%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Pythia-12B-deduped
Pythia Scaling Suite是為促進可解釋性研究而開發的一系列模型(詳見論文)。它包含兩組各八個模型,模型大小分別為70M、160M、410M、1B、1.4B、2.8B、6.9B和12B。對於每個大小的模型,都有兩個版本:一個在Pile數據集上訓練,另一個在Pile數據集進行全局去重後訓練。所有8種模型大小都在完全相同的數據上,以完全相同的順序進行訓練。我們還為每個模型提供了154箇中間檢查點,這些檢查點作為分支託管在Hugging Face上。
Pythia模型套件旨在推動大型語言模型的科學研究,特別是可解釋性研究。儘管其設計目標並非以提升下游性能為核心,但我們發現這些模型達到或超越了類似大小的模型,如OPT和GPT - Neo套件中的模型。
早期版本發佈和命名規則詳情
此前,我們向公眾發佈了Pythia套件的早期版本。然而,為了解決一些超參數差異問題,我們決定重新訓練該模型套件。本模型卡片列出了更改內容;更多評估和實現細節請參考論文。我們發現兩個版本的Pythia模型在基準測試性能上沒有差異。舊版本模型仍然可用,但如果您剛開始使用Pythia,建議使用重新訓練後的套件。
請注意,Pythia套件中的所有模型在2023年1月進行了重命名。為清晰起見,本模型卡片提供了一個新舊名稱對比表,以及確切的參數數量。
🚀 快速開始
Pythia模型可以通過以下代碼加載和使用,以下是pythia - 70m - deduped第三個檢查點的示例:
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
分支143000與每個模型main分支上的模型檢查點完全對應。更多關於如何使用所有Pythia模型的信息,請參考GitHub上的文檔。
✨ 主要特性
- 促進研究:Pythia Scaling Suite專為促進大型語言模型的可解釋性研究而開發,提供了一個可控的環境來進行科學實驗。
- 多種模型大小:包含兩組各八個不同大小的模型(70M、160M、410M、1B、1.4B、2.8B、6.9B和12B),且每個大小都有在原始Pile數據集和去重後Pile數據集上訓練的版本。
- 豐富的檢查點:每個模型提供154個檢查點,包括初始
step0、10個對數間隔的檢查點step{1,2,4...512}以及143個從step1000到step143000均勻間隔的檢查點,這些檢查點託管在Hugging Face上。 - 性能表現:儘管設計目標並非以提升下游性能為核心,但模型在性能上達到或超越了類似大小的模型,如OPT和GPT - Neo套件中的模型。
📦 安裝指南
文檔中未提及具體安裝步驟,故跳過此章節。
💻 使用示例
基礎用法
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
高級用法
文檔中未提及高級用法示例,故跳過此部分。
📚 詳細文檔
模型詳情
- 開發者:EleutherAI
- 模型類型:基於Transformer的語言模型
