%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
Unispeech 1350 En 90 It Ft 1h
UniSpeech是一个统一的语音表征学习模型,结合了监督式音素CTC学习和自监督学习,特别针对意大利语进行了微调。
下载量 19
发布时间 : 3/2/2022
模型简介
该模型基于16kHz采样的语音音频及音素标签进行预训练,并在1小时意大利语音素数据上微调,适用于音素分类任务。
模型特点
多任务学习
同时进行监督式音素CTC学习和音素感知对比自监督学习
跨语言泛化
生成的表征能更好捕捉与音素结构相关的信息,提升跨语言和跨领域的泛化能力
高效微调
仅需1小时的意大利语音素数据即可完成微调
模型能力
语音识别
音素分类
跨语言语音表征学习
使用案例
语音识别
意大利语音素识别
将意大利语语音转换为音素序列
音素错误率6.69%
语音技术研究
跨语言语音表征研究
研究语音表征在不同语言间的迁移能力
相比自监督预训练和监督迁移学习,分别最高可降低13.4%和17.8%的相对音素错误率
🚀 UniSpeech-Large-plus 意大利语版
UniSpeech-Large-plus 意大利语版是一个语音模型,基于 16kHz 采样的语音音频和音素标签进行预训练,随后在 1 小时的意大利语音素数据上进行微调。使用该模型时,需确保输入的语音采样率为 16kHz,且文本已转换为音素序列。
🚀 快速开始
本模型是在音素分类任务上进行微调的语音模型。使用前请确保你的语音输入采样率为 16kHz,文本已转换为音素序列。
✨ 主要特性
- 基于 Microsoft 的 UniSpeech 模型架构。
- 在公共 CommonVoice 语料库上进行跨语言表示学习,表现优于自监督预训练和监督迁移学习。
- 可用于语音识别任务,能有效降低音素错误率和单词错误率。
📦 安装指南
本 README 未提及安装步骤,可参考原模型仓库 https://github.com/microsoft/UniSpeech/tree/main/UniSpeech 进行安装。
💻 使用示例
基础用法
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
sample = next(iter(load_dataset("common_voice", "it", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# => 'm ɪ a n n o f a tː o ʊ n o f f ɛ r t a k e n o n p o t e v o p r ɔ p r i o r i f j ʊ t a r e'
# for "Mi hanno fatto un\'offerta che non potevo proprio rifiutare."
高级用法
from datasets import load_dataset, load_metric
import datasets
import torch
from transformers import AutoModelForCTC, AutoProcessor
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
ds = load_dataset("mozilla-foundation/common_voice_3_0", "it", split="train+validation+test+other")
wer = load_metric("wer")
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
# taken from
# https://github.com/microsoft/UniSpeech/blob/main/UniSpeech/examples/unispeech/data/it/phonesMatches_reduced.json
with open("./testSeqs_uniform_new_version.text", "r") as f:
lines = f.readlines()
# retrieve ids model is evaluated on
ids = [x.split("\t")[0] for x in lines]
ds = ds.filter(lambda p: p.split("/")[-1].split(".")[0] in ids, input_columns=["path"])
ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
def decode(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", sampling_rate=16_000)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, axis=-1)
batch["prediction"] = processor.batch_decode(pred_ids)
batch["target"] = processor.tokenizer.phonemize(batch["sentence"])
return batch
out = ds.map(decode, remove_columns=ds.column_names)
per = wer.compute(predictions=out["prediction"], references=out["target"])
print("per", per)
# -> should give per 0.06685252146070828 - compare to results below
📚 详细文档
模型信息
| 属性 | 详情 |
|---|---|
| 模型类型 | 语音模型,在音素分类任务上进行微调 |
| 训练数据 | 基于 16kHz 采样的语音音频和音素标签进行预训练,在 1 小时的意大利语音素数据上进行微调 |
论文信息
- 标题:UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
- 作者:Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
- 摘要:本文提出了一种名为 UniSpeech 的统一预训练方法,用于利用有标签和无标签数据学习语音表示。在多任务学习方式下,进行监督音素 CTC 学习和音素感知对比自监督学习。所得表示能够捕捉与音素结构更相关的信息,并提高跨语言和领域的泛化能力。我们在公共 CommonVoice 语料库上评估了 UniSpeech 用于跨语言表示学习的有效性。结果表明,UniSpeech 在语音识别方面分别比自监督预训练和监督迁移学习最大相对降低了 13.4% 和 17.8% 的音素错误率(所有测试语言的平均值)。在领域转移语音识别任务上,UniSpeech 也展示了其可迁移性,相对于先前方法相对降低了 6% 的单词错误率。
官方结果
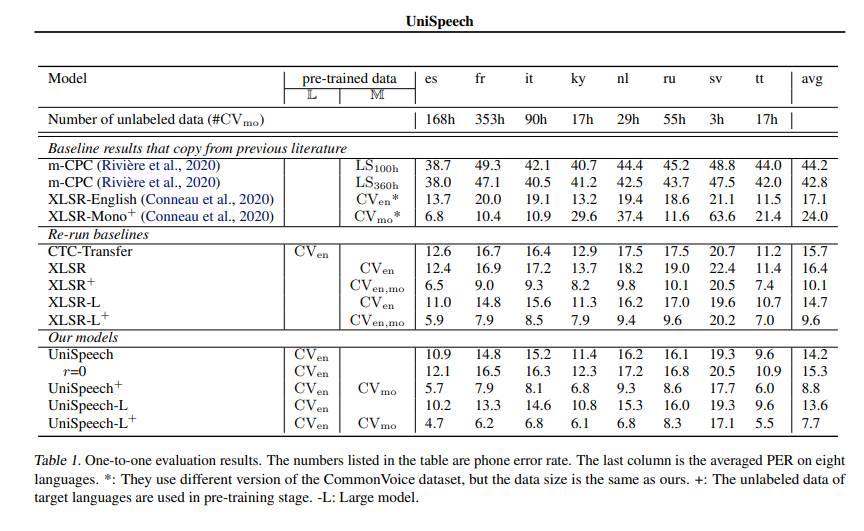
查看 UniSpeeech-L^{+} - it 的官方结果:
🔧 技术细节
原模型可在 https://github.com/microsoft/UniSpeech/tree/main/UniSpeech 找到。
📄 许可证
官方许可证可在 https://github.com/microsoft/UniSpeech/blob/main/LICENSE 查看。
贡献者
本模型由 cywang 和 patrickvonplaten 贡献。
Voice Activity Detection
MIT
基于pyannote.audio 2.1版本的语音活动检测模型,用于识别音频中的语音活动时间段
语音识别
V
pyannote
7.7M
181
Wav2vec2 Large Xlsr 53 Portuguese
Apache-2.0
这是一个针对葡萄牙语语音识别任务微调的XLSR-53大模型,基于Common Voice 6.1数据集训练,支持葡萄牙语语音转文本。
语音识别 其他
W
jonatasgrosman
4.9M
32
Whisper Large V3
Apache-2.0
Whisper是由OpenAI提出的先进自动语音识别(ASR)和语音翻译模型,在超过500万小时的标注数据上训练,具有强大的跨数据集和跨领域泛化能力。
语音识别 支持多种语言
W
openai
4.6M
4,321
Whisper Large V3 Turbo
MIT
Whisper是由OpenAI开发的最先进的自动语音识别(ASR)和语音翻译模型,经过超过500万小时标记数据的训练,在零样本设置下展现出强大的泛化能力。
语音识别 Transformers 支持多种语言
Transformers 支持多种语言
W
openai
4.0M
2,317
Wav2vec2 Large Xlsr 53 Russian
Apache-2.0
基于facebook/wav2vec2-large-xlsr-53模型微调的俄语语音识别模型,支持16kHz采样率的语音输入
语音识别 其他
W
jonatasgrosman
3.9M
54
Wav2vec2 Large Xlsr 53 Chinese Zh Cn
Apache-2.0
基于facebook/wav2vec2-large-xlsr-53模型微调的中文语音识别模型,支持16kHz采样率的语音输入。
语音识别 中文
W
jonatasgrosman
3.8M
110
Wav2vec2 Large Xlsr 53 Dutch
Apache-2.0
基于facebook/wav2vec2-large-xlsr-53微调的荷兰语语音识别模型,在Common Voice和CSS10数据集上训练,支持16kHz音频输入。
语音识别 其他
W
jonatasgrosman
3.0M
12
Wav2vec2 Large Xlsr 53 Japanese
Apache-2.0
基于facebook/wav2vec2-large-xlsr-53模型微调的日语语音识别模型,支持16kHz采样率的语音输入
语音识别 日语
W
jonatasgrosman
2.9M
33
Mms 300m 1130 Forced Aligner
基于Hugging Face预训练模型的文本与音频强制对齐工具,支持多种语言,内存效率高
语音识别 Transformers 支持多种语言
M
MahmoudAshraf
2.5M
50
Wav2vec2 Large Xlsr 53 Arabic
Apache-2.0
基于facebook/wav2vec2-large-xlsr-53微调的阿拉伯语语音识别模型,在Common Voice和阿拉伯语语音语料库上训练
语音识别 阿拉伯语
W
jonatasgrosman
2.3M
37
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98