🚀 Pythia-12B-deduped
Pythia Scaling Suiteは、解釈可能性の研究を促進するために開発されたモデルのコレクションです(論文を参照)。このコレクションには、それぞれ70M、160M、410M、1B、1.4B、2.8B、6.9B、および12Bのサイズのモデルが2セット含まれています。各サイズには、Pileデータセットで訓練されたモデルと、グローバルに重複排除されたPileデータセットで訓練されたモデルの2つがあります。すべての8つのモデルサイズは、まったく同じデータをまったく同じ順序で使用して訓練されています。また、各モデルについて154の中間チェックポイントを提供しており、これらはHugging Face上のブランチとしてホストされています。
Pythiaモデルスイートは、大規模言語モデルに関する科学的研究、特に解釈可能性の研究を促進することを目的として設計されています。下流のパフォーマンスを設計目標として中心に置いていないにもかかわらず、これらのモデルは同等のサイズのモデル(OPTやGPT - Neoスイートなど)と同等またはそれ以上のパフォーマンスを示すことがわかっています。
以前の早期リリースと命名規則の詳細
以前、我々はPythiaスイートの早期バージョンを公開しました。しかし、いくつかのハイパーパラメータの不一致を解消するために、モデルスイートを再訓練することにしました。このモデルカードには変更点が記載されています。詳細な議論については、Pythia論文の付録Bを参照してください。2つのPythiaバージョンのベンチマークパフォーマンスには差異がないことがわかりました。古いモデルは依然として利用可能ですが、Pythiaを初めて使用する場合は、再訓練されたスイートをお勧めします。
これが現在のリリースです。
2023年1月に、Pythiaモデルの名称が変更されました。誤って古い命名規則が一部のドキュメントに残っている可能性があります。現在の命名規則(70M、160Mなど)は、総パラメータ数に基づいています。このモデルカードには、古い名前と新しい名前を比較した表が、正確なパラメータ数とともに提供されています。
🚀 クイックスタート
Pythiaモデルは、以下のコードを使用してロードし、使用することができます。ここでは、3番目のpythia - 70m - dedupedチェックポイントの例を示します。
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
リビジョン/ブランチstep143000は、各モデルのmainブランチ上のモデルチェックポイントに正確に対応しています。
すべてのPythiaモデルの使用方法の詳細については、GitHubのドキュメントを参照してください。
✨ 主な機能
- 研究用セット:大規模言語モデルの挙動、機能、制限に関する研究に最適。
- 多数のチェックポイント:各モデルに154のチェックポイントを提供し、研究の柔軟性を高める。
- パフォーマンス:同等のサイズのモデルと同等またはそれ以上のパフォーマンスを示す。
📚 ドキュメント
モデルの詳細
- 開発者:EleutherAI
