%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Ovis2 1B Dev
Ovis2-1B是多模態大語言模型(MLLM)Ovis系列的最新成員,專注於視覺與文本嵌入的結構對齊,具有小模型高性能、強化推理能力、視頻與多圖處理以及多語言OCR增強等特性。
下載量 79
發布時間 : 4/9/2025
模型概述
Ovis2-1B是AIDC-AI發佈的多模態大語言模型,旨在實現視覺與文本嵌入的結構對齊。作為Ovis1.6的迭代升級,Ovis2在數據構建和訓練方法上均有顯著提升,特別適合處理複雜的視覺信息和多語言OCR任務。
模型特點
小模型高性能
通過優化訓練策略,使小規模模型實現更高能力密度,展現跨層級領先優勢。
強化推理能力
結合指令微調與偏好學習,顯著增強思維鏈(CoT)推理能力。
視頻與多圖處理
將視頻和多圖數據納入訓練,提升跨幀/跨圖像的複雜視覺信息處理能力。
多語言OCR增強
在英漢雙語基礎上優化多語言OCR能力,提升從表格/圖表等複雜視覺元素中提取結構化數據的效果。
模型能力
圖像理解
文本生成
視頻理解
多圖分析
多語言OCR
複雜推理
使用案例
視覺問答
圖像內容描述
對輸入圖像進行詳細描述
在MMBench-V1.1測試集上達到68.4分
視覺推理
基於圖像內容進行邏輯推理
在MathVista測試精簡集上達到59.4分
文檔理解
表格數據提取
從複雜表格中提取結構化數據
在OCRBench上達到89.0分
視頻理解
視頻內容分析
理解視頻中的動作和場景
在VideoMME(帶字幕)上達到49.5分
🚀 Ovis2-1B
Ovis2-1B是一款多模態大語言模型,繼承了Ovis系列的創新架構設計,在數據集管理和訓練方法上有顯著改進,具備小模型高性能、增強推理能力、支持視頻和多圖像處理以及多語言OCR等特性。
🚀 快速開始
你可以按照以下步驟使用Ovis2-1B模型:
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# 加載模型
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# 單圖像輸入
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
## 思維鏈風格輸入
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
# image_path = '/data/images/example_1.jpg'
# images = [Image.open(image_path)]
# max_partition = 9
# text = "What's the area of the shape?"
# query = f'<image>\n{text}\n{cot_suffix}'
## 多圖像輸入
# image_paths = [
# '/data/images/example_1.jpg',
# '/data/images/example_2.jpg',
# '/data/images/example_3.jpg'
# ]
# images = [Image.open(image_path) for image_path in image_paths]
# max_partition = 4
# text = 'Describe each image.'
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
## 視頻輸入 (需要 `pip install moviepy==1.0.3`)
# from moviepy.editor import VideoFileClip
# video_path = '/data/videos/example_1.mp4'
# num_frames = 12
# max_partition = 1
# text = 'Describe the video.'
# with VideoFileClip(video_path) as clip:
# total_frames = int(clip.fps * clip.duration)
# if total_frames <= num_frames:
# sampled_indices = range(total_frames)
# else:
# stride = total_frames / num_frames
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
# images = frames
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
## 純文本輸入
# images = []
# max_partition = None
# text = 'Hello'
# query = text
# 格式化對話
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# 生成輸出
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'輸出:\n{output}')
批量推理
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# 加載模型
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# 預處理輸入
batch_inputs = [
('/data/images/example_1.jpg', 'What colors dominate the image?'),
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
('/data/images/example_3.jpg', 'Is there any text in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'<image>\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
batch_input_ids.append(input_ids.to(device=model.device))
batch_attention_mask.append(attention_mask.to(device=model.device))
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
padding_value=0.0).flip(dims=[1])
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
batch_first=True, padding_value=False).flip(dims=[1])
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
# 生成輸出
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
**gen_kwargs)
for i in range(len(batch_inputs)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'輸出 {i + 1}:\n{output}\n')
✨ 主要特性
- 小模型高性能:優化的訓練策略使小模型實現更高的能力密度,展現跨層級的領先優勢。
- 增強推理能力:通過指令微調與偏好學習相結合,顯著增強思維鏈(CoT)推理能力。
- 視頻和多圖像處理:將視頻和多圖像數據納入訓練,增強處理跨幀和圖像的複雜視覺信息的能力。
