启用分块功能,只需在调用pipeline时传入 chunk_length_s 参数。对于Distil-Whisper,15秒的分块长度是最优的。要启用批量处理,只需传入 batch_size 参数:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-small.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "default", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
高级用法
推测解码
Distil-Whisper可以作为Whisper的辅助模型,用于 推测解码。推测解码在数学上保证了与Whisper相同的输出结果,同时推理速度快2倍。这使得它可以完美替代现有的Whisper推理流程,因为可以保证输出结果一致。
在以下代码示例中,我们将Distil-Whisper辅助模型独立加载到主Whisper推理流程中,并将其指定为生成过程中的“辅助模型”:
from transformers import pipeline, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "distil-whisper/distil-small.en"
assistant_model = AutoModelForSpeechSeq2Seq.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
📚 详细文档
额外的速度和内存优化方法
Flash Attention
如果您的GPU支持,我们建议使用 Flash-Attention 2。要使用Flash Attention,首先需要安装 Flash Attention:
pip install flash-attn --no-build-isolation
然后,在调用 from_pretrained 方法时传入 use_flash_attention_2=True 参数:
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
Torch Scale-Product-Attention (SDPA)
如果您的GPU不支持Flash Attention,我们建议使用 BetterTransformers。要使用BetterTransformers,首先需要安装optimum:
pip install --upgrade optimum
然后,在使用模型之前,将其转换为“BetterTransformer”模型:
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
在 openai-whisper 中运行Distil-Whisper
要在原始的Whisper格式中使用该模型,首先需要确保您已经安装了 openai-whisper 包:
pip install --upgrade openai-whisper
以下代码示例展示了如何使用 🤗 Datasets 库加载LibriSpeech数据集中的示例文件并进行转录:
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from whisper import load_model, transcribe
distil_small_en = hf_hub_download(repo_id="distil-whisper/distil-small.en", filename="original-model.bin")
model = load_model(distil_small_en)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["array"]
sample = torch.from_numpy(sample).float()
pred_out = transcribe(model, audio=sample)
print(pred_out["text"])
请注意,首次运行该示例时,模型权重将被下载并保存到缓存中。后续再次运行相同示例时,权重将直接从缓存中加载,无需再次下载。
如果要转录本地音频文件,只需在调用 transcribe 方法时传入音频文件的路径作为 audio 参数:
pred_out = transcribe(model, audio="audio.mp3")
在Transformers.js中运行Distil-Whisper
Distil-Whisper甚至可以使用 Transformers.js 在浏览器中完全运行:
- 从 NPM 安装Transformers.js:
npm i @xenova/transformers
- 导入库并使用pipeline API进行推理:
import { pipeline } from '@xenova/transformers';
const transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-small.en');
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
const output = await transcriber(url);