- モデルタイプ:Transformerベースの言語モデル
- 言語:英語
- 詳細情報:訓練手順、設定ファイル、および使用方法の詳細については、PythiaのGitHubリポジトリを参照してください。より多くの評価と実装の詳細については、論文を参照してください。
- ライブラリ:[GPT - NeoX](https://github.com/EleutherAI/gpt - neox)
- ライセンス:Apache 2.0
- 問い合わせ:このモデルに関する質問をするには、EleutherAI Discordに参加し、
#release - discussionに投稿してください。EleutherAI Discordで質問する前に、既存のPythiaドキュメントを読んでください。一般的な問い合わせについては、contact@eleuther.aiまで。
| Pythiaモデル |
非埋め込みパラメータ |
レイヤー |
モデル次元 |
ヘッド |
バッチサイズ |
学習率 |
同等のモデル |
| 70M |
18,915,328 |
6 |
512 |
8 |
2M |
1.0 x 10-3 |
— |
| 160M |
85,056,000 |
12 |
768 |
12 |
2M |
6.0 x 10-4 |
GPT - Neo 125M, OPT - 125M |
| 410M |
302,311,424 |
24 |
1024 |
16 |
2M |
3.0 x 10-4 |
OPT - 350M |
| 1.0B |
805,736,448 |
16 |
2048 |
8 |
2M |
3.0 x 10-4 |
— |
| 1.4B |
1,208,602,624 |
24 |
2048 |
16 |
2M |
2.0 x 10-4 |
GPT - Neo 1.3B, OPT - 1.3B |
| 2.8B |
2,517,652,480 |
32 |
2560 |
32 |
2M |
1.6 x 10-4 |
GPT - Neo 2.7B, OPT - 2.7B |
| 6.9B |
6,444,163,072 |
32 |
4096 |
32 |
2M |
1.2 x 10-4 |
OPT - 6.7B |
| 12B |
11,327,027,200 |
36 |
5120 |
40 |
2M |
1.2 x 10-4 |
— |
Pythiaスイートのエンジニアリング詳細。指定されたサイズの重複排除されたモデルと重複排除されていないモデルは、同じハイパーパラメータを持ちます。「同等の」モデルは、まったく同じアーキテクチャと同じ数の非埋め込みパラメータを持ちます。
使用方法と制限
意図された使用法
Pythiaの主な使用目的は、大規模言語モデルの挙動、機能、および制限に関する研究です。このスイートは、科学的実験を行うためのコントロールされた環境を提供することを目的としています。また、各モデルについて154のチェックポイントを提供しています:初期のstep0、10の対数間隔のチェックポイントstep{1,2,4...512}、およびstep1000からstep143000までの143の均等間隔のチェックポイント。これらのチェックポイントは、Hugging Face上のブランチとしてホストされています。ブランチ143000は、各モデルのmainブランチ上のモデルチェックポイントに正確に対応しています。