- 多語言支持和OCR:增強英語和中文以外的多語言OCR能力,改進從表格和圖表等複雜視覺元素中提取結構化數據的能力。
📦 安裝指南
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
💻 使用示例
基礎用法
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# 加載模型
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# 單圖像輸入
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# 格式化對話
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# 生成輸出
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'輸出:\n{output}')
高級用法
# 批量推理示例
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# 加載模型
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# 預處理輸入
batch_inputs = [
('/data/images/example_1.jpg', 'What colors dominate the image?'),
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
('/data/images/example_3.jpg', 'Is there any text in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'<image>\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
batch_input_ids.append(input_ids.to(device=model.device))
batch_attention_mask.append(attention_mask.to(device=model.device))
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
padding_value=0.0).flip(dims=[1])
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
batch_first=True, padding_value=False).flip(dims=[1])
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
# 生成輸出
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
**gen_kwargs)
for i in range(len(batch_inputs)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'輸出 {i + 1}:\n{output}\n')
📚 詳細文檔
模型庫
| Ovis多模態大語言模型 | 視覺Transformer(ViT) | 大語言模型(LLM) | 模型權重 | 演示 |
|---|---|---|---|---|
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | Huggingface | Space |
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | Huggingface | Space |
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | Huggingface | Space |
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | Huggingface | Space |
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | Huggingface | Space |
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | Huggingface | - |
性能評估
我們使用 VLMEvalKit 對Ovis2進行評估,該工具也用於OpenCompass 多模態 和 推理 排行榜。
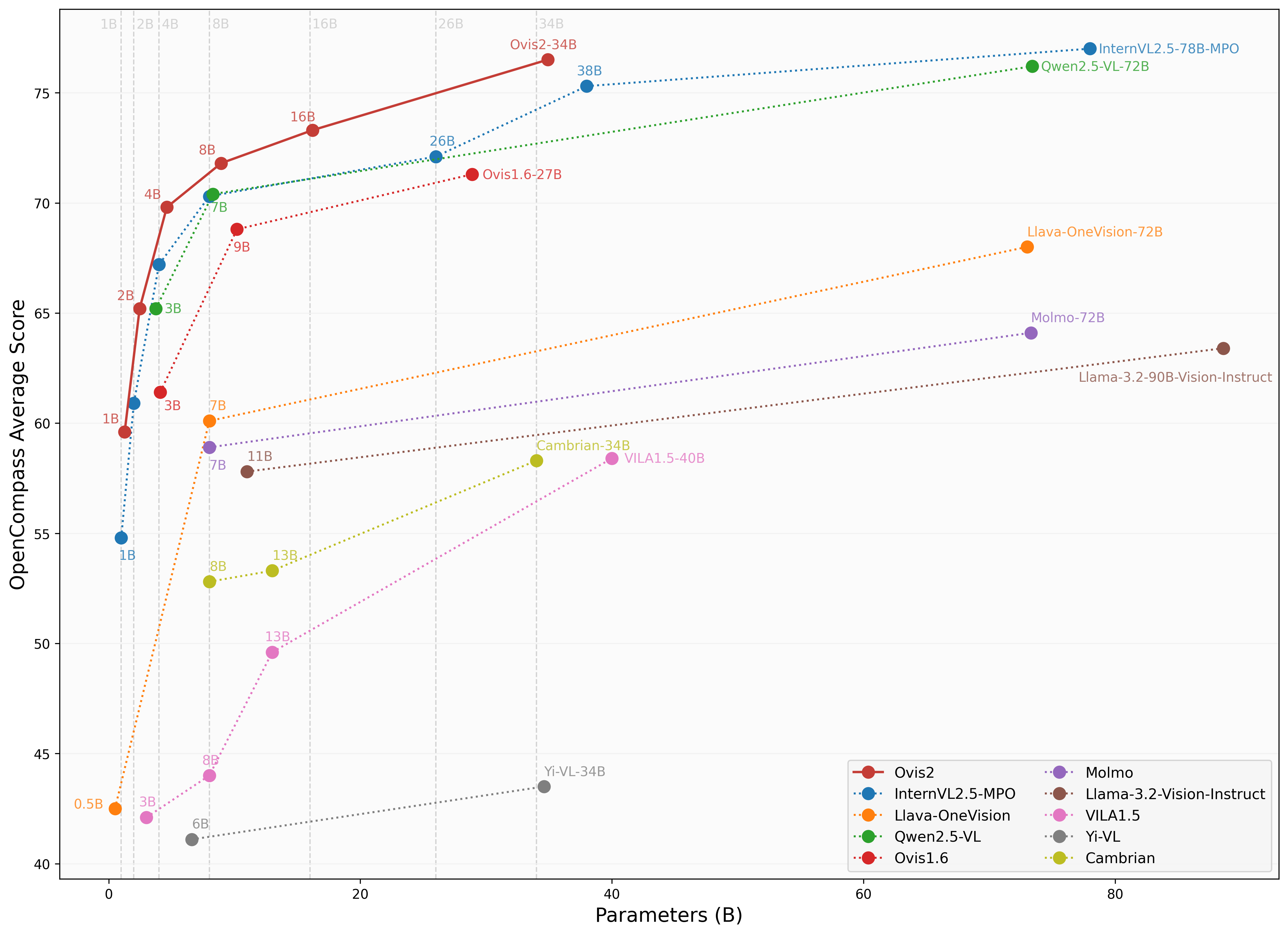
圖像基準測試
| 基準測試 | Qwen2.5-VL-3B | SAIL-VL-2B | InternVL2.5-2B-MPO | Ovis1.6-3B | InternVL2.5-1B-MPO | Ovis2-1B | Ovis2-2B |
|---|---|---|---|---|---|---|---|
| MMBench-V1.1測試集 | 77.1 | 73.6 | 70.7 | 74.1 | 65.8 | 68.4 | 76.9 |
| MMStar | 56.5 | 56.5 | 54.9 | 52.0 | 49.5 | 52.1 | 56.7 |
| MMMU驗證集 | 51.4 | 44.1 | 44.6 | 46.7 | 40.3 | 36.1 | 45.6 |
| MathVista測試迷你集 | 60.1 | 62.8 | 53.4 | 58.9 | 47.7 | 59.4 | 64.1 |
| HallusionBench | 48.7 | 45.9 | 40.7 | 43.8 | 34.8 | 45.2 | 50.2 |
