🚀 Aero-1-Audio
Aero-1-Audio 是一款輕量級音頻模型,擅長處理各類音頻任務,包括語音識別、音頻理解以及遵循音頻指令。它基於 Qwen-2.5-1.5B 語言模型構建,在多個音頻基準測試中表現出色,且參數效率高,即便與 Whisper、Qwen-2-Audio 和 Phi-4-Multimodal 等大型先進模型,或 ElevenLabs/Scribe 等商業服務相比也不遜色。此外,該模型僅使用 50k 小時的音頻數據,在 16 個 H100 GPU 上僅用一天時間就完成了訓練,這表明使用高質量且經過篩選的數據進行音頻模型訓練可以實現高效採樣。同時,它能夠對長達 15 分鐘的連續音頻輸入進行準確的自動語音識別(ASR)和音頻理解,而這一場景對其他模型來說仍是一項挑戰。
- 開發者: [LMMs-Lab]
- 模型類型: [大語言模型(LLM)+ 音頻編碼器]
- 支持語言(自然語言處理): [英語]
- 許可證: [MIT]
🚀 快速開始
使用以下代碼開始使用該模型。建議你通過以下命令安裝 transformers:
python3 -m pip install transformers@git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
這是我們構建此模型時所使用的 transformers 版本。
💻 使用示例
基礎用法
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
audios = [load_audio()]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True)[0])
高級用法
該模型支持使用 transformers 進行批量推理。示例代碼如下:
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
def load_audio_2():
return librosa.load(librosa.ex("libri2"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
messages = [messages, messages]
audios = [load_audio(), load_audio_2()]
processor.tokenizer.padding_side="left"
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt", padding=True)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, pad_token_id=151643, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True))
📚 詳細文檔
訓練數據
我們在此展示了數據混合的貢獻。我們的監督微調(SFT)數據混合包含 20 多個公開可用的數據集,與其他模型的比較凸顯了這些數據的輕量級特性。
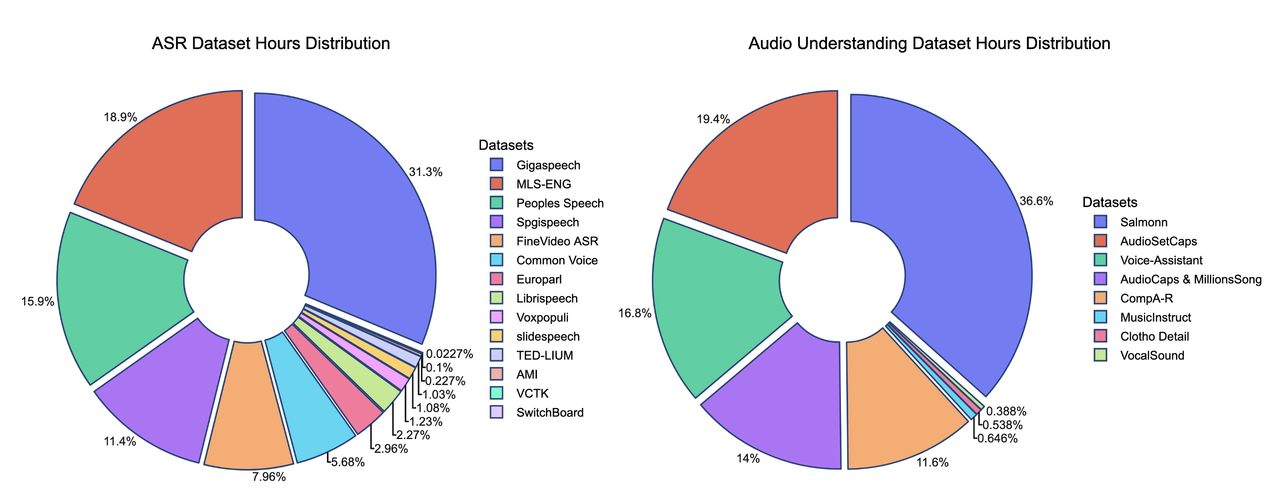
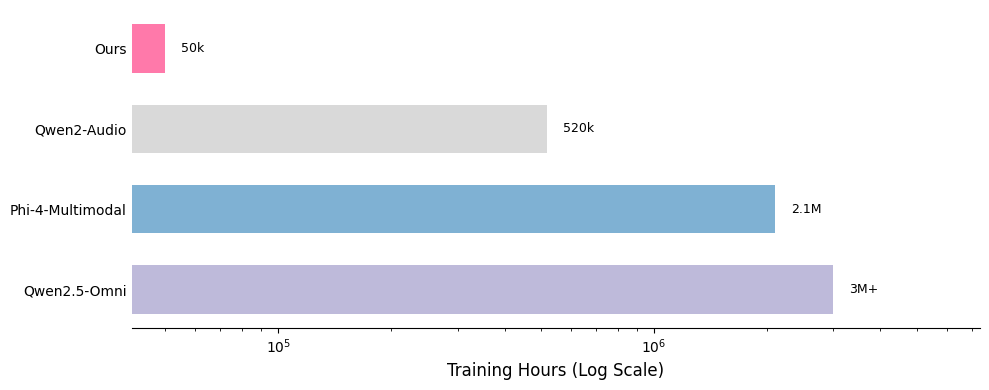
*部分訓練數據集的時長是估算值,可能不完全準確
我們訓練方法的關鍵優勢之一在於數據的質量和數量。我們的訓練數據集約由 50 億個標記組成,相當於約 50,000 小時的音頻。與 Qwen-Omni 和 Phi-4 等模型相比,我們的數據集小了 100 多倍,但我們的模型仍能取得有競爭力的性能。所有數據均來自公開可用的開源數據集,這凸顯了我們訓練方法的樣本效率。以下是我們數據分佈的詳細細分,以及與其他模型的比較。
📄 許可證
本項目採用 MIT 許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言