また、Pythia - 12B - dedupedをさらにファインチューニングし、デプロイに適用することもできますが、使用はApache 2.0ライセンスに準拠する必要があります。Pythiaモデルは、Hugging FaceのTransformersライブラリと互換性があります。事前訓練されたPythia - 12B - dedupedをファインチューニングモデルの基礎として使用することを決めた場合は、独自のリスクとバイアス評価を行ってください。
想定外の使用法
Pythiaスイートはデプロイを目的としていません。それ自体が製品ではなく、人との対話には使用できません。たとえば、モデルは有害または不快なテキストを生成する可能性があります。特定のユースケースに関連するリスクを評価してください。
Pythiaモデルは英語のみに対応しており、翻訳や他の言語のテキスト生成には適していません。
Pythia - 12B - dedupedは、言語モデルが一般的にデプロイされる下流のコンテキスト(ジャンルの散文の執筆や商用チャットボットなど)に対してファインチューニングされていません。これは、Pythia - 12B - dedupedが、ChatGPTのような製品のように与えられたプロンプトに応答しないことを意味します。これは、ChatGPTは人間のフィードバックによる強化学習(RLHF)などの方法を使用してファインチューニングされ、人間の指示をよりよく「従う」ようになっているのに対し、このモデルはそのようなファインチューニングが行われていないためです。
制限とバイアス
大規模言語モデルの核心機能は、テキスト文字列を受け取り、次のトークンを予測することです。モデルが使用するトークンは、最も「正確な」テキストを生成する必要はありません。Pythia - 12B - dedupedが事実上正確な出力を生成することに決して依存しないでください。
このモデルは、the Pileという、不適切な言葉や露骨または不快なテキストを含むことが知られているデータセットで訓練されています。性別、宗教、人種に関する文書化されたバイアスについての議論は、the Pile論文のセクション6を参照してください。Pythia - 12B - dedupedは、プロンプト自体に明示的に不快な内容が含まれていなくても、社会的に受け入れられないまたは望ましくないテキストを生成する可能性があります。
たとえば、Hosted Inference APIを介して生成されたテキストを使用する予定の場合は、この言語モデルの出力を他の人に提示する前に、人間による検閲を行うことをお勧めします。テキストがPythia - 12B - dedupedによって生成されたことを聴衆に知らせてください。
訓練
訓練データ
Pythia - 12B - dedupedは、データセットがグローバルに重複排除された後のPileで訓練されました。
