🚀 Karlo v1 alpha
Karlo是一個基於文本條件的圖像生成模型,它基於OpenAI的unCLIP架構。該模型對標準超分辨率模塊進行了改進,能夠在少量去噪步驟內將圖像從64px提升到256px,並恢復高頻細節。
🚀 快速開始
Karlo可通過diffusers庫使用。你可以按照以下步驟進行安裝和使用。
📦 安裝指南
pip install diffusers transformers accelerate safetensors
💻 使用示例
基礎用法
文本到圖像
from diffusers import UnCLIPPipeline
import torch
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
prompt = "a high-resolution photograph of a big red frog on a green leaf."
image = pipe([prompt]).images[0]
image.save("./frog.png")

圖像變體
from diffusers import UnCLIPImageVariationPipeline
import torch
from PIL import Image
pipe = UnCLIPImageVariationPipeline.from_pretrained("kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
image = Image.open("./frog.png")
image = pipe(image).images[0]
image.save("./frog-variation.png")

📚 詳細文檔
模型架構概述
Karlo是一個基於unCLIP的文本條件擴散模型,由先驗模塊(Prior)、解碼器(Decoder)和超分辨率模塊(SR)組成。在本倉庫中,我們包含了標準超分辨率模塊的改進版本,它僅需7個反向步驟就能將64px的圖像提升到256px,如下圖所示:
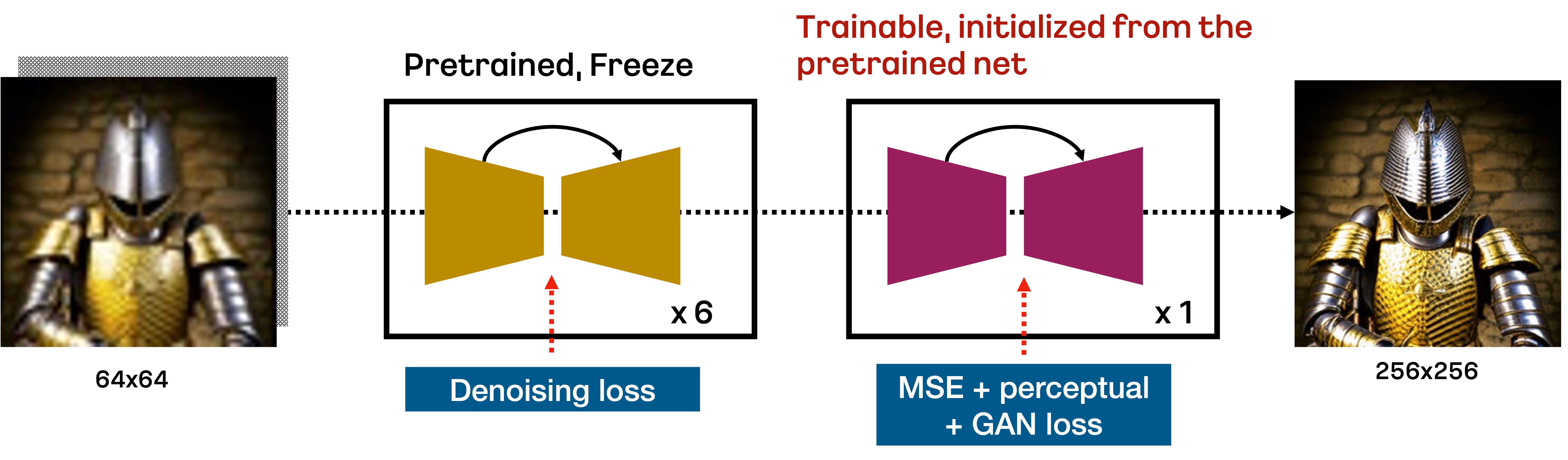
具體來說,由DDPM目標訓練的標準SR模塊基於重採樣技術,在前6個去噪步驟中將64px提升到256px。然後,由VQ - GAN-style損失訓練的額外微調SR模塊執行最後一個反向步驟,以恢復高頻細節。我們發現這種方法在少量反向步驟內提升低分辨率圖像非常有效。
模型架構細節
我們在包含COYO - 100M、CC3M和CC12M的1.15億圖像 - 文本對上從頭開始訓練所有組件。對於先驗模塊和解碼器,我們使用OpenAI的CLIP倉庫提供的ViT - L/14。與原始的unCLIP實現不同,為了提高效率,我們將解碼器中的可訓練變壓器替換為ViT - L/14中的文本編碼器。對於SR模塊,我們首先使用DDPM目標在100萬步內訓練模型,然後再進行23.4萬步的額外微調。下表總結了我們各組件的重要統計信息:
| 組件 |
先驗模塊(Prior) |
解碼器(Decoder) |
超分辨率模塊(SR) |
| CLIP |
ViT - L/14 |
ViT - L/14 |
- |
| 參數數量 |
10億 |
9億 |
7億 + 7億 |
| 優化步數 |
100萬 |
100萬 |
100萬 + 23.4萬 |
| 採樣步數 |
25 |
50(默認),25(快速) |
7 |
| 檢查點鏈接 |
