🚀 Karlo v1 alpha
Karlo is a text-conditional image generation model. It's based on OpenAI's unCLIP architecture and improves the standard super-resolution model from 64px to 256px. It can recover high-frequency details in just a few denoising steps.
🚀 Quick Start
Karlo is available in diffusers!
pip install diffusers transformers accelerate safetensors
💻 Usage Examples
Basic Usage
Text to image
from diffusers import UnCLIPPipeline
import torch
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
prompt = "a high-resolution photograph of a big red frog on a green leaf."
image = pipe([prompt]).images[0]
image.save("./frog.png")

Image variation
from diffusers import UnCLIPImageVariationPipeline
import torch
from PIL import Image
pipe = UnCLIPImageVariationPipeline.from_pretrained("kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
image = Image.open("./frog.png")
image = pipe(image).images[0]
image.save("./frog-variation.png")

📚 Documentation
Model Architecture
Overview
Karlo is a text-conditional diffusion model based on unCLIP, composed of prior, decoder, and super-resolution modules. In this repository, we include the improved version of the standard super-resolution module for upscaling 64px to 256px only in 7 reverse steps, as illustrated in the figure below:
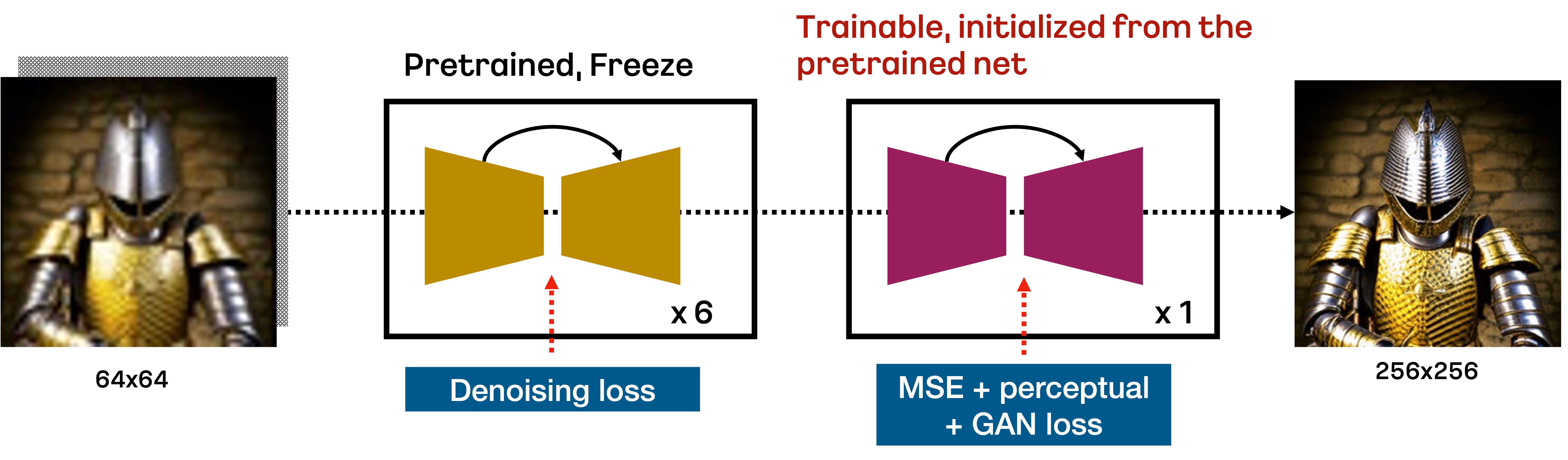
Specifically, the standard SR module trained by the DDPM objective upscales 64px to 256px in the first 6 denoising steps based on the respacing technique. Then, the additional fine-tuned SR module trained by VQ - GAN-style loss performs the final reverse step to recover high-frequency details. We find that this approach is very effective for upscaling low-resolution images in a small number of reverse steps.
Details
We train all components from scratch on 115M image-text pairs, including COYO - 100M, CC3M, and CC12M. For the Prior and Decoder, we use ViT - L/14 provided by OpenAI’s CLIP repository. Unlike the original implementation of unCLIP, we replace the trainable transformer in the decoder with the text encoder in ViT - L/14 for efficiency. For the SR module, we first train the model using the DDPM objective in 1M steps, followed by an additional 234K steps to fine - tune the additional component. The table below summarizes the important statistics of our components:
| Property |
Prior |
Decoder |
SR |
| CLIP |
ViT - L/14 |
ViT - L/14 |
- |
| #param |
1B |
900M |
700M + 700M |
| #optimization steps |
1M |
1M |
1M + 0.2M |
| #sampling steps |
25 |
50 (default), 25 (fast) |
7 |
| Checkpoint links |
[ViT - L - 14](https://arena.kakaocdn.net/brainrepo/models/karlo - public/v1.0.0.alpha/096db1af569b284eb76b3881534822d9/ViT - L - 14.pt), [ViT - L - 14 stats](https://arena.kakaocdn.net/brainrepo/models/karlo - public/v1.0.0.alpha/0b62380a75e56f073e2844ab5199153d/ViT - L - 14_stats.th), [model](https://arena.kakaocdn.net/brainrepo/models/karlo - public/v1.0.0.alpha/efdf6206d8ed593961593dc029a8affa/decoder - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[model](https://arena.kakaocdn.net/brainrepo/models/karlo - public/v1.0.0.alpha/85626483eaca9f581e2a78d31ff905ca/prior - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[model](https://arena.kakaocdn.net/brainrepo/models/karlo - public/v1.0.0.alpha/4226b831ae0279020d134281f3c31590/improved - sr - ckpt - step%3D1.2M.ckpt) |
In the checkpoint links, ViT - L/14 is equivalent to the original version, but we include it for convenience. We also note that ViT - L/14 - stats is required to normalize the outputs of the prior module.
Evaluation
We quantitatively measure the performance of Karlo - v1.0.alpha in the validation split of CC3M and MS - COCO. The table below presents the CLIP - score and FID. To measure FID, we resize the shorter side of the image to 256px and then crop it at the center. We set the classifier - free guidance scales for the prior and decoder to 4 and 8 in all cases. We find that our model achieves reasonable performance even with 25 sampling steps of the decoder.
CC3M
| Sampling step |
CLIP - s (ViT - B/16) |
FID (13k from val) |
| Prior (25) + Decoder (25) + SR (7) |
0.3081 |
14.37 |
| Prior (25) + Decoder (50) + SR (7) |
0.3086 |
13.95 |
MS - COCO
| Sampling step |
CLIP - s (ViT - B/16) |
FID (30k from val) |
| Prior (25) + Decoder (25) + SR (7) |
0.3192 |
15.24 |
| Prior (25) + Decoder (50) + SR (7) |
0.3192 |
14.43 |
For more information, please refer to the upcoming technical report.
Training Details
This alpha version of Karlo is trained on 115M image - text pairs, including the [COYO](https://github.com/kakaobrain/coyo - dataset) - 100M high - quality subset, CC3M, and CC12M. For those interested in a better version of Karlo trained on more large - scale high - quality datasets, please visit the landing page of our application B^DISCOVER.
📄 License
The license for this project is creativeml - openrail - m.
🔗 BibTex
If you find this repository useful in your research, please cite:
@misc{kakaobrain2022karlo-v1-alpha,
title = {Karlo-v1.0.alpha on COYO-100M and CC15M},
author = {Donghoon Lee, Jiseob Kim, Jisu Choi, Jongmin Kim, Minwoo Byeon, Woonhyuk Baek and Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/karlo}},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors