%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 相互情報コントラスト型文埋め込み (miCSE) 低サンプル文埋め込み用
miCSEは、低サンプルの文埋め込みに特化した言語モデルです。コントラスト学習中に異なるビューのアテンションパターンを整列させることで、少ない学習データでも効率的に文埋め込みを学習できます。
🚀 クイックスタート
miCSEは、文や短文をエンコードするために使用されます。入力テキストを与えると、意味を捉えたベクトル埋め込みを生成します。この埋め込みは、検索、文の類似性比較、クラスタリングなどの多くのタスクに使用できます。
✨ 主な機能
- 低サンプル学習に強い:学習データが限られている場合でも、効率的に文埋め込みを学習できます。
- 構文的一貫性の強化:ドロップアウト増強ビュー間の構文的一貫性を強化することで、表現学習を向上させます。
- 多様なタスクへの対応:検索、文の類似性比較、クラスタリングなどの多くのタスクに使用できます。
📦 インストール
モデルの読み込み
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("sap-ai-research/miCSE")
model = AutoModel.from_pretrained("sap-ai-research/miCSE")
💻 使用例
基本的な使用法
# Encoding of sentences in a list with a predefined maximum lengths of tokens (max_length)
max_length = 32
sentences = [
"This is a sentence for testing miCSE.",
"This is yet another test sentence for the mutual information Contrastive Sentence Embeddings model."
]
batch = tokenizer.batch_encode_plus(
sentences,
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=True
)
# Compute the embeddings and keep only the _**[CLS]**_ embedding (the first token)
# Get raw embeddings (no gradients)
with torch.no_grad():
outputs = model(**batch, output_hidden_states=True, return_dict=True)
embeddings = outputs.last_hidden_state[:,0]
# Define similarity metric, e.g., cosine similarity
sim = nn.CosineSimilarity(dim=-1)
# Compute similarity between the **first** and the **second** sentence
cos_sim = sim(embeddings.unsqueeze(1),
embeddings.unsqueeze(0))
print(f"Distance: {cos_sim[0,1].detach().item()}")
高度な使用法
クラスタリング
from transformers import AutoTokenizer, AutoModel
import torch.nn as nn
import torch
import numpy as np
import tqdm
from datasets import load_dataset
import umap
import umap.plot as umap_plot
# Determine available hardware
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("/Users/d065243/miCSE")
model = AutoModel.from_pretrained("/Users/d065243/miCSE")
model.to(device);
# Load Twitter data for sentiment clustering
dataset = load_dataset("tweet_eval", "sentiment")
# Compute embeddings of the tweets
# set batch size and maxium tweet token length
batch_size = 50
max_length = 128
iterations = int(np.floor(len(dataset['train'])/batch_size))*batch_size
embedding_stack = []
classes = []
for i in tqdm.notebook.tqdm(range(0,iterations,batch_size)):
# create batch
batch = tokenizer.batch_encode_plus(
