%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 互信息对比句嵌入模型(miCSE):小样本场景下的句嵌入方案
miCSE 是一种专为小样本句嵌入设计的语言模型,通过正则化自注意力分布,实现句法一致性学习,提升样本利用效率,尤其适用于训练数据有限的现实应用场景。它可用于句子或短段落编码,在检索、句子相似度比较和聚类等任务中表现出色。
🚀 快速开始
安装依赖
确保你已经安装了所需的 Python 库,如 transformers、torch、numpy、tqdm、datasets、umap-learn、sentence-transformers 等。你可以使用以下命令进行安装:
pip install transformers torch numpy tqdm datasets umap-learn sentence-transformers
模型使用
以下是几个使用 miCSE 模型的示例:
句子相似度比较
from transformers import AutoTokenizer, AutoModel
import torch.nn as nn
tokenizer = AutoTokenizer.from_pretrained("sap-ai-research/miCSE")
model = AutoModel.from_pretrained("sap-ai-research/miCSE")
# 对列表中的句子进行编码,预设最大 token 长度 (max_length)
max_length = 32
sentences = [
"This is a sentence for testing miCSE.",
"This is yet another test sentence for the mutual information Contrastive Sentence Embeddings model."
]
batch = tokenizer.batch_encode_plus(
sentences,
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=True
)
# 计算嵌入并仅保留 [CLS] 嵌入(第一个 token)
# 获取原始嵌入(无梯度)
with torch.no_grad():
outputs = model(**batch, output_hidden_states=True, return_dict=True)
embeddings = outputs.last_hidden_state[:,0]
# 定义相似度度量,例如余弦相似度
sim = nn.CosineSimilarity(dim=-1)
# 计算第一句和第二句之间的相似度
cos_sim = sim(embeddings.unsqueeze(1),
embeddings.unsqueeze(0))
print(f"Distance: {cos_sim[0,1].detach().item()}")
聚类
from transformers import AutoTokenizer, AutoModel
import torch.nn as nn
import torch
import numpy as np
import tqdm
from datasets import load_dataset
import umap
import umap.plot as umap_plot
# 确定可用的硬件
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained("/Users/d065243/miCSE")
model = AutoModel.from_pretrained("/Users/d065243/miCSE")
model.to(device);
# 加载 Twitter 数据进行情感聚类
dataset = load_dataset("tweet_eval", "sentiment")
# 计算推文的嵌入
# 设置批量大小和最大推文 token 长度
batch_size = 50
max_length = 128
iterations = int(np.floor(len(dataset['train'])/batch_size))*batch_size
embedding_stack = []
classes = []
for i in tqdm.notebook.tqdm(range(0,iterations,batch_size)):
# 创建批次
batch = tokenizer.batch_encode_plus(
dataset['train'][i:i+batch_size]['text'],
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=True
).to(device)
classes = classes + dataset['train'][i:i+batch_size]['label']
# 无梯度的模型推理
with torch.no_grad():
outputs = model(**batch, output_hidden_states=True, return_dict=True)
embeddings = outputs.last_hidden_state[:,0]
embedding_stack.append( embeddings.cpu().clone() )
embeddings = torch.vstack(embedding_stack)
# 使用 UMAP 在二维空间中对嵌入进行聚类
umap_model = umap.UMAP(n_neighbors=250,
n_components=2,
min_dist=1.0e-9,
low_memory=True,
angular_rp_forest=True,
metric='cosine')
umap_model.fit(embeddings)
# 绘制结果
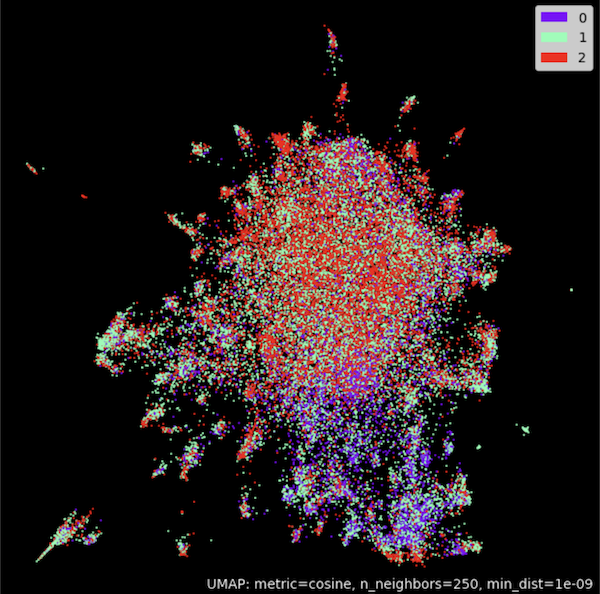
umap_plot.points(umap_model, labels = np.array(classes),theme='fire')
使用 SentenceTransformers
from sentence_transformers import SentenceTransformer, util
from sentence_transformers import models
import torch.nn as nn
# 使用带有 [CLS] 嵌入的模型
model_name = 'sap-ai-research/miCSE'
word_embedding_model = models.Transformer(model_name, max_seq_length=32)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# 使用余弦相似度作为度量
cos_sim = nn.CosineSimilarity(dim=-1)
# 用于比较的句子列表
sentences_1 = ["This is a sentence for testing miCSE.",
"This is using mutual information Contrastive Sentence Embeddings model."]