| AI2D | 81.4 | 77.4 | 75.1 | 77.8 | 68.5 | 76.4 | 82.7 |
| OCRBench | 83.1 | 83.1 | 83.8 | 80.1 | 84.3 | 89.0 | 87.3 |
| MMVet | 63.2 | 44.2 | 64.2 | 57.6 | 47.2 | 50.0 | 58.3 |
| MMBench測試集 | 78.6 | 77 | 72.8 | 76.6 | 67.9 | 70.2 | 78.9 |
| MMT-Bench驗證集 | 60.8 | 57.1 | 54.4 | 59.2 | 50.8 | 55.5 | 61.7 |
| RealWorldQA | 66.5 | 62 | 61.3 | 66.7 | 57 | 63.9 | 66.0 |
| BLINK | 48.4 | 46.4 | 43.8 | 43.8 | 41 | 44.0 | 47.9 |
| QBench | 74.4 | 72.8 | 69.8 | 75.8 | 63.3 | 71.3 | 76.2 |
| ABench | 75.5 | 74.5 | 71.1 | 75.2 | 67.5 | 71.3 | 76.6 |
| MTVQA | 24.9 | 20.2 | 22.6 | 21.1 | 21.7 | 23.7 | 25.6 |
視頻基準測試
| 基準測試 | Qwen2.5-VL-3B | InternVL2.5-2B | InternVL2.5-1B | Ovis2-1B | Ovis2-2B |
|---|---|---|---|---|---|
| VideoMME(無字幕/有字幕) | 61.5/67.6 | 51.9 / 54.1 | 50.3 / 52.3 | 48.6/49.5 | 57.2/60.8 |
| MVBench | 67.0 | 68.8 | 64.3 | 60.32 | 64.9 |
| MLVU(均值/全局均值) | 68.2/- | 61.4/- | 57.3/- | 58.5/3.66 | 68.6/3.86 |
| MMBench-視頻 | 1.63 | 1.44 | 1.36 | 1.26 | 1.57 |
| TempCompass | 64.4 | - | - | 51.43 | 62.64 |
📄 許可證
本項目採用 Apache許可證2.0版(SPDX許可證標識符:Apache-2.0)。
📚 引用
如果你發現Ovis模型有用,請考慮引用以下論文:
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
⚠️ 免責聲明
我們在訓練過程中使用了合規檢查算法,以盡力確保訓練模型的合規性。由於數據的複雜性和語言模型使用場景的多樣性,我們不能保證模型完全沒有版權問題或不當內容。如果你認為有任何內容侵犯了你的權利或產生了不當內容,請聯繫我們,我們將及時處理。
Clip Vit Large Patch14 336
基於Vision Transformer架構的大規模視覺語言預訓練模型,支持圖像與文本的跨模態理解
文本生成圖像 Transformers
Transformers
C
openai
5.9M
241
Fashion Clip
MIT
FashionCLIP是基於CLIP開發的視覺語言模型,專門針對時尚領域進行微調,能夠生成通用產品表徵。
文本生成圖像 Transformers 英語
F
patrickjohncyh
3.8M
222
Gemma 3 1b It
Gemma 3是Google推出的輕量級先進開放模型系列,基於與Gemini模型相同的研究和技術構建。該模型是多模態模型,能夠處理文本和圖像輸入並生成文本輸出。
文本生成圖像 Transformers
G
google
2.1M
347
Blip Vqa Base
Bsd-3-clause
BLIP是一個統一的視覺語言預訓練框架,擅長視覺問答任務,通過語言-圖像聯合訓練實現多模態理解與生成能力
文本生成圖像 Transformers
B
Salesforce
1.9M
154
CLIP ViT H 14 Laion2b S32b B79k
MIT
基於OpenCLIP框架在LAION-2B英文數據集上訓練的視覺-語言模型,支持零樣本圖像分類和跨模態檢索任務
文本生成圖像 Safetensors
Safetensors
SafetensorsC
laion
1.8M
368
CLIP ViT B 32 Laion2b S34b B79k
MIT
基於OpenCLIP框架在LAION-2B英語子集上訓練的視覺-語言模型,支持零樣本圖像分類和跨模態檢索
文本生成圖像 Safetensors
SafetensorsC
laion
1.1M
112
Pickscore V1
PickScore v1 是一個針對文本生成圖像的評分函數,可用於預測人類偏好、評估模型性能和圖像排序等任務。
文本生成圖像 Transformers
P
yuvalkirstain
1.1M
44
Owlv2 Base Patch16 Ensemble
Apache-2.0
OWLv2是一種零樣本文本條件目標檢測模型,可通過文本查詢在圖像中定位對象。
文本生成圖像 Transformers
O
google
932.80k
99
Llama 3.2 11B Vision Instruct
Llama 3.2 是 Meta 發佈的多語言多模態大型語言模型,支持圖像文本到文本的轉換任務,具備強大的跨模態理解能力。
文本生成圖像 Transformers 支持多種語言
L
meta-llama
784.19k
1,424
Owlvit Base Patch32
Apache-2.0
OWL-ViT是一個零樣本文本條件目標檢測模型,可以通過文本查詢搜索圖像中的對象,無需特定類別的訓練數據。
文本生成圖像 Transformers
O
google
764.95k
129
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98