- 語言:英語
- 更多信息:有關訓練過程、配置文件和使用細節,請參考Pythia的GitHub倉庫。更多評估和實現細節請參考論文。
- 庫:[GPT - NeoX](https://github.com/EleutherAI/gpt - neox)
- 許可證:Apache 2.0
- 聯繫方式:若要詢問關於此模型的問題,請加入EleutherAI Discord,並在
#release - discussion中發佈問題。在EleutherAI Discord詢問之前,請先閱讀現有的Pythia文檔。如需一般通信,請發送郵件至contact@eleuther.ai。
| 屬性 | 詳情 |
|---|---|
| 模型類型 | 基於Transformer的語言模型 |
| 訓練數據 | 經過全局去重後的Pile數據集 |
| 語言 | 英語 |
| 開發者 | EleutherAI |
| 庫 | GPT - NeoX |
| 許可證 | Apache 2.0 |
| Pythia模型 | 非嵌入參數 | 層數 | 模型維度 | 頭數 | 批次大小 | 學習率 | 等效模型 |
|---|---|---|---|---|---|---|---|
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10-3 | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10-4 | GPT - Neo 125M, OPT - 125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10-4 | OPT - 350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10-4 | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10-4 | GPT - Neo 1.3B, OPT - 1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10-4 | GPT - Neo 2.7B, OPT - 2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10-4 | OPT - 6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10-4 | — |
使用和限制
預期用途
Pythia的主要預期用途是對大型語言模型的行為、功能和侷限性進行研究。該套件旨在為進行科學實驗提供一個可控的環境。每個模型還提供154個檢查點:初始step0、10個對數間隔的檢查點step{1,2,4...512}以及143個從step1000到step143000均勻間隔的檢查點,這些檢查點託管在Hugging Face上。請注意,分支143000與每個模型main分支上的模型檢查點完全對應。
