%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Wav2vec LnNor IPA Ft
W
Wav2vec LnNor IPA Ft
由MultiBridge開發
基於wav2vec2-base微調的音素識別模型,支持英語語音轉國際音標(IPA)

下載量 16
發布時間 : 3/2/2025
模型概述
該模型通過對TIMIT和LnNor數據集的微調開發,專門用於音素識別任務,預測結果採用國際音標(IPA)表示。
模型特點
多數據集微調
結合TIMIT和LnNor數據集進行訓練,增強模型泛化能力
國際音標輸出
直接輸出國際音標(IPA)表示,便於語音學研究
預訓練特徵保留
凍結編碼器保留了wav2vec2-base的有用預學習特徵
模型能力
英語音素識別
語音轉音標
自動音標轉寫
使用案例
語音處理
自動音標轉寫
將原始語音轉換為音素序列
語音處理組件
作為語音處理流程中的組件或原型開發
🚀 MultiBridge/wav2vec-LnNor-IPA-ft模型卡片
本模型專為音素識別任務而構建。它通過在TIMIT和LnNor數據集上微調wav2vec2基礎模型而開發,預測結果採用國際音標(IPA)表示。
🚀 快速開始
使用以下代碼開始使用該模型:
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
model = Wav2Vec2ForCTC.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['mɪstɝkwɪltɝɪzðəəpɑslʌvðəmɪdəlklæsəzændwiɑəɡlædtəwɛlkəmhɪzɡɑspəl'] for MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL
✨ 主要特性
- 基於Transformer架構,專為音素識別任務設計。
- 微調自facebook/wav2vec2-base模型。
- 支持英語的自動音素轉錄。
📦 安裝指南
文檔未提及具體安裝步驟,故跳過該章節。
💻 使用示例
基礎用法
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
model = Wav2Vec2ForCTC.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['mɪstɝkwɪltɝɪzðəəpɑslʌvðəmɪdəlklæsəzændwiɑəɡlædtəwɛlkəmhɪzɡɑspəl'] for MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL
📚 詳細文檔
模型詳情
| 屬性 | 詳情 |
|---|---|
| 開發方 | Multibridge |
| 資助方 | EEA金融機制和挪威金融機制 |
| 共享方 | Multibridge |
| 模型類型 | Transformer |
| 語言 | 英語 |
| 許可證 | cc-by-4.0 |
| 微調基礎模型 | facebook/wav2vec2-base |
用途
- 自動語音轉錄:將原始語音轉換為音素序列。
- 語音處理應用:作為語音處理管道或原型的組件。
偏差、風險和侷限性
- 數據特異性:通過排除短於2秒或長於30秒的錄音,以及少於5個音素的標籤,一些自然語音變化被忽略。這可能會影響模型在實際應用中的性能。模型的性能受TIMIT和LnNor數據集特徵的影響,這可能導致潛在的偏差,特別是當目標應用涉及這些數據集中未充分代表的說話者或方言時。LnNor包含非母語語音和自動生成的標註,這些標註反映的是規範音素,而非自然語音或非母語發音的真實發音。這可能導致模型無法準確預測非母語語音。
- 凍結編碼器:凍結編碼器保留了有用的預學習特徵,但也阻止了模型完全適應新數據集。
建議
評估模型在您特定用例中的性能。
訓練詳情
訓練數據
- TIMIT:一個廣泛用於語音轉錄的數據集,為語音研究提供了標準基準。
- LnNor:一個多語言數據集,包含挪威語、英語和波蘭語的高質量語音記錄。該數據集由具有不同語言水平的非母語人士編譯而成。LnNor中的音素標註使用WebMAUS工具生成,這意味著它們代表的是規範音素,而非自然語音或非母語發音的真實發音。
訓練過程
原始的預訓練編碼器表示被保留 - 在微調過程中,編碼器保持凍結,以最小化訓練時間和資源消耗。模型使用CTC損失和AdamW優化器進行訓練,沒有使用學習率調度器。
預處理
訓練數據集經過過濾。短於2秒或長於30秒的錄音被移除。任何由少於5個音素組成的標籤被丟棄。
訓練超參數
- 學習率:1e-5
- 優化器:AdamW
- 批量大小:64
- 權重衰減:0.001
- 訓練輪數:40
速度、大小、時間
- 平均每輪訓練時間:650秒
- 更新次數:約25k
- 最終訓練損失:0.09713
- 最終驗證損失:0.2142
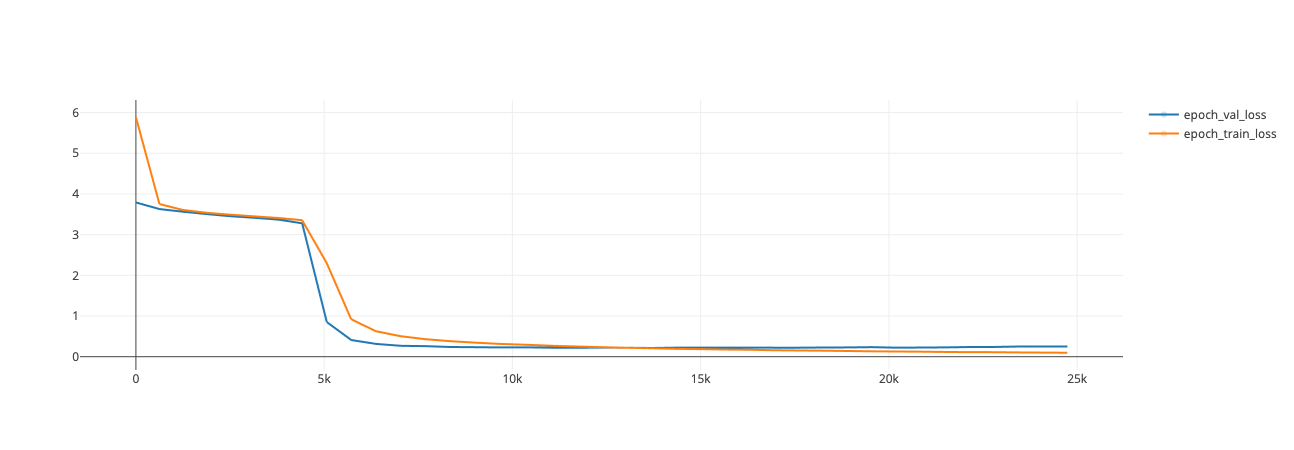
評估
測試數據、因素和指標
- 測試數據:模型在TIMIT的測試集上進行評估。
- 指標:CER/PER(音素錯誤率)
結果
TIMIT測試集上的PER(音素錯誤率):0.0416
環境影響
可以使用機器學習影響計算器(來自Lacoste等人(2019))估算碳排放。
- 硬件類型:Nvidia A100 - 80
- 使用時長:[需要更多信息]
- 雲服務提供商:波茲南工業大學
- 計算區域:波蘭
- 碳排放:[需要更多信息]
技術規格
模型架構和目標
Transformer模型 + CTC損失
計算基礎設施
- 硬件:2 x Nvidia A100 - 80