sentences_2 = ["This is testing miCSE.",
"Similarity with miCSE"]
# 计算两个列表的嵌入
embeddings_1 = model.encode(sentences_1, convert_to_tensor=True)
embeddings_2 = model.encode(sentences_2, convert_to_tensor=True)
# 计算余弦相似度
cosine_sim_scores = cos_sim(embeddings_1, embeddings_2)
# 输出结果
for i in range(len(sentences_1)):
print(f"Similarity {cosine_sim_scores[i][i]:.2f}: {sentences_1[i]} << vs. >> {sentences_2[i]}")
✨ 主要特性
- 句法一致性学习:在对比学习过程中,miCSE 模型通过正则化自注意力分布,强制不同随机失活增强视图之间的句法一致性,使表示学习更加高效。
- 样本高效性:通过正则化自注意力,模型在训练过程中对样本的利用效率大大提高,即使在训练集规模有限的情况下,也能实现自监督学习。
- 适用于现实应用:由于现实应用中训练数据通常有限,miCSE 的小样本学习能力使其在实际场景中具有很高的应用价值。
📦 安装指南
安装所需的 Python 库,可使用以下命令:
pip install transformers torch numpy tqdm datasets umap-learn sentence-transformers
💻 使用示例
基础用法
上述的句子相似度比较示例展示了 miCSE 模型的基础用法,通过输入句子,模型输出句子的嵌入向量,进而计算句子之间的相似度。
高级用法
聚类示例展示了如何使用 miCSE 模型对文本数据进行聚类分析,通过 UMAP 算法将高维的句子嵌入映射到二维空间,直观地展示聚类结果。
📚 详细文档
模型用途
miCSE 模型旨在对句子或短段落进行编码,输入文本后,模型会生成一个捕捉语义的向量嵌入。句子表示对应于 [CLS] 标记的嵌入,该嵌入可用于多种任务,如检索、句子相似度比较或聚类。
训练数据
- 全量训练数据:模型在从维基百科随机收集的英语句子上进行训练,全量训练文件可点击此处获取。
- 小样本训练数据:小样本训练数据由 SimCSE 训练语料库的不同大小(从 10% 到 0.0064%)的数据分割组成。每个分割大小包含 5 个文件,文件名后缀表示不同的随机种子。数据可点击此处下载。
模型训练
若要利用 miCSE 的小样本学习能力,需要在自己的数据上对模型进行训练。论文中使用的源代码和数据分割可点击此处获取。
🔧 技术细节
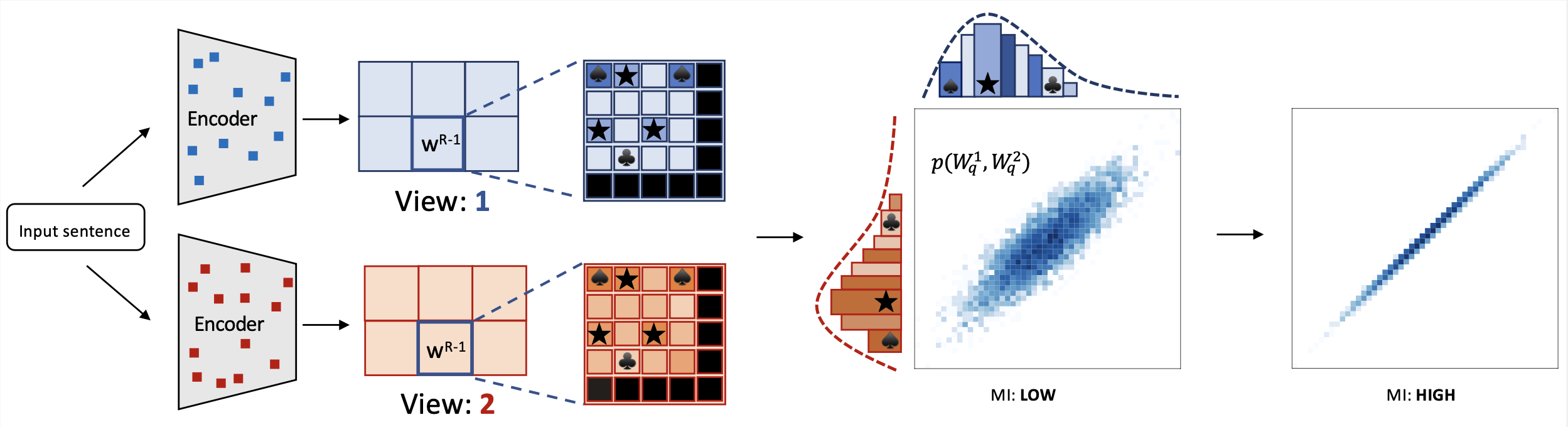 miCSE 语言模型通过在对比学习过程中对不同视图(增强嵌入)的注意力模式进行对齐训练,用于句子相似度计算。直观地说,使用 miCSE 学习句子嵌入需要在随机失活增强视图之间强制实现句法一致性。实际上,这是通过正则化自注意力分布来实现的。在训练过程中对自注意力进行正则化,使得表示学习更加高效,即使训练集规模有限,自监督学习也变得可行。这种特性使得 miCSE 在训练数据通常有限的现实应用中特别有吸引力。
miCSE 语言模型通过在对比学习过程中对不同视图(增强嵌入)的注意力模式进行对齐训练,用于句子相似度计算。直观地说,使用 miCSE 学习句子嵌入需要在随机失活增强视图之间强制实现句法一致性。实际上,这是通过正则化自注意力分布来实现的。在训练过程中对自注意力进行正则化,使得表示学习更加高效,即使训练集规模有限,自监督学习也变得可行。这种特性使得 miCSE 在训练数据通常有限的现实应用中特别有吸引力。