只要您的使用符合Apache 2.0許可證,您也可以對Pythia - 12B - deduped進行進一步的微調並用於部署。Pythia模型可與Hugging Face的Transformers庫配合使用。如果您決定使用預訓練的Pythia - 12B - deduped作為微調模型的基礎,請自行進行風險和偏差評估。
非預期用途
Pythia套件不適合用於部署。它本身不是一個產品,不能用於面向人類的交互。例如,該模型可能會生成有害或冒犯性的文本。請評估與您特定用例相關的風險。
Pythia模型僅支持英語,不適合用於翻譯或生成其他語言的文本。
Pythia - 12B - deduped未針對語言模型常見的下游場景進行微調,如撰寫特定類型的散文或商業聊天機器人。這意味著Pythia - 12B - deduped不會像ChatGPT這樣的產品那樣對給定的提示做出響應。這是因為與該模型不同,ChatGPT使用瞭如基於人類反饋的強化學習(RLHF)等方法進行微調,以更好地“遵循”人類指令。
侷限性和偏差
大型語言模型的核心功能是接收一段文本並預測下一個標記。模型使用的標記不一定能產生最“準確”的文本。切勿依賴Pythia - 12B - deduped生成事實準確的輸出。
該模型在Pile數據集上進行訓練,該數據集已知包含褻瀆性和低俗或冒犯性的文本。有關性別、宗教和種族方面的記錄偏差討論,請參考Pile論文的第6節。即使提示本身不包含任何明確的冒犯性內容,Pythia - 12B - deduped也可能會生成社會不可接受或不良的文本。
如果您計劃使用通過例如託管推理API生成的文本,建議在向他人展示之前由人工對該語言模型的輸出進行審核。請告知您的受眾該文本是由Pythia - 12B - deduped生成的。
訓練
訓練數據
Pythia - 12B - deduped在經過全局去重後的Pile數據集上進行訓練。
Pile數據集是一個825GiB的通用英語數據集,由EleutherAI專門為訓練大型語言模型而創建。它包含來自22個不同來源的文本,大致分為五類:學術寫作(如arXiv)、互聯網(如CommonCrawl)、散文(如Project Gutenberg)、對話(如YouTube字幕)和其他(如GitHub、Enron Emails)。有關所有數據源的細分、方法和倫理影響的討論,請參考Pile論文。有關Pile及其組成數據集的更詳細文檔,請參考數據表。Pile數據集可以從官方網站或[社區鏡像](https://the - eye.eu/public/AI/pile/)下載。
訓練過程
所有模型都在完全相同的數據上,以完全相同的順序進行訓練。每個模型在訓練期間處理了299,892,736,000個標記,並且每個模型每2,097,152,000個標記保存143個檢查點,這些檢查點在訓練過程中均勻分佈,從step1000到step143000(與main相同)。此外,我們還提供了頻繁的早期檢查點:step0和step{1,2,4...512}。這相當於未去重模型在Pile數據集上訓練不到1個週期,而去重後的Pile數據集上訓練約1.5個週期。