The Pileは、825GiBの英語の汎用データセットです。EleutherAIによって大規模言語モデルの訓練用に特別に作成されました。このデータセットには、22の多様なソースからのテキストが含まれており、大まかに5つのカテゴリに分けられます:学術文献(例:arXiv)、インターネット(例:CommonCrawl)、散文(例:Project Gutenberg)、対話(例:YouTube字幕)、およびその他(例:GitHub、Enron Emails)。すべてのデータソース、方法論、および倫理的な影響に関する議論については、the Pile論文を参照してください。The Pileおよびその構成データセットに関するより詳細なドキュメントについては、データシートを参照してください。The Pileは、公式ウェブサイトまたは[コミュニティミラー](https://the - eye.eu/public/AI/pile/)からダウンロードできます。
訓練手順
すべてのモデルは、まったく同じデータをまったく同じ順序で使用して訓練されました。各モデルは訓練中に299,892,736,000トークンを見ており、各モデルについて143のチェックポイントが2,097,152,000トークンごとに保存され、訓練全体を通じて均等に間隔を空けて、step1000からstep143000(mainと同じ)まで保存されます。さらに、頻繁な初期チェックポイントも提供しています:step0とstep{1,2,4...512}。これは、重複排除されていないモデルについてはPile上で1エポック弱の訓練に相当し、重複排除されたPileについては約1.5エポックの訓練に相当します。
すべてのPythiaモデルは、バッチサイズ2M(2,097,152トークン)で143000ステップ訓練されました。
訓練手順の詳細([再現方法](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing - training)を含む)については、GitHubを参照してください。
Pythiaは、[GPT - NeoX - 20B](https://huggingface.co/EleutherAI/gpt - neox - 20b)と同じトークナイザーを使用しています。
評価
すべての16のPythiaモデルは、[LM Evaluation Harness](https://github.com/EleutherAI/lm - evaluation - harness)を使用して評価されました。モデルとステップごとの結果にアクセスするには、GitHubリポジトリのresults/json/*を参照してください。
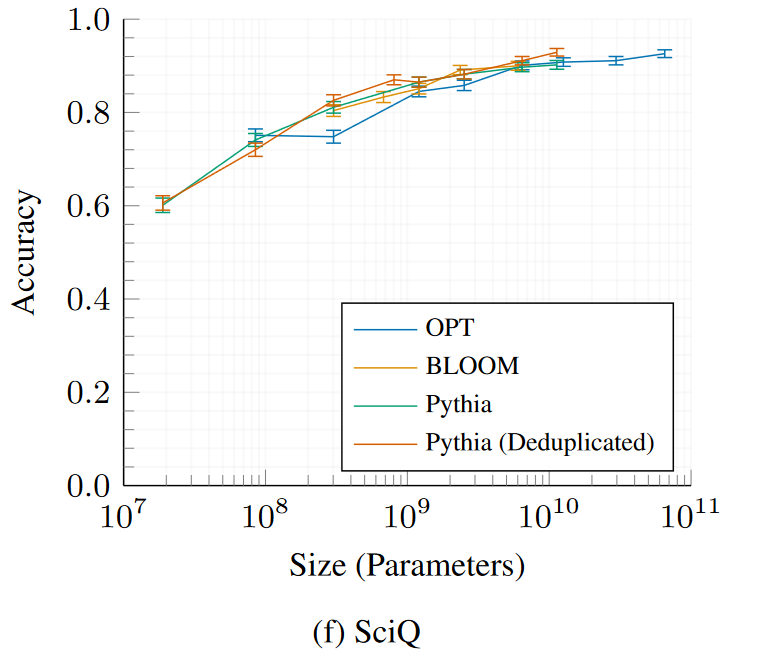
以下のセクションを展開すると、すべてのPythiaおよびPythia - dedupedモデルの評価結果のプロットを、OPTおよびBLOOMと比較して確認できます。
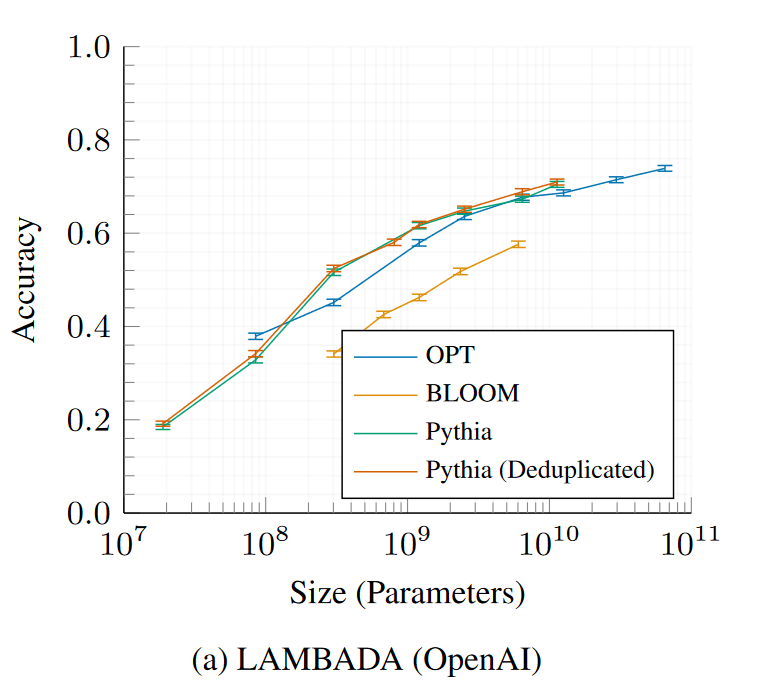
LAMBADA – OpenAI
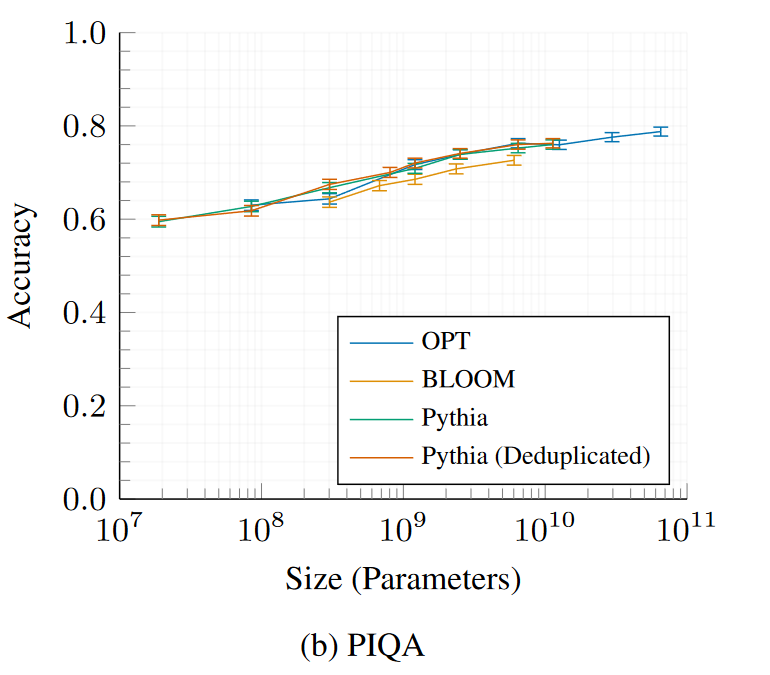