// { text: " And so my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
您可以访问在线 Distil-Whisper Web演示 亲自体验。您会发现,它可以在本地浏览器中运行,无需服务器支持!
更多信息请参考 文档。
8bit和4bit量化
该功能即将推出!
🔧 技术细节
模型架构
Distil-Whisper继承了Whisper的编码器 - 解码器架构。编码器将语音向量输入序列映射到隐藏状态向量序列,解码器根据所有先前的标记和编码器的隐藏状态自回归地预测文本标记。因此,编码器只需要进行一次前向传播,而解码器的运行次数与生成的标记数量相同。实际上,这意味着解码器在总推理时间中占比超过90%。因此,为了优化推理延迟,我们的重点是最小化解码器的推理时间。
为了对Whisper模型进行蒸馏,我们在保持编码器不变的情况下减少了解码器的层数。编码器(绿色部分)完全从教师模型复制到学生模型,并在训练过程中冻结。学生模型的解码器由教师模型解码器层的子集组成,这些层从最大间隔的层初始化。然后,模型在KL散度和伪标签损失项的加权和上进行训练。
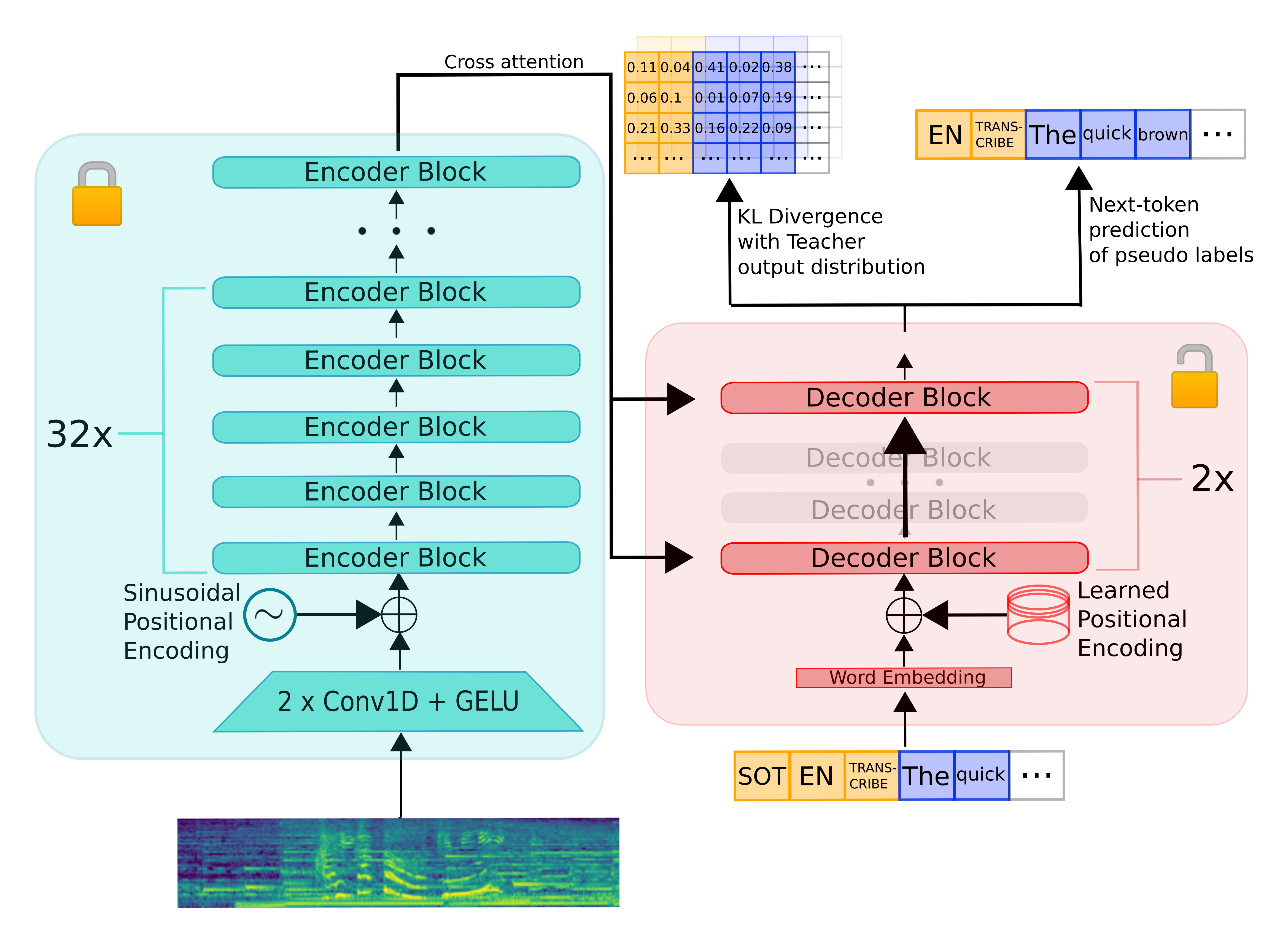
评估方法
以下代码示例展示了如何使用 流式模式 在LibriSpeech验证集的clean子集上评估Distil-Whisper模型,这意味着无需将音频数据下载到本地设备:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from transformers.models.whisper.english_normalizer import EnglishTextNormalizer
from datasets import load_dataset
from evaluate import load
import torch
from tqdm import tqdm
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-small.en"
# load the model + processor
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, use_safetensors=True, low_cpu_mem_usage=True)
model = model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
# load the dataset with streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# define the evaluation metric
wer_metric = load("wer")
normalizer = EnglishTextNormalizer(processor.tokenizer.english_spelling_normalizer)
def inference(batch):
# 1. Pre-process the audio data to log-mel spectrogram inputs
audio = [sample["array"] for sample in batch["audio"]]
input_features = processor(audio, sampling_rate=batch["audio"][0]["sampling_rate"], return_tensors="pt").input_features
input_features = input_features.to(device, dtype=torch_dtype)
# 2. Auto-regressively generate the predicted token ids
pred_ids = model.generate(input_features, max_new_tokens=128)
# 3. Decode the token ids to the final transcription
batch["transcription"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
batch["reference"] = batch["text"]
return batch
dataset = dataset.map(function=inference, batched=True, batch_size=16)
all_transcriptions = []
all_references = []
# iterate over the dataset and run inference
for i, result in tqdm(enumerate(dataset), desc="Evaluating..."):
all_transcriptions.append(result["transcription"])
all_references.append(result["reference"])
# normalize predictions and references
all_transcriptions = [normalizer(transcription) for transcription in all_transcriptions]