所有Pythia模型以2M(2,097,152個標記)的批次大小訓練了143000步。有關訓練過程的更多詳細信息,包括[如何復現](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing - training),請參考GitHub。Pythia使用與[GPT - NeoX - 20B](https://huggingface.co/EleutherAI/gpt - neox - 20b)相同的分詞器。
評估
所有16個Pythia模型都使用[LM Evaluation Harness](https://github.com/EleutherAI/lm - evaluation - harness)進行了評估。您可以在GitHub倉庫的results/json/*中按模型和步驟訪問評估結果。
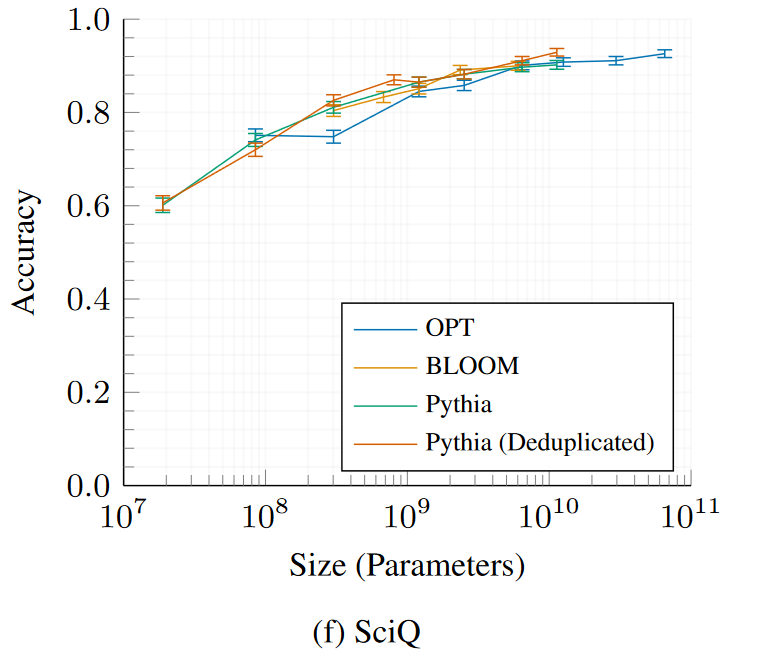
展開以下部分,查看所有Pythia和Pythia - deduped模型與OPT和BLOOM的評估結果對比圖。
LAMBADA – OpenAI
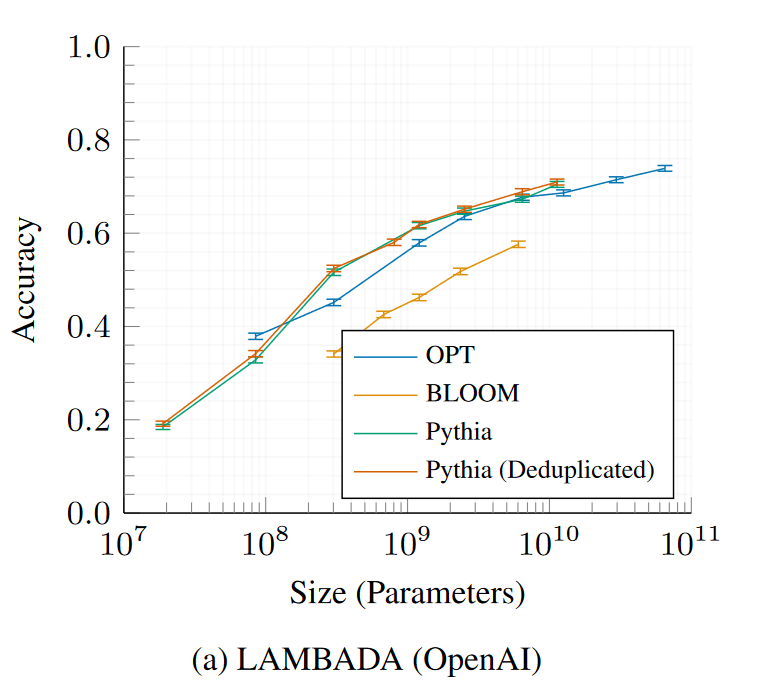
物理交互:問答(PIQA)
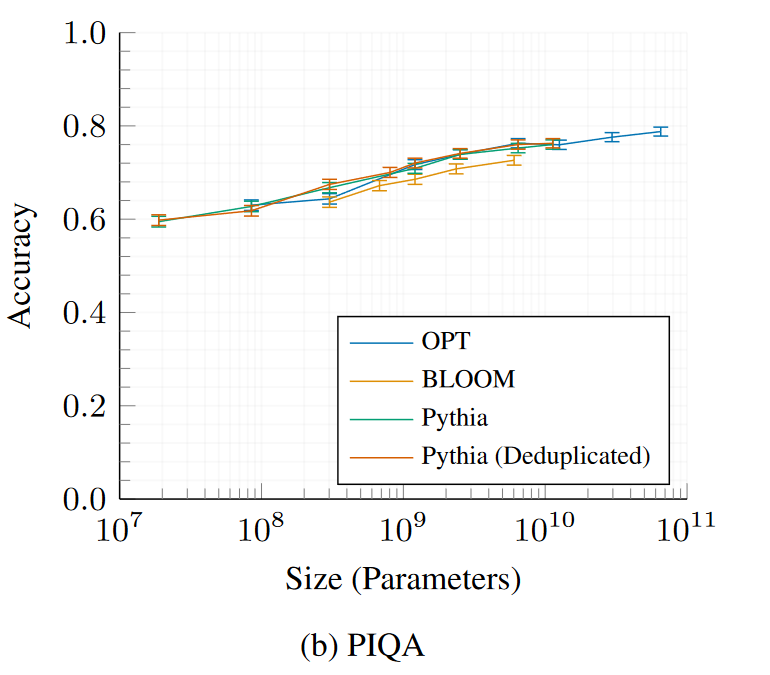
WinoGrande
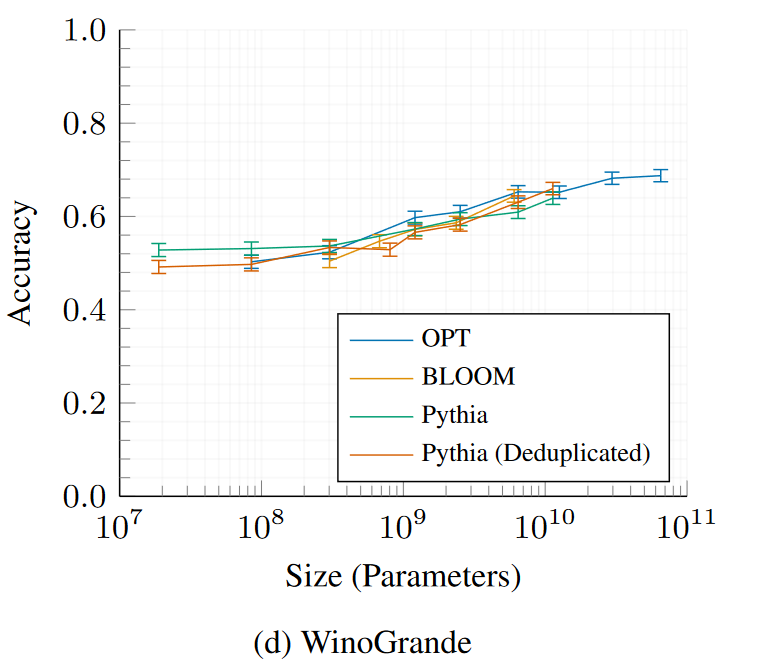
AI2推理挑戰—簡單集
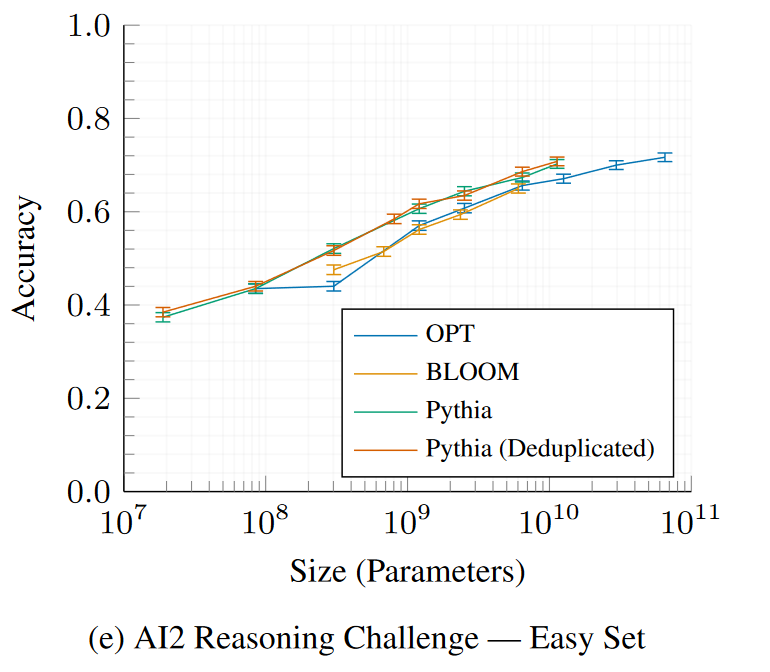
SciQ
變更日誌
本節比較了之前發佈的Pythia v0與當前模型之間的差異。有關這些更改及其背後動機的更多討論,請參考Pythia論文的附錄B。我們發現重新訓練Pythia對基準測試性能沒有影響。
- 批次大小統一:所有模型現在都以2M標記的統一批次大小進行訓練。此前,參數大小為160M、410M和1.4B的模型以4M標記的批次大小進行訓練。
- 增加檢查點:除了每1000個訓練步驟保存檢查點外,我們還在初始化(step 0)和步驟{1,2,4,8,16,32,64,128,256,512}增加了檢查點。
- 使用Flash Attention:新的重新訓練套件中使用了Flash Attention。
- 學習率調度統一:我們糾正了原始套件中存在的一個小不一致問題:所有2.8B參數或更小的模型的學習率(LR)調度衰減到起始LR的10%作為最小LR,但6.9B和12B模型使用的LR調度衰減到最小LR為0。在重新訓練過程中,我們糾正了這一不一致性:所有模型現在都以LR衰減到最大LR的0.1倍作為最小值進行訓練。
命名規則和參數數量
Pythia模型在2023年1月進行了重命名。舊的命名規則可能仍會意外地出現在某些文檔中。當前的命名規則(70M、160M等)基於總參數數量。
| 當前Pythia後綴 | 舊後綴 | 總參數 | 非嵌入參數 |
|---|---|---|---|
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
🔧 技術細節
文檔中未提及足夠詳細的技術實現細節,故跳過此章節。
📄 許可證
本模型使用的許可證為Apache 2.0。