%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
JA
Ovis2 1B Dev
Ovis2-1Bはマルチモーダル大規模言語モデル(MLLM)Ovisシリーズの最新メンバーで、視覚とテキストの埋め込み構造のアライメントに焦点を当て、小型モデルながら高性能、強化された推論能力、動画と複数画像処理、多言語OCR強化などの特徴を備えています。
ダウンロード数 79
リリース時間 : 4/9/2025
モデル概要
Ovis2-1BはAIDC-AIがリリースしたマルチモーダル大規模言語モデルで、視覚とテキストの埋め込み構造のアライメントを実現することを目的としています。Ovis1.6のイテレーションアップグレードとして、Ovis2はデータ構築とトレーニング方法の両方で大幅な改善が見られ、複雑な視覚情報と多言語OCRタスクの処理に特に適しています。
モデル特徴
小型モデル高性能
トレーニング戦略を最適化することで、小規模モデルがより高い能力密度を実現し、クロスレベルでのリーディングアドバンテージを示します。
強化された推論能力
命令微調整と選好学習を組み合わせることで、思考連鎖(CoT)推論能力を大幅に強化します。
動画と複数画像処理
動画と複数画像データをトレーニングに組み込むことで、フレーム間/画像間の複雑な視覚情報処理能力を向上させます。
多言語OCR強化
英語と中国語のバイリンガルベースで多言語OCR能力を最適化し、表/グラフなどの複雑な視覚要素から構造化データを抽出する効果を向上させます。
モデル能力
画像理解
テキスト生成
動画理解
複数画像分析
多言語OCR
複雑な推論
使用事例
視覚的質問応答
画像内容の説明
入力画像を詳細に説明する
MMBench-V1.1テストセットで68.4点を達成
視覚的推論
画像内容に基づいて論理的に推論する
MathVistaテスト簡易セットで59.4点を達成
ドキュメント理解
表データ抽出
複雑な表から構造化データを抽出する
OCRBenchで89.0点を達成
動画理解
動画内容分析
動画内のアクションとシーンを理解する
VideoMME(字幕付き)で49.5点を達成
🚀 Ovis2-1B
Ovis2 は、多モーダル大規模言語モデル(MLLMs)における最新の進歩です。Ovisシリーズの革新的なアーキテクチャ設計を継承し、視覚とテキストの埋め込みを構造的にアラインさせることを目指しています。Ovis1.6の後継として、データセットの選定とトレーニング方法の両方で大幅な改善が加えられています。
🚀 クイックスタート
このセクションでは、Ovis2-1Bの基本的な使い方を説明します。以下のコードを参考に、モデルを実行することができます。
インストール
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
モデルの実行
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
## cot-style input
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
# image_path = '/data/images/example_1.jpg'
# images = [Image.open(image_path)]
# max_partition = 9
# text = "What's the area of the shape?"
# query = f'<image>\n{text}\n{cot_suffix}'
## multiple-images input
# image_paths = [
# '/data/images/example_1.jpg',
# '/data/images/example_2.jpg',
# '/data/images/example_3.jpg'
# ]
# images = [Image.open(image_path) for image_path in image_paths]
# max_partition = 4
# text = 'Describe each image.'
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
## video input (require `pip install moviepy==1.0.3`)
# from moviepy.editor import VideoFileClip
# video_path = '/data/videos/example_1.mp4'
# num_frames = 12
# max_partition = 1
# text = 'Describe the video.'
# with VideoFileClip(video_path) as clip:
# total_frames = int(clip.fps * clip.duration)
# if total_frames <= num_frames:
# sampled_indices = range(total_frames)
# else:
# stride = total_frames / num_frames
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
# images = frames
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
## text-only input
# images = []
# max_partition = None
# text = 'Hello'
# query = text
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
バッチ推論
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# preprocess inputs
batch_inputs = [
('/data/images/example_1.jpg', 'What colors dominate the image?'),
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
('/data/images/example_3.jpg', 'Is there any text in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'<image>\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
batch_input_ids.append(input_ids.to(device=model.device))
batch_attention_mask.append(attention_mask.to(device=model.device))
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
padding_value=0.0).flip(dims=[1])
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
batch_first=True, padding_value=False).flip(dims=[1])
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
# generate outputs
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
**gen_kwargs)
for i in range(len(batch_inputs)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'Output {i + 1}:\n{output}\n')
✨ 主な機能
- 小規模モデルの高性能化:最適化されたトレーニング戦略により、小規模モデルでも高い能力密度を達成し、クロス階層でのリーディングアドバンテージを発揮します。
- 強化された推論能力:命令微調整と嗜好学習の組み合わせにより、Chain-of-Thought(CoT)推論能力が大幅に強化されています。
- ビデオと複数画像の処理:ビデオと複数画像のデータをトレーニングに組み込むことで、フレームや画像をまたいだ複雑な視覚情報の処理能力が向上しています。
- 多言語サポートとOCR:英語と中国語以外の多言語OCRが強化され、表やグラフなどの複雑な視覚要素からの構造化データ抽出も改善されています。
📦 モデル一覧
| Ovis MLLMs | ViT | LLM | モデルウェイト | デモ |
|---|---|---|---|---|
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | Huggingface | Space |
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | Huggingface | Space |
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | Huggingface | Space |
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | Huggingface | Space |
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | Huggingface | Space |
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | Huggingface | - |
📊 性能評価
Ovis2の評価には、OpenCompassのマルチモーダルおよび推論のリーダーボードで使用されているVLMEvalKitを使用しています。
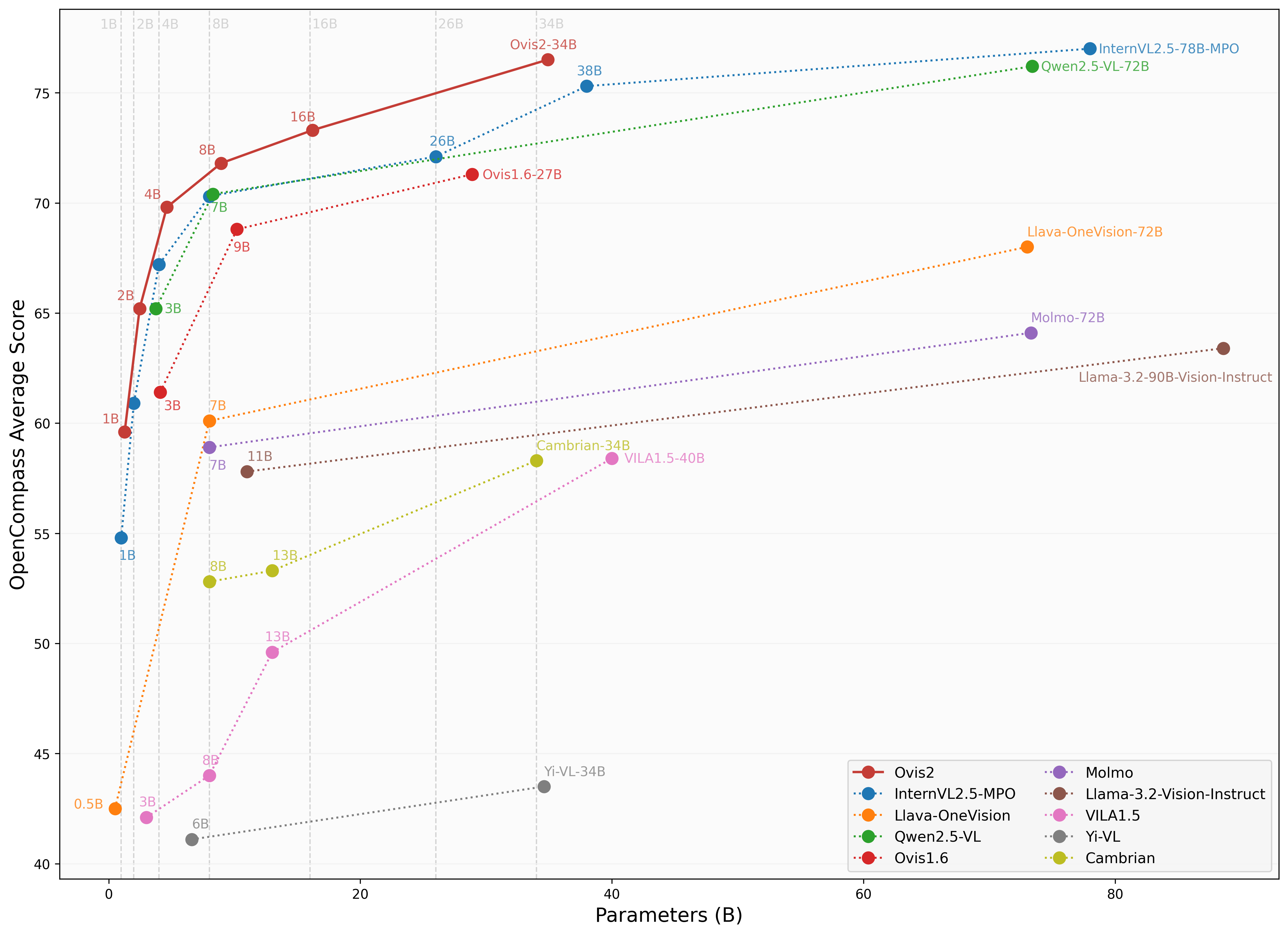
画像ベンチマーク
| ベンチマーク | Qwen2.5-VL-3B | SAIL-VL-2B | InternVL2.5-2B-MPO | Ovis1.6-3B | InternVL2.5-1B-MPO | Ovis2-1B | Ovis2-2B |
|---|---|---|---|---|---|---|---|
| MMBench-V1.1test | 77.1 | 73.6 | 70.7 | 74.1 | 65.8 | 68.4 | 76.9 |
| MMStar | 56.5 | 56.5 | 54.9 | 52.0 | 49.5 | 52.1 | 56.7 |
| MMMUval | 51.4 | 44.1 | 44.6 | 46.7 | 40.3 | 36.1 | 45.6 |
| MathVistatestmini | 60.1 | 62.8 | 53.4 | 58.9 | 47.7 | 59.4 | 64.1 |
| HallusionBench | 48.7 | 45.9 | 40.7 | 43.8 | 34.8 | 45.2 | 50.2 |
| AI2D | 81.4 | 77.4 | 75.1 | 77.8 | 68.5 | 76.4 | 82.7 |
| OCRBench | 83.1 | 83.1 | 83.8 | 80.1 | 84.3 | 89.0 | 87.3 |
| MMVet | 63.2 | 44.2 | 64.2 | 57.6 | 47.2 | 50.0 | 58.3 |
| MMBenchtest | 78.6 | 77 | 72.8 | 76.6 | 67.9 | 70.2 | 78.9 |
| MMT-Benchval | 60.8 | 57.1 | 54.4 | 59.2 | 50.8 | 55.5 | 61.7 |
| RealWorldQA | 66.5 | 62 | 61.3 | 66.7 | 57 | 63.9 | 66.0 |
| BLINK | 48.4 | 46.4 | 43.8 | 43.8 | 41 | 44.0 | 47.9 |
| QBench | 74.4 | 72.8 | 69.8 | 75.8 | 63.3 | 71.3 | 76.2 |
| ABench | 75.5 | 74.5 | 71.1 | 75.2 | 67.5 | 71.3 | 76.6 |
| MTVQA | 24.9 | 20.2 | 22.6 | 21.1 | 21.7 | 23.7 | 25.6 |
ビデオベンチマーク
| ベンチマーク | Qwen2.5-VL-3B | InternVL2.5-2B | InternVL2.5-1B | Ovis2-1B | Ovis2-2B |
|---|---|---|---|---|---|
| VideoMME(wo/w-subs) | 61.5/67.6 | 51.9 / 54.1 | 50.3 / 52.3 | 48.6/49.5 | 57.2/60.8 |
| MVBench | 67.0 | 68.8 | 64.3 | 60.32 | 64.9 |
| MLVU(M-Avg/G-Avg) | 68.2/- | 61.4/- | 57.3/- | 58.5/3.66 | 68.6/3.86 |
| MMBench-Video | 1.63 | 1.44 | 1.36 | 1.26 | 1.57 |
| TempCompass | 64.4 | - | - | 51.43 | 62.64 |
📚 詳細ドキュメント
追加の使用方法や推論ラッパー、Gradio UIについては、Ovis GitHubを参照してください。
📄 引用
Ovisが役に立った場合は、以下の論文を引用していただけると幸いです。
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
📄 ライセンス
このプロジェクトは、Apache License, Version 2.0(SPDX-License-Identifier: Apache-2.0)の下でライセンスされています。
⚠️ 免責事項
トレーニングプロセスではコンプライアンスチェックアルゴリズムを使用し、できる限りトレーニングされたモデルのコンプライアンスを確保しています。しかし、データの複雑性と言語モデルの使用シナリオの多様性により、モデルが著作権問題や不適切なコンテンツを完全に含まないことを保証することはできません。もし何かがあなたの権利を侵害していると感じたり、不適切なコンテンツを生成していると思われる場合は、ご連絡いただければ、速やかに対応いたします。
Clip Vit Large Patch14 336
Vision Transformerアーキテクチャに基づく大規模な視覚言語事前学習モデルで、画像とテキストのクロスモーダル理解をサポートします。
テキスト生成画像 Transformers
Transformers
C
openai
5.9M
241
Fashion Clip
MIT
FashionCLIPはCLIPを基に開発された視覚言語モデルで、ファッション分野に特化してファインチューニングされ、汎用的な製品表現を生成可能です。
テキスト生成画像 Transformers 英語
F
patrickjohncyh
3.8M
222
Gemma 3 1b It
Gemma 3はGoogleが提供する軽量で先進的なオープンモデルシリーズで、Geminiモデルと同じ研究と技術に基づいて構築されています。このモデルはマルチモーダルモデルであり、テキストと画像の入力を処理し、テキスト出力を生成できます。
テキスト生成画像 Transformers
G
google
2.1M
347
Blip Vqa Base
Bsd-3-clause
BLIPは統一された視覚言語事前学習フレームワークで、視覚質問応答タスクに優れており、言語-画像共同トレーニングによりマルチモーダル理解と生成能力を実現
テキスト生成画像 Transformers
B
Salesforce
1.9M
154
CLIP ViT H 14 Laion2b S32b B79k
MIT
OpenCLIPフレームワークを使用してLAION-2B英語データセットでトレーニングされた視覚-言語モデルで、ゼロショット画像分類とクロスモーダル検索タスクをサポートします
テキスト生成画像 Safetensors
Safetensors
SafetensorsC
laion
1.8M
368
CLIP ViT B 32 Laion2b S34b B79k
MIT
OpenCLIPフレームワークを使用し、LAION-2B英語サブセットでトレーニングされた視覚-言語モデルで、ゼロショット画像分類とクロスモーダル検索をサポート
テキスト生成画像 Safetensors
SafetensorsC
laion
1.1M
112
Pickscore V1
PickScore v1はテキストから生成された画像に対するスコアリング関数で、人間の選好予測、モデル性能評価、画像ランキングなどのタスクに使用できます。
テキスト生成画像 Transformers
P
yuvalkirstain
1.1M
44
Owlv2 Base Patch16 Ensemble
Apache-2.0
OWLv2はゼロショットテキスト条件付き物体検出モデルで、テキストクエリを使用して画像内のオブジェクトを位置特定できます。
テキスト生成画像 Transformers
O
google
932.80k
99
Llama 3.2 11B Vision Instruct
Llama 3.2はMetaがリリースした多言語マルチモーダル大規模言語モデルで、画像テキストからテキストへの変換タスクをサポートし、強力なクロスモーダル理解能力を備えています。
テキスト生成画像 Transformers 複数言語対応
L
meta-llama
784.19k
1,424
Owlvit Base Patch32
Apache-2.0
OWL-ViTはゼロショットのテキスト条件付き物体検出モデルで、特定カテゴリの訓練データなしにテキストクエリで画像内のオブジェクトを検索できます。
テキスト生成画像 Transformers
O
google
764.95k
129
おすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98