dataset['train'][i:i+batch_size]['text'],
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=True
).to(device)
classes = classes + dataset['train'][i:i+batch_size]['label']
# model inference without gradient
with torch.no_grad():
outputs = model(**batch, output_hidden_states=True, return_dict=True)
embeddings = outputs.last_hidden_state[:,0]
embedding_stack.append( embeddings.cpu().clone() )
embeddings = torch.vstack(embedding_stack)
# Cluster embeddings in 2D with UMAP
umap_model = umap.UMAP(n_neighbors=250,
n_components=2,
min_dist=1.0e-9,
low_memory=True,
angular_rp_forest=True,
metric='cosine')
umap_model.fit(embeddings)
# Plot result
umap_plot.points(umap_model, labels = np.array(classes),theme='fire')
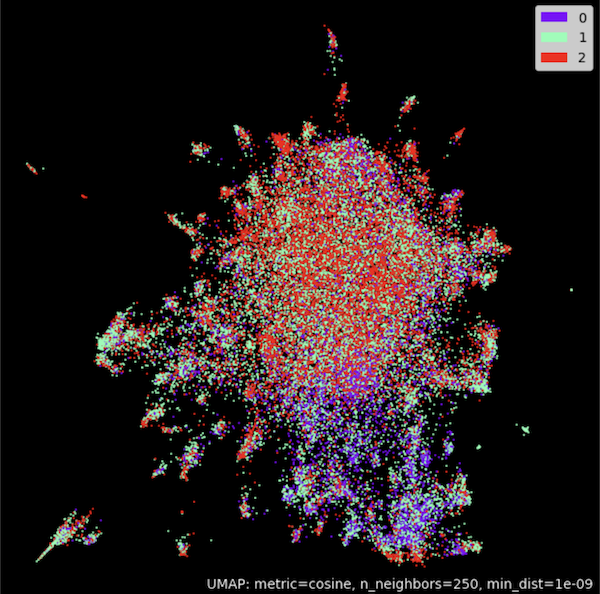
SentenceTransformersを使用する
from sentence_transformers import SentenceTransformer, util
from sentence_transformers import models
import torch.nn as nn
# Using the model with [CLS] embeddings
model_name = 'sap-ai-research/miCSE'
word_embedding_model = models.Transformer(model_name, max_seq_length=32)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Using cosine similarity as metric
cos_sim = nn.CosineSimilarity(dim=-1)
# List of sentences for comparison
sentences_1 = ["This is a sentence for testing miCSE.",
"This is using mutual information Contrastive Sentence Embeddings model."]
sentences_2 = ["This is testing miCSE.",
"Similarity with miCSE"]
# Compute embedding for both lists
embeddings_1 = model.encode(sentences_1, convert_to_tensor=True)
embeddings_2 = model.encode(sentences_2, convert_to_tensor=True)
# Compute cosine similarities
cosine_sim_scores = cos_sim(embeddings_1, embeddings_2)
#Output of results
for i in range(len(sentences1)):
print(f"Similarity {cosine_scores[i][i]:.2f}: {sentences1[i]} << vs. >> {sentences2[i]}")
📚 ドキュメント
モデルの概要
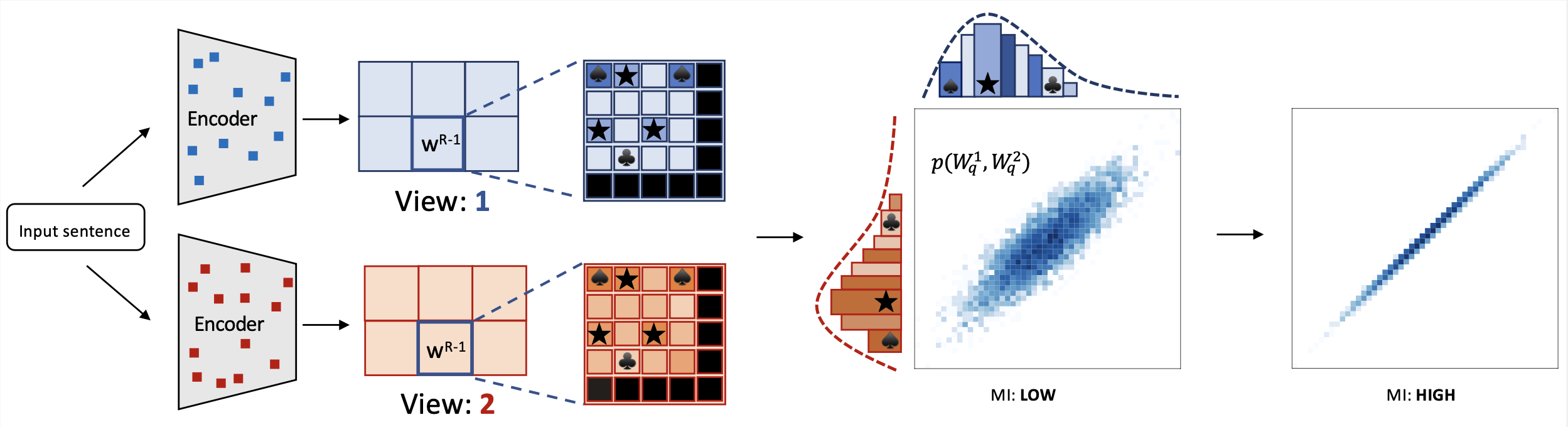 miCSE言語モデルは、文の類似性計算のために学習されています。コントラスト学習中に、異なるビュー(増強された埋め込み)のアテンションパターンを整列させることで、ドロップアウト増強ビュー間の構文的一貫性を強制します。実際には、自己アテンション分布を正則化することでこれを達成します。学習中に自己アテンションを正則化することで、表現学習がはるかにサンプル効率的になります。したがって、学習セットのサイズが限られている場合でも、自己教師付き学習が可能になります。この特性により、miCSEは学習データが通常限られている実世界のアプリケーションに特に適しています。
miCSE言語モデルは、文の類似性計算のために学習されています。コントラスト学習中に、異なるビュー(増強された埋め込み)のアテンションパターンを整列させることで、ドロップアウト増強ビュー間の構文的一貫性を強制します。実際には、自己アテンション分布を正則化することでこれを達成します。学習中に自己アテンションを正則化することで、表現学習がはるかにサンプル効率的になります。したがって、学習セットのサイズが限られている場合でも、自己教師付き学習が可能になります。この特性により、miCSEは学習データが通常限られている実世界のアプリケーションに特に適しています。