Physical Interaction: Question Answering (PIQA)
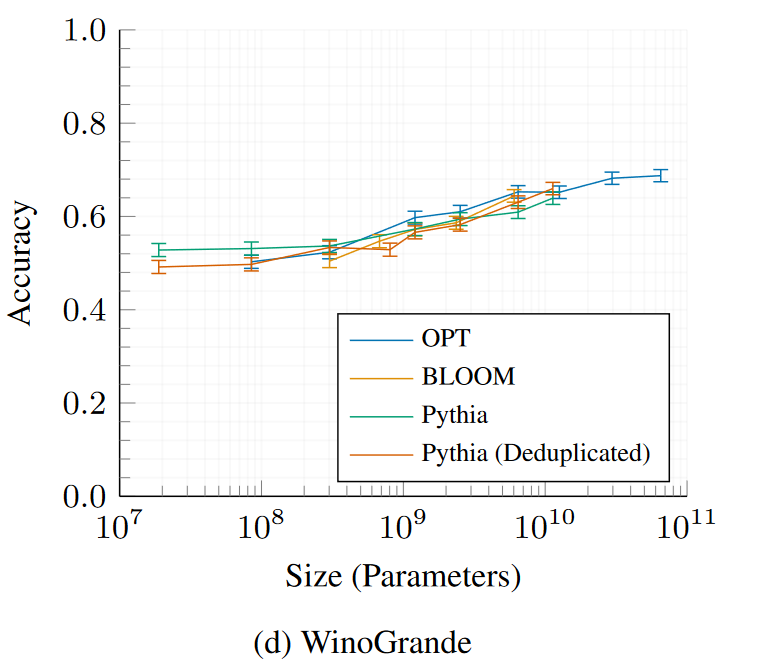
WinoGrande
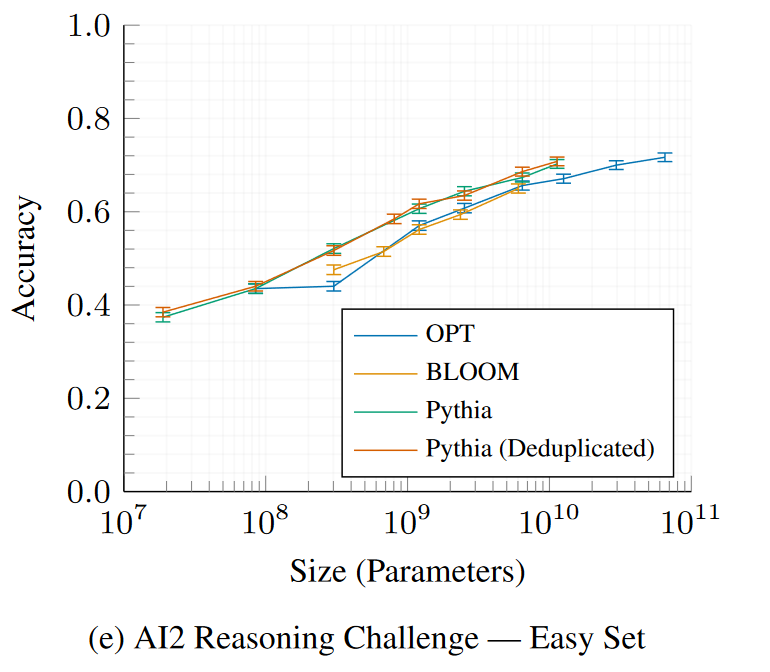
AI2 Reasoning Challenge—Easy Set
SciQ
変更履歴
このセクションでは、以前にリリースされたPythia v0と現在のモデルの違いを比較しています。これらの変更とその背景についての詳細な議論については、Pythia論文の付録Bを参照してください。Pythiaを再訓練してもベンチマークパフォーマンスに影響がないことがわかりました。
- すべてのモデルサイズが、均一なバッチサイズ2Mトークンで訓練されるようになりました。以前は、160M、410M、および1.4Bパラメータのモデルは、バッチサイズ4Mトークンで訓練されていました。
- 初期化時(ステップ0)とステップ{1,2,4,8,16,32,64,128,256,512}にチェックポイントを追加し、さらに1000トレーニングステップごとにチェックポイントを追加しました。
- 新しく再訓練されたスイートでは、Flash Attentionが使用されました。
- 元のスイートに存在していたわずかな不一致を修正しました:2.8Bパラメータ以下のすべてのモデルは、学習率(LR)スケジュールが最小LRまで減衰し、最小LRは開始LRの10%でしたが、6.9Bおよび12Bモデルはすべて、最小LRが0まで減衰するLRスケジュールを使用していました。再訓練ランでは、この不一致を修正しました:すべてのモデルが現在、最大LRの0.1倍まで減衰するLRで訓練されています。
命名規則とパラメータ数
Pythiaモデルは2023年1月に名称が変更されました。誤って古い命名規則が一部のドキュメントに残っている可能性があります。現在の命名規則(70M、160Mなど)は、総パラメータ数に基づいています。
| 現在のPythiaサフィックス |
古いサフィックス |
総パラメータ |
非埋め込みパラメータ |
| 70M |
19M |
70,426,624 |
18,915,328 |
| 160M |
125M |
162,322,944 |
85,056,000 |
| 410M |
350M |
405,334,016 |
302,311,424 |
| 1B |
800M |
1,011,781,632 |
805,736,448 |
| 1.4B |
1.3B |
1,414,647,808 |
1,208,602,624 |
| 2.8B |
2.7B |
2,775,208,960 |
2,517,652,480 |
| 6.9B |
6.7B |
6,857,302,016 |
6,444,163,072 |
| 12B |
13B |
11,846,072,320 |
11,327,027,200 |
📄 ライセンス
このモデルはApache 2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応