📄 许可证
本项目采用 Apache 2.0 许可证。
📊 基准测试
模型在 SentEval 基准测试中的结果如下:
点击展开
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | S.Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
| 71.71 | 83.09 | 75.46 | 83.13 | 80.22 | 79.70 | 73.62 | 78.13 |
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
📖 引用
如果您在研究中使用了此代码或引用我们的工作,请引用以下文献:
@inproceedings{klein-nabi-2023-micse,
title = "mi{CSE}: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings",
author = "Klein, Tassilo and
Nabi, Moin",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.339",
pages = "6159--6177",
abstract = "This paper presents miCSE, a mutual information-based contrastive learning framework that significantly advances the state-of-the-art in few-shot sentence embedding.The proposed approach imposes alignment between the attention pattern of different views during contrastive learning. Learning sentence embeddings with miCSE entails enforcing the structural consistency across augmented views for every sentence, making contrastive self-supervised learning more sample efficient. As a result, the proposed approach shows strong performance in the few-shot learning domain. While it achieves superior results compared to state-of-the-art methods on multiple benchmarks in few-shot learning, it is comparable in the full-shot scenario. This study opens up avenues for efficient self-supervised learning methods that are more robust than current contrastive methods for sentence embedding.",
}
作者
 Safetensors 英语
Safetensors 英语