モデルのユースケース
このモデルは、文または短文をエンコードするために使用されます。入力テキストを与えると、意味を捉えたベクトル埋め込みを生成します。文の表現は、[CLS] トークンの埋め込みに対応します。この埋め込みは、検索、文の類似性比較、クラスタリングなどの多くのタスクに使用できます。
学習データ
このモデルは、Wikipediaからランダムに収集された英語の文で学習されました。フルショット 学習ファイルはこちらから入手できます。低サンプル学習データは、SimCSE学習コーパスのさまざまなサイズ(10%から0.0064%)のデータ分割で構成されています。各分割サイズには、ファイル名の接尾辞で示される異なるシードで作成された5つのファイルが含まれています。データはこちらからダウンロードできます。
モデルの学習
miCSEのフェデレーテッドラーニング機能を利用するには、モデルを独自のデータで学習する必要があります。論文で使用されたソースコードとデータ分割はこちらから入手できます。
ベンチマーク
SentEvalベンチマークでのモデルの結果:
クリックして展開
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | S.Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
| 71.71 | 83.09 | 75.46 | 83.13 | 80.22 | 79.70 | 73.62 | 78.13 |
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
🔧 技術詳細
miCSEは、相互情報に基づくコントラスト学習フレームワークであり、少ショット文埋め込みの最先端技術を大幅に進歩させます。提案されたアプローチは、コントラスト学習中に異なるビューのアテンションパターンを整列させます。miCSEを使用して文埋め込みを学習するには、各文の増強ビュー間の構造的一貫性を強制する必要があり、コントラスト自己教師付き学習をよりサンプル効率的にします。結果として、提案されたアプローチは少ショット学習ドメインで強力なパフォーマンスを示します。少ショット学習の複数のベンチマークで最先端の方法と比較して優れた結果を達成する一方で、フルショットシナリオでは同等です。この研究は、文埋め込みの現在のコントラスト方法よりも堅牢な効率的な自己教師付き学習方法の道を開きます。
📄 ライセンス
このモデルはApache 2.0ライセンスの下で提供されています。
引用
もしあなたがこのコードを研究で使用するか、私たちの研究を参照したい場合は、以下の文献を引用してください。
@inproceedings{klein-nabi-2023-micse,
title = "mi{CSE}: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings",
author = "Klein, Tassilo and
Nabi, Moin",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.339",
pages = "6159--6177",
abstract = "This paper presents miCSE, a mutual information-based contrastive learning framework that significantly advances the state-of-the-art in few-shot sentence embedding.The proposed approach imposes alignment between the attention pattern of different views during contrastive learning. Learning sentence embeddings with miCSE entails enforcing the structural consistency across augmented views for every sentence, making contrastive self-supervised learning more sample efficient. As a result, the proposed approach shows strong performance in the few-shot learning domain. While it achieves superior results compared to state-of-the-art methods on multiple benchmarks in few-shot learning, it is comparable in the full-shot scenario. This study opens up avenues for efficient self-supervised learning methods that are more robust than current contrastive methods for sentence embedding.",
}
著者
 Safetensors 英語
Safetensors 英語