🚀 Aero-1-Audio
Aero-1-Audioは、音声認識、音声理解、音声指示の実行など、様々な音声タスクに対応したコンパクトな音声モデルです。
- Qwen-2.5-1.5B言語モデルをベースに構築されており、WhisperやQwen-2-Audio、Phi-4-Multimodalなどの大規模な高度なモデルや、ElevenLabs/Scribeなどの商用サービスと比較しても、パラメータ効率が高く、複数の音声ベンチマークで強力な性能を発揮します。
- Aeroは、16台のH100 GPUでたった1日間、たった50,000時間の音声データを使用して学習されまし。このことから、高品質でフィルタリングされたデータを使用することで、音声モデルの学習をサンプル効率の高いものにできることが示唆されます。
- Aeroは、最大15分の連続音声入力に対して、ASRと音声理解を正確に実行できます。このシナリオは、他のモデルにとって依然として課題となっています。
- 開発者: [LMMs-Lab]
- モデルタイプ: [LLM + 音声エンコーダ]
- 言語 (NLP): [英語]
- ライセンス: [MIT]
🚀 クイックスタート
以下のコードを使用して、モデルを使い始めましょう。
このモデルを構築する際に使用したtransformersのバージョンを使用することをおすすめします。
python3 -m pip install transformers@git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
💻 使用例
基本的な使用法
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
audios = [load_audio()]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True)[0])
高度な使用法
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
def load_audio_2():
return librosa.load(librosa.ex("libri2"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
messages = [messages, messages]
audios = [load_audio(), load_audio_2()]
processor.tokenizer.padding_side="left"
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt", padding=True)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, pad_token_id=151643, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True))
📚 ドキュメント
学習データ
ここでは、データミックスの貢献を紹介します。SFTデータミックスには、20以上の公開データセットが含まれており、他のモデルとの比較から、このデータの軽量性が明らかになっています。
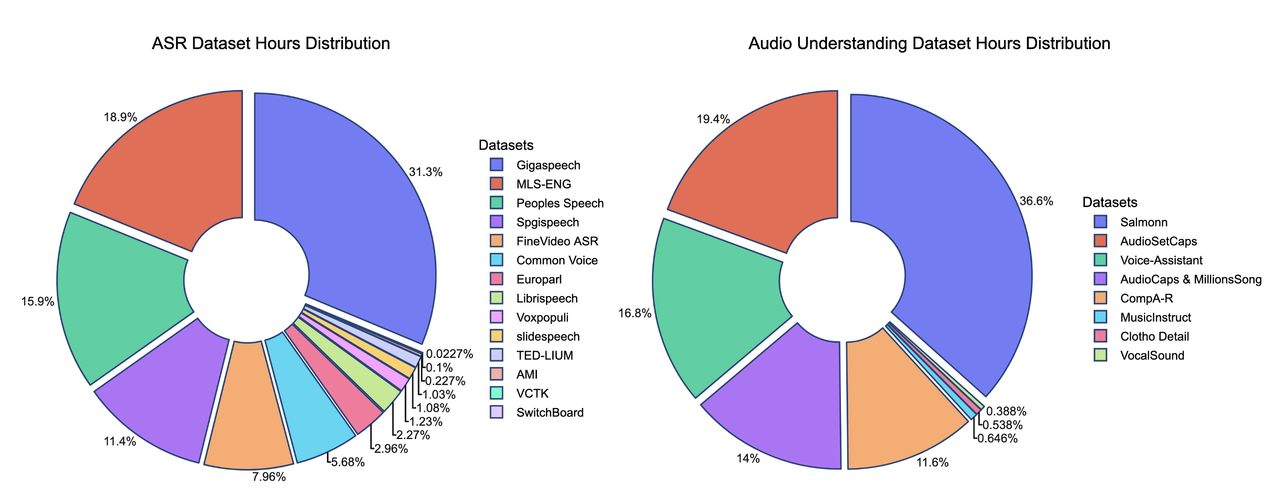
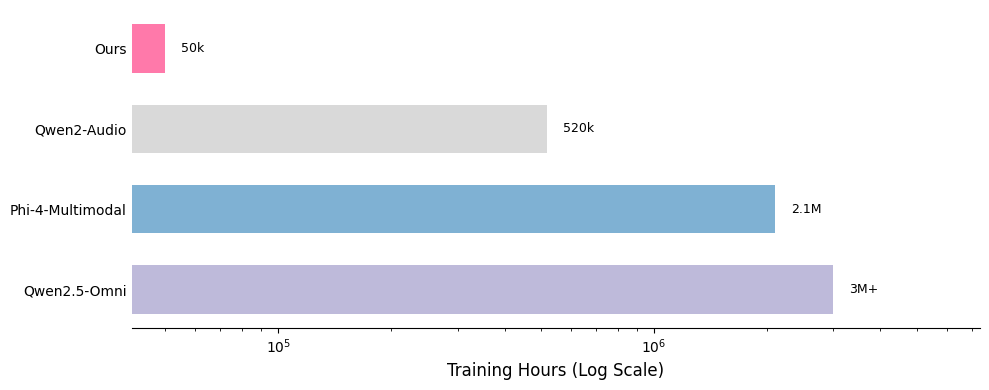
*一部の学習データセットの時間は推定値であり、完全に正確ではない場合があります。
学習方法の重要な強みの1つは、データの品質と量にあります。学習データセットは約50億トークンで、約50,000時間の音声に相当します。Qwen-OmniやPhi-4などのモデルと比較すると、データセットは100倍以上小さいにもかかわらず、このモデルは競争力のある性能を達成しています。すべてのデータは公開されているオープンソースのデータセットから取得されており、学習アプローチのサンプル効率を示しています。以下に、データ分布の詳細な内訳と、他のモデルとの比較を示します。
📄 ライセンス
このモデルはMITライセンスの下で公開されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応