all_references = [normalizer(reference) for reference in all_references]
# compute the WER metric
wer = 100 * wer_metric.compute(predictions=all_transcriptions, references=all_references)
print(wer)
输出结果:
3.4326070294536297
预期用途
Distil-Whisper旨在作为Whisper在英语语音识别任务中的直接替代品。特别是,它在分布外测试数据上的字错率(WER)表现与Whisper相当,同时在短文本和长文本音频上的推理速度快6倍。
训练数据
Distil-Whisper在Hugging Face Hub上的9个开源、许可宽松的语音数据集的22000小时音频数据上进行训练:
| 数据集 | 时长 / h | 说话人数量 | 领域 | 许可证 |
|---|---|---|---|---|
| People's Speech | 12,000 | 未知 | Internet Archive | CC-BY-SA-4.0 |
| Common Voice 13 | 3,000 | 未知 | Narrated Wikipedia | CC0-1.0 |
| GigaSpeech | 2,500 | 未知 | Audiobook, podcast, YouTube | apache-2.0 |
| Fisher | 1,960 | 11,900 | Telephone conversations | LDC |
| LibriSpeech | 960 | 2,480 | Audiobooks | CC-BY-4.0 |
| VoxPopuli | 540 | 1,310 | European Parliament | CC0 |
| TED-LIUM | 450 | 2,030 | TED talks | CC-BY-NC-ND 3.0 |
| SwitchBoard | 260 | 540 | Telephone conversations | LDC |
| AMI | 100 | 未知 | Meetings | CC-BY-4.0 |
| 总计 | 21,770 | 18,260+ |
这些数据集涵盖了10个不同的领域和超过50000名说话人。数据集的多样性对于确保蒸馏后的模型对音频分布和噪声具有鲁棒性至关重要。
然后,我们使用Whisper large-v2模型对音频数据进行伪标签标注:我们使用Whisper为训练集中的所有音频生成预测结果,并在训练过程中使用这些结果作为目标标签。使用伪标签可以确保转录结果在不同数据集之间保持一致的格式,并在训练过程中提供序列级别的蒸馏信号。
WER过滤
Whisper的伪标签预测可能会出现转录错误和幻觉问题。为了确保我们只在准确的伪标签上进行训练,我们在训练过程中采用了一种简单的WER启发式方法。首先,我们对Whisper的伪标签和每个数据集提供的真实标签进行归一化处理。然后,我们计算这些标签之间的WER。如果WER超过指定的阈值,我们将丢弃该训练示例;否则,我们将其保留用于训练。
Distil-Whisper论文 的第9.2节展示了这种过滤方法对于提高蒸馏模型下游性能的有效性。我们还将Distil-Whisper对幻觉问题的鲁棒性部分归因于这种过滤方法。
训练过程
模型在批量大小为2056的情况下进行了50000次优化步骤(或12个epoch)的训练。Tensorboard训练日志可以在以下链接中找到:https://huggingface.co/distil-whisper/distil-small.en/tensorboard?params=scalars#frame
评估结果
蒸馏后的模型在分布外(OOD)短文本音频上的字错率(WER)与Whisper相差在1%以内,在OOD长文本音频上的表现比Whisper好0.1%。这种性能提升归因于较低的幻觉率。
有关每个数据集评估结果的详细细分,请参考 Distil-Whisper论文 的表16和表17。
Distil-Whisper还在 ESB基准 数据集上进行了评估,作为 OpenASR排行榜 的一部分,其WER与Whisper相差在0.2%以内。
复现Distil-Whisper
复现Distil-Whisper的训练和评估代码可以在Distil-Whisper仓库中找到:https://github.com/huggingface/distil-whisper/tree/main/training
📄 许可证
Distil-Whisper继承了OpenAI的Whisper模型的 MIT许可证。
引用
如果您使用了该模型,请考虑引用 Distil-Whisper论文:
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
致谢
- OpenAI提供了Whisper 模型 和 原始代码库。
- Hugging Face 🤗 Transformers 提供了模型集成支持。
- Google的 TPU Research Cloud (TRC) 项目提供了Cloud TPU v4资源。
@rsonavane在LibriSpeech数据集上发布了早期版本的Distil-Whisper。