🚀 ChatTCM-7B-SFT模型介紹
ChatTCM-7B-SFT是一個基於中醫領域的文本生成模型,通過全參數量有監督微調,使模型在中醫知識處理、臨床診斷等方面具備了強大的能力,有助於中醫典籍的理解與臨床實踐的應用。
📦 模型信息
| 屬性 |
詳情 |
| 模型類型 |
文本生成 |
| 基礎模型 |
SylvanL/ChatTCM-7B-Pretrain |
| 訓練數據 |
SylvanL/Traditional-Chinese-Medicine-Dataset-SFT |
| 許可證 |
apache-2.0 |
🚀 快速開始
模型微調情況
在2張A800 - 80G上,基於SylvanL/ChatTCM-7B-Pretrain,在llamafactory框架上,使用SylvanL/Traditional-Chinese-Medicine-Dataset-SFT進行了1個epoch的全參數量有監督微調(full Supervised Fine - tuning)。
微調後模型能力
在不出現明顯指令丟失或災難性遺忘的前提下,模型具備以下能力:
- 文言文翻譯能力:具有將文言文/古文翻譯為現代文的能力,以加強對於中醫典籍的理解與使用。
- 臨床診斷與推方能力:具有向主流派別執業醫生靠攏的臨床診斷邏輯與推方能力,可以理解輸入的患者情況並進行判斷與分析。
- 中醫知識問答能力:具有良好的中醫知識問答能力,可以針對中醫領域的知識點進行全面且可靠的解答。
- 中醫術語NLP能力:加強模型面向中醫術語的基礎nlp能力,可以更好的賦能如中醫命名實體識別、關係抽取、關聯性分析、同義實體消岐、拼寫檢查與糾錯等通用功能。
注意:模型並沒有進行任何identify的植入。
💻 使用示例
可選Instruction
將輸入的古文翻譯成現代文。
請為輸入的現代文找到其對應的古文原文與出處。
基於輸入的患者醫案記錄,直接給出你的證型診斷,無需給出原因。
基於輸入的患者醫案記錄,直接給出你的疾病診斷,無需給出原因。
基於輸入的患者醫案記錄,直接給出你認為的方劑中藥組成。
基於輸入的患者醫案記錄,直接給出你認為的【治療方案】{可多選}∈["中藥", "成藥", "方劑"],和【診斷】{可多選}∈["證型", "治法", "西醫診斷", "中醫診斷"]:
第一個epoch訓練數據
epoch 1:
"num_input_tokens_seen": 1649269888,
"total_flos": 3298213988794368.0,
"train_loss": 1.0691444667014194,
"train_runtime": 587389.2072,
"train_samples_per_second": 3.483,
"train_steps_per_second": 0.016
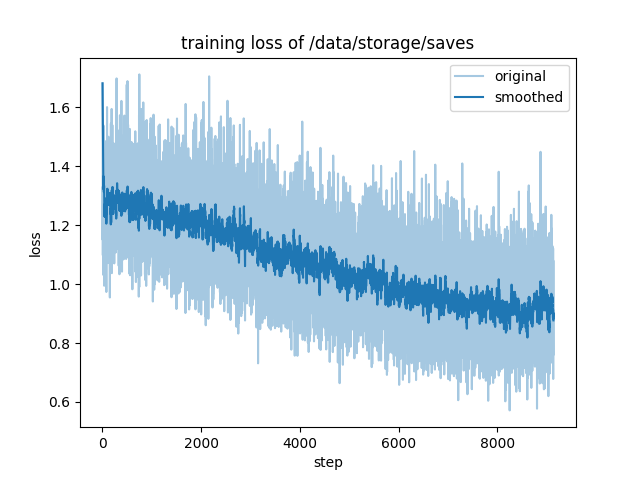
第一個epoch訓練損失圖
訓練命令示例
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path {SylvanL/ChatTCM-7B-Pretrain} \
--preprocessing_num_workers 16 \
--finetuning_type full \
--template default \
--flash_attn auto \
--dataset_dir {dataset_dir} \
--dataset SFT_medicalKnowledge_source1_548404,SFT_medicalKnowledge_source2_99334,SFT_medicalKnowledge_source3_556540,SFT_nlpDiseaseDiagnosed_61486,SFT_nlpSyndromeDiagnosed_48665,SFT_structGeneral_310860,SFT_structPrescription_92896,_SFT_traditionalTrans_1959542.json,{BAAI/COIG},{m-a-p/COIG-CQIA} \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 1000000 \
--per_device_train_batch_size 28 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 1 \
--save_steps 1000 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir {output_dir} \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--deepspeed cache/ds_z3_offload_config.json
後續計劃
測試評估結果正在路上... 第二個epoch的模型也正在路上...
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言