🚀 OpenHands LM v0.1
OpenHands LM v0.1 是一款開源的編碼模型,基於強大的基礎模型進行微調。它具備 128K 令牌上下文窗口,能處理大型代碼庫和長期軟件工程任務。在 SWE - Bench Verified 基準測試中表現出色,可本地部署,為軟件開發提供了有力支持。
📄 許可證
本項目採用 MIT 許可證。
🚀 快速開始
你可以通過以下途徑立即開始使用 OpenHands LM:
- 從 Hugging Face 下載模型:該模型可在 Hugging Face 上獲取,並直接從那裡下載。
- 使用模型服務框架創建與 OpenAI 兼容的端點:為獲得最佳性能,建議使用 SGLang 或 vLLM 在 GPU 上部署此模型。
- 將你的 OpenHands 代理指向新模型:下載 OpenHands,並按照 使用與 OpenAI 兼容的端點 的說明進行操作。
✨ 主要特性
- 開源且可本地運行:模型開源並可在 Hugging Face 上獲取,你可以下載並在本地運行。
- 合理的模型規模:模型大小為 32B,可在單個 3090 GPU 等硬件上本地運行。
- 強大的性能表現:在軟件工程任務中表現出色,在 SWE - Bench Verified 上的驗證解決率達到 37.2%,性能可與參數多 20 倍的模型相媲美。
- 專業的微調過程:基於 Qwen Coder 2.5 Instruct 32B 進行微調,使用 OpenHands 自身在多種開源倉庫上生成的訓練數據,採用基於 RL 的框架 SWE - Gym 進行訓練。
- 大上下文窗口:具有 128K 令牌上下文窗口,適合處理大型代碼庫和長期軟件工程任務。
📚 詳細文檔
模型基礎
OpenHands LM 構建於 Qwen Coder 2.5 Instruct 32B 的基礎之上,利用其強大的編碼基礎能力。我們的微調過程具有獨特性:
- 使用 OpenHands 自身在多種開源倉庫上生成的訓練數據。
- 採用 SWE - Gym 中基於 RL 的框架,設置訓練環境,使用現有代理生成訓練數據,並在成功解決的示例上對模型進行微調。
性能評估
我們使用最新的 迭代評估協議 在 SWE - Bench Verified 基準測試 上對 OpenHands LM 進行了評估,結果令人印象深刻:
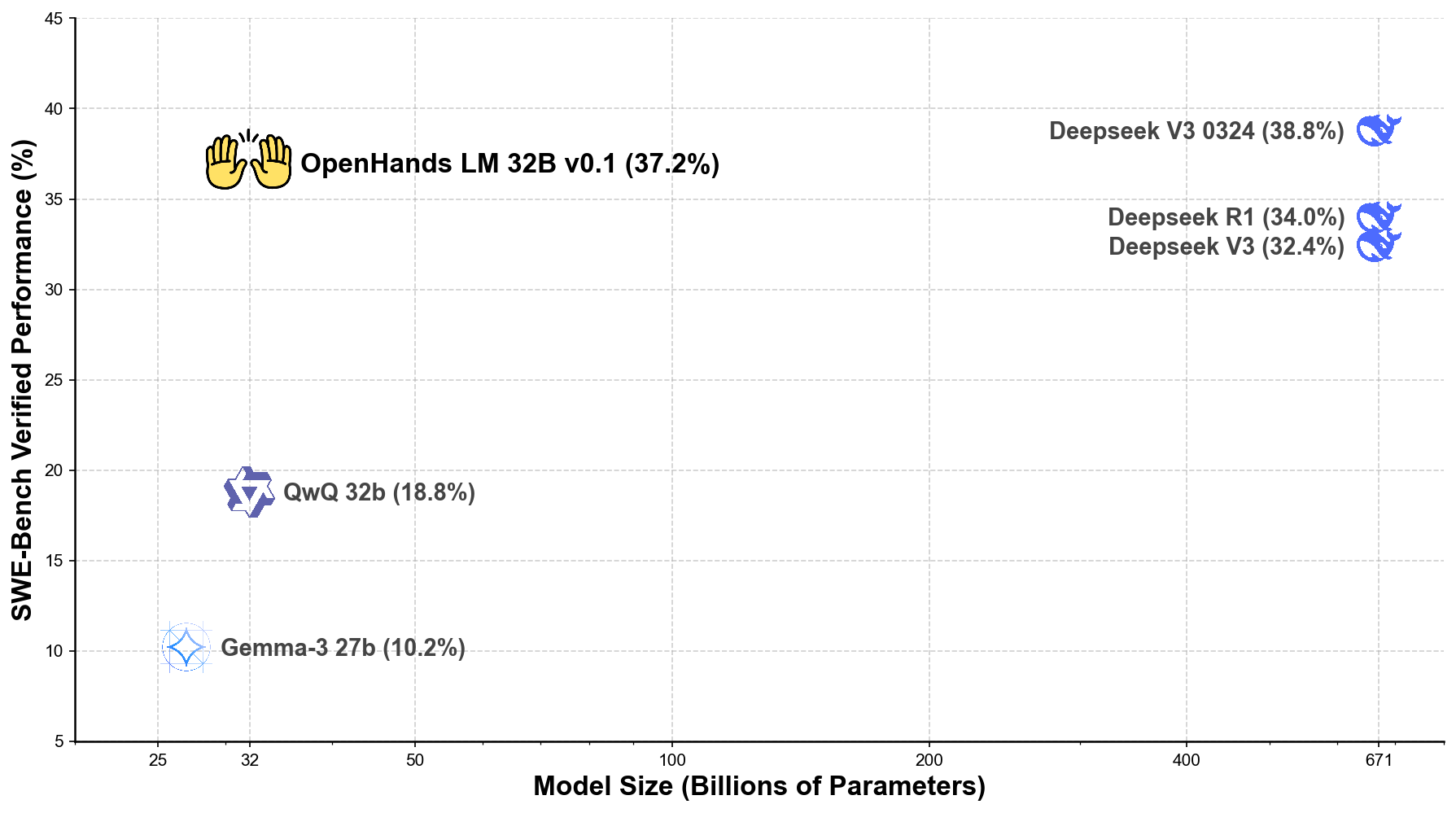
- 在 SWE - Bench Verified 上的驗證解決率達到 37.2%。
- 性能與參數多 20 倍 的模型相當,包括具有 671B 參數的 Deepseek V3 0324(38.8%)。
以下是 OpenHands LM 與其他領先開源模型的性能對比圖:
未來規劃
本次初始版本的發佈僅僅是我們旅程的開始。我們將根據社區反饋和持續的研究計劃不斷改進 OpenHands LM。
需要注意的是,該模型仍處於研究預覽階段,存在一些侷限性:
- 可能最適合解決 GitHub 問題的任務,在更多樣化的軟件工程任務中表現欠佳。
- 有時可能會生成重複步驟。
- 對量化較為敏感,在較低量化級別下可能無法發揮全部性能。
我們的下一個版本將著重解決這些侷限性。此外,我們還在開發更緊湊的模型版本(包括 7B 參數的變體),以支持計算資源有限的用戶。這些較小的模型將保留 OpenHands LM 的核心優勢,同時大幅降低硬件要求。
🔧 技術細節
AWQ 量化
由 stelterlab 使用 casper - hansen 的 AutoAWQ 在 INT4 GEMM 中完成。
基礎信息
| 屬性 |
詳情 |
| 模型類型 |
文本生成 |
| 基礎模型 |
all - hands/openhands - lm - 32b - v0.1 |
| 訓練數據 |
SWE - Gym/SWE - Gym |
🤝 加入我們的社區
我們邀請你加入 OpenHands LM 的發展之旅:
通過分享你的經驗和反饋,你將有助於塑造這個開源項目的未來。讓我們共同為未來的軟件開發創造更好的工具!我們迫不及待地想看到你使用 OpenHands LM 創造出的成果!
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

 Transformers 支持多種語言
Transformers 支持多種語言