[ViT - L - 14](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/096db1af569b284eb76b3881534822d9/ViT - L - 14.pt),[ViT - L - 14 stats](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/0b62380a75e56f073e2844ab5199153d/ViT - L - 14_stats.th),[模型](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/efdf6206d8ed593961593dc029a8affa/decoder - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[模型](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/85626483eaca9f581e2a78d31ff905ca/prior - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[模型](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/4226b831ae0279020d134281f3c31590/improved - sr - ckpt - step%3D1.2M.ckpt) |
在檢查點鏈接中,ViT - L - 14等同於原始版本,但為了方便我們將其包含在內。我們還需注意,ViT - L - 14 - stats是對先驗模塊的輸出進行歸一化所必需的。
模型評估
我們在CC3M和MS - COCO的驗證分割集中定量測量了Karlo - v1.0.alpha的性能。下表展示了CLIP分數和FID分數。為了測量FID,我們將較短邊的圖像調整為256px,然後在中心進行裁剪。在所有情況下,我們將先驗模塊和解碼器的無分類器引導尺度分別設置為4和8。我們觀察到,即使解碼器僅進行25個採樣步驟,我們的模型也能取得合理的性能。
CC3M
| 採樣步驟 |
CLIP分數(ViT - B/16) |
FID(驗證集1.3萬張圖像) |
| 先驗模塊(25) + 解碼器(25) + 超分辨率模塊(7) |
0.3081 |
14.37 |
| 先驗模塊(25) + 解碼器(50) + 超分辨率模塊(7) |
0.3086 |
13.95 |
MS - COCO
| 採樣步驟 |
CLIP分數(ViT - B/16) |
FID(驗證集3萬張圖像) |
| 先驗模塊(25) + 解碼器(25) + 超分辨率模塊(7) |
0.3192 |
15.24 |
| 先驗模塊(25) + 解碼器(50) + 超分辨率模塊(7) |
0.3192 |
14.43 |
更多信息,請參考即將發佈的技術報告。
訓練細節
這個Karlo的alpha版本在1.15億圖像 - 文本對上進行訓練,這些數據包括[COYO](https://github.com/kakaobrain/coyo - dataset) - 1億高質量子集、CC3M和CC12M。對於那些對在更大規模高質量數據集上訓練的更好版本的Karlo感興趣的人,請訪問我們的應用B^DISCOVER的主頁。
🔧 技術細節
引用格式
如果你在研究中發現本倉庫很有用,請引用以下內容:
@misc{kakaobrain2022karlo-v1-alpha,
title = {Karlo-v1.0.alpha on COYO-100M and CC15M},
author = {Donghoon Lee, Jiseob Kim, Jisu Choi, Jongmin Kim, Minwoo Byeon, Woonhyuk Baek and Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/karlo}},
}
📄 許可證
本項目採用CreativeML OpenRAIL - M許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言