- 軟件:python 3.12,transformers 4.50.0,torch 2.6.0
引用
如果您在研究中使用LnNor數據集,請引用以下論文:
@article{magdalena2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish (Part 1)},
author={Magdalena, Wrembel and Hwaszcz, Krzysztof and Agnieszka, Pludra and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Walczak, Angelika and Sypia{\'n}ska, Jolanta and {\.Z}ychli{\'n}ski, Sylwiusz and Malarski, Kamil and K{\k{e}}dzierska, Hanna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
@article{wrembel2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish--Part 2},
author={Wrembel, Magdalena and Hwaszcz, Krzysztof and Pludra, Agnieszka and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Malarski, Kamil and Cal, Zuzanna Ewa and K{\k{e}}dzierska, Hanna and Czarnecki-Verner, Tristan and Balas, Anna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
模型卡片作者
- Agnieszka Pludra
- Izabela Krysińska
- Piotr Kabaciński
模型卡片聯繫方式
- agnieszka.pludra@pearson.com
- izabela.krysinska@pearson.com
- piotr.kabacinski@pearson.com
📄 許可證
本模型使用cc-by-4.0許可證。
Voice Activity Detection
MIT
基於pyannote.audio 2.1版本的語音活動檢測模型,用於識別音頻中的語音活動時間段
語音識別
V
pyannote
7.7M
181
Wav2vec2 Large Xlsr 53 Portuguese
Apache-2.0
這是一個針對葡萄牙語語音識別任務微調的XLSR-53大模型,基於Common Voice 6.1數據集訓練,支持葡萄牙語語音轉文本。
語音識別 其他
W
jonatasgrosman
4.9M
32
Whisper Large V3
Apache-2.0
Whisper是由OpenAI提出的先進自動語音識別(ASR)和語音翻譯模型,在超過500萬小時的標註數據上訓練,具有強大的跨數據集和跨領域泛化能力。
語音識別 支持多種語言
W
openai
4.6M
4,321
Whisper Large V3 Turbo
MIT
Whisper是由OpenAI開發的最先進的自動語音識別(ASR)和語音翻譯模型,經過超過500萬小時標記數據的訓練,在零樣本設置下展現出強大的泛化能力。
語音識別 Transformers 支持多種語言
Transformers 支持多種語言
W
openai
4.0M
2,317
Wav2vec2 Large Xlsr 53 Russian
Apache-2.0
基於facebook/wav2vec2-large-xlsr-53模型微調的俄語語音識別模型,支持16kHz採樣率的語音輸入
語音識別 其他
W
jonatasgrosman
3.9M
54
Wav2vec2 Large Xlsr 53 Chinese Zh Cn
Apache-2.0
基於facebook/wav2vec2-large-xlsr-53模型微調的中文語音識別模型,支持16kHz採樣率的語音輸入。
語音識別 中文
W
jonatasgrosman
3.8M
110
Wav2vec2 Large Xlsr 53 Dutch
Apache-2.0
基於facebook/wav2vec2-large-xlsr-53微調的荷蘭語語音識別模型,在Common Voice和CSS10數據集上訓練,支持16kHz音頻輸入。
語音識別 其他
W
jonatasgrosman
3.0M
12
Wav2vec2 Large Xlsr 53 Japanese
Apache-2.0
基於facebook/wav2vec2-large-xlsr-53模型微調的日語語音識別模型,支持16kHz採樣率的語音輸入
語音識別 日語
W
jonatasgrosman
2.9M
33
Mms 300m 1130 Forced Aligner
基於Hugging Face預訓練模型的文本與音頻強制對齊工具,支持多種語言,內存效率高
語音識別 Transformers 支持多種語言
M
MahmoudAshraf
2.5M
50
Wav2vec2 Large Xlsr 53 Arabic
Apache-2.0
基於facebook/wav2vec2-large-xlsr-53微調的阿拉伯語語音識別模型,在Common Voice和阿拉伯語語音語料庫上訓練
語音識別 阿拉伯語
W
jonatasgrosman
2.3M
37
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98