%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 UniSpeech-Large-plus イタリア語版
このモデルは、16kHzでサンプリングされた音声オーディオと音素ラベルを使用して事前学習され、その後1時間分のイタリア語の音素でファインチューニングされた大規模モデルです。モデルを使用する際には、入力音声も16kHzでサンプリングされていること、またテキストが音素列に変換されていることを確認してください。
論文: UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
著者: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
概要 本論文では、ラベル付きデータとラベル無しデータの両方を用いて音声表現を学習するための統一的な事前学習アプローチであるUniSpeechを提案します。このアプローチでは、教師付き音素CTC学習と音素認識型のコントラスト自己教師付き学習がマルチタスク学習の方式で行われます。得られた表現は、音素構造とより相関の高い情報を捉えることができ、言語やドメイン間の汎化能力を向上させます。我々は、公開されているCommonVoiceコーパスを用いて、UniSpeechの多言語表現学習の有効性を評価しました。結果は、UniSpeechが自己教師付き事前学習と教師付き転移学習に比べて、音声認識の相対的音素誤り率をそれぞれ最大13.4%と17.8%削減することを示しています(すべてのテスト言語で平均)。また、ドメインシフト音声認識タスクにおいても、UniSpeechの転移可能性が実証されており、以前のアプローチに比べて相対的単語誤り率が6%削減されています。
元のモデルは、https://github.com/microsoft/UniSpeech/tree/main/UniSpeech で見つけることができます。
🚀 クイックスタート
このドキュメントでは、UniSpeech-Large-plusのイタリア語版モデルの使用方法や関連情報を提供します。
✨ 主な機能
- 音素分類にファインチューニングされた音声モデルです。
- 多言語表現学習において、自己教師付き事前学習や教師付き転移学習よりも高い性能を発揮します。
📦 インストール
このモデルは、transformersライブラリを通じて簡単に利用できます。必要な依存関係をインストールすることで、すぐに使用を開始できます。
💻 使用例
基本的な使用法
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
sample = next(iter(load_dataset("common_voice", "it", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# => 'm ɪ a n n o f a tː o ʊ n o f f ɛ r t a k e n o n p o t e v o p r ɔ p r i o r i f j ʊ t a r e'
# for "Mi hanno fatto un\'offerta che non potevo proprio rifiutare."
高度な使用法
from datasets import load_dataset, load_metric
import datasets
import torch
from transformers import AutoModelForCTC, AutoProcessor
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
ds = load_dataset("mozilla-foundation/common_voice_3_0", "it", split="train+validation+test+other")
wer = load_metric("wer")
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
# taken from
# https://github.com/microsoft/UniSpeech/blob/main/UniSpeech/examples/unispeech/data/it/phonesMatches_reduced.json
with open("./testSeqs_uniform_new_version.text", "r") as f:
lines = f.readlines()
# retrieve ids model is evaluated on
ids = [x.split("\t")[0] for x in lines]
ds = ds.filter(lambda p: p.split("/")[-1].split(".")[0] in ids, input_columns=["path"])
ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
def decode(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", sampling_rate=16_000)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, axis=-1)
batch["prediction"] = processor.batch_decode(pred_ids)
batch["target"] = processor.tokenizer.phonemize(batch["sentence"])
return batch
out = ds.map(decode, remove_columns=ds.column_names)
per = wer.compute(predictions=out["prediction"], references=out["target"])
print("per", per)
# -> should give per 0.06685252146070828 - compare to results below
📚 ドキュメント
- 論文: UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
- 元のモデル: https://github.com/microsoft/UniSpeech/tree/main/UniSpeech
🔧 技術詳細
このモデルは、MicrosoftによるUniSpeechモデルをベースに、イタリア語の音素データでファインチューニングされています。事前学習では、16kHzでサンプリングされた音声オーディオと音素ラベルを使用し、多言語表現学習の有効性が検証されています。
📄 ライセンス
公式のライセンスは、こちらで確認できます。
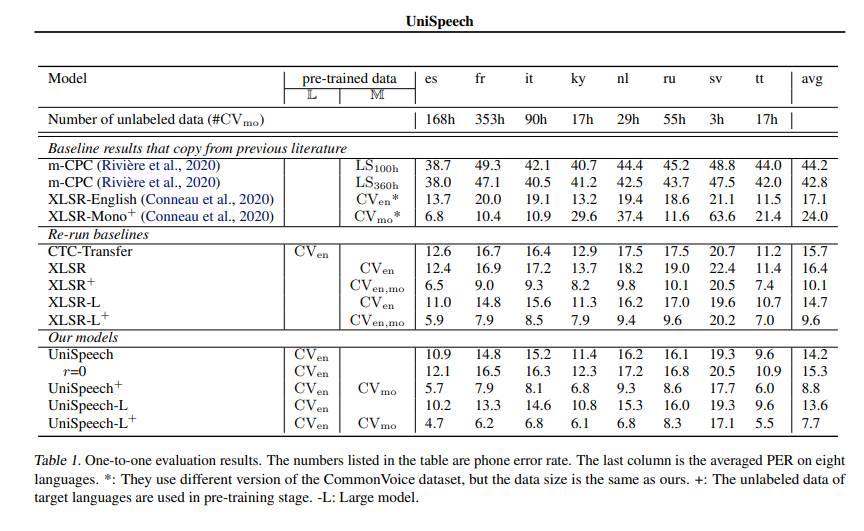
公式の結果
UniSpeeech-L^{+} - it の結果は以下の通りです。
貢献者
このモデルは、cywang と patrickvonplaten